

1. 서론
1.1 연구의 배경 및 목적
1.2 연구의 범위 및 방법
2. 노후 건축물 리모델링에 활용할 객체 분류 기술에 관한 선행연구 분석
2.1 노후 건축물 리모델링에 관한 선행연구 분석
2.2 딥러닝 기반 객체 분류 기술에 관한 선행연구 분석
3. 포인트 클라우트 데이터 기반 건축 객체 자동 분류 데이터세트 및 네트워크 구축
3.1 건축 객체 분류를 위한 세그멘테이션 데이터세트 구축
3.2 건축 객체 분류 네트워크 구축
4. 노후 건축물 리모델링을 위한 건축 객체 자동 분류 모델 개발
4.1 세그멘테이션 데이터세트 학습
4.2 포인트 클라우트 데이터 기반 건축 객체 자동 분류
5. 결론
1. 서론
1.1 연구의 배경 및 목적
우리나라는 1950년 한국전쟁 이후 피난민들을 위한 주거지가 무분별하게 지어졌다. 그리고 60년대 이후 산업화가 급속도로 진행되면서 여러 분야의 산업이 발전함과 따라 무수히 많은 건물이 지어졌다. 이렇게 지어진 건물들은 대부분 체계적인 계획을 통해 지어진 것이 아닌 건물이 지어질 때 기본이 되는 도면조차 없는 건물들이 허다하다. 현재에 와서는, 이렇게 지어진 건축물들은 노후 건축물이 되어 리모델링 또는 유지보수를 해야 하는 시기가 되었다. 이러한 리모델링은 국가 주도하에 이뤄지고 있는 도시재생사업 등을 통해 점점 많아지고 있다. 위의 과정들이 이뤄질 경우, 도면이 없는 해당 건축물은 도면 생성 등을 위한 사전 실측 및 철거 과정을 거치게 된다.
철거가 이뤄지기 전 도면 생성을 위한 실측 과정들은 현재 대부분 인력에 의존하여 진행되고 있다. 인력이 직접 투입되어 줄자, 레이저 측정기 등을 활용하여 직접 치수를 재고 벽, 기둥 등 건축 객체를 종이 그리는 작업을 진행한 후, 디지털 도면을 생성하는 프로세스로 진행되고 있다. 이러한 과정을 거쳐 생성된 도면을 활용하여 이후 구조진단, 건축계획 등을 통해 철거해야 하는 건축물의 부재, 부분을 분류하여 건축 폐기량 등을 파악한다.
한편, 4차 산업 시대를 통해 여러 스마트 기술들이 개발되었다. 이러한 기술들은 산업 전반에 활용되고 있으며, 특히 건축 분야에서는 계획 및 시공 업계에 많이 활용되고 있다. 구체적으로 도면 데이터를 학습하여 자동 인식 및 생성하는 기술, 그리고 딥러닝 기술을 활용하여 사전 학습을 통해 원하는 카테고리로 분류할 수 있는 인공지능 모델 및 네트워크가 개발되어 건축 객체를 분류하는 기술 등으로 활용되고 있다. 또한 3D 스캐너, 드론 등 스마트 기기들을 활용하여 예전에는 할 수 없었던 영역까지 업역을 넓혀가고 있다. 3D 스캐너와 드론은 사진 측량학 측면에서 많이 활용되고 있지만, 2D인 기존의 사진과는 달리 레이저를 통해 반사되어 돌아오는 포인트 클라우드들이 합쳐져서 3D 형상을 이룬다.
이러한 기술들은 현재 건축 분야에서는 특히 실내 건축 분야에서 실내의 사물 및 객체를 분류하고 자동 배치하는 등 다양하게 활용되고 있다. 4차 산업 기술들은 인력 중심이었던 산업의 패러다임을 기계 및 디지털적인 요소들로 대체하면서 업무의 효율성 측면에서 엄청난 효과를 얻고 있다. 앞서 언급한 바와 같은 실측 과정 등과 같이 인력에 의존한 단순 반복적인 업무를 이러한 기술들로 대체한다면, 시간적 여유가 생기게 되어 좀 더 창의적인 영역에 할애할 수 있을 것이다. 따라서 본 연구에서는 노후 건축물 리모델링 진행 시, 인력 중심의 비효율적인 방식을 포인트 클라우드 데이터를 활용하여 딥러닝 기반의 건축 객체 분류 기술을 개발하고자 한다.
1.2 연구의 범위 및 방법
앞서 언급한 바와 같이 건축물 실측 과정에서는 건축 도면을 생성하는 단계를 통해 철거하는 건축 객체와 남겨두어 보존하는 객체를 나누게 된다. 이를 위해 구조적인 평가단계를 거쳐야 하지만, 그전에 자동으로 건축 객체를 분류하여 자동 생성할 수 있다면 이후 건축 폐기량 산출 및 보존하려는 골조 등의 파악이 손쉬워진다. 이를 위해 딥러닝 기반 객체 분류 기술을 개발하고자 하며 그 학습 데이터수집 과정이 선행되어야 한다.
본 연구에서는 건축 객체를 벽, 기둥, 바닥 그리고 지붕으로 한정하여 분류하고자 하며 실제 건축물에 포함되지 않는 기타 분류로 추가하고자 한다. 또한 이를 위한 데이터로 한국지능정보사회진흥원인 AI-Hub에서 제공하는 포인트 클라우드 공공데이터와 실제 노후 건축물 3D 스캐닝 데이터를 활용하고자 한다.
본 연구의 방법은 다음 Figure 1과 같다.
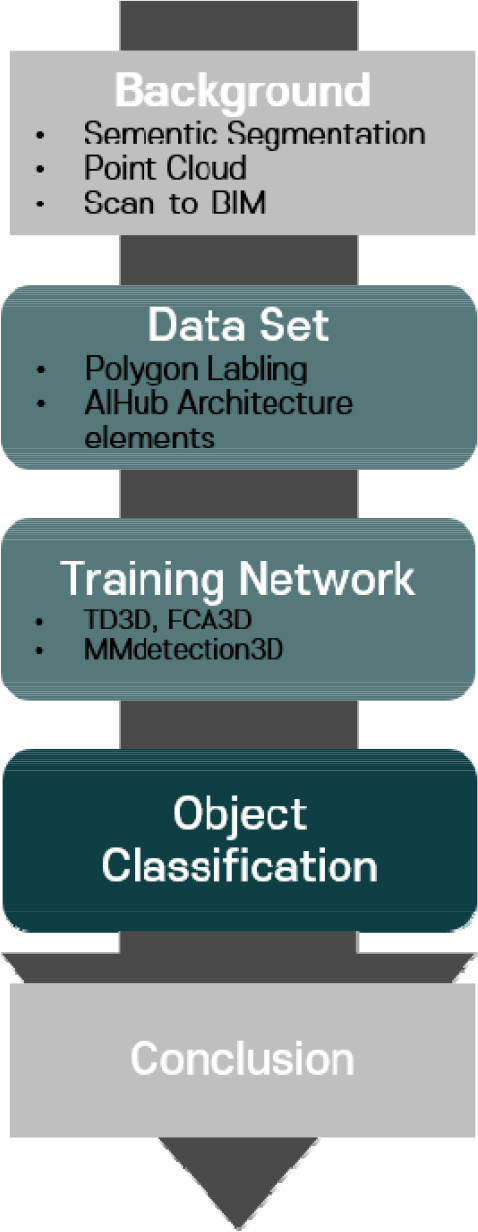
우선 본 연구에서 활용할 기술을 분석하여 현재 개발된 기술의 수준을 파악한다. 이후 본 연구의 학습 및 분류에 사용될 딥러닝 네트워크를 분석 및 선정하여 본 연구에서 활용될 부분과 본 연구에 적합한 모델로의 수정 과정이 수행되어야 한다. 이후 실제 건축물을 대상으로 도면을 통해 작성된 모델과 분류 과정을 거쳐 완성된 모델의 인스턴스 수를 비교 검증한다.
2. 노후 건축물 리모델링에 활용할 객체 분류 기술에 관한 선행연구 분석
2.1 노후 건축물 리모델링에 관한 선행연구 분석
리모델링은 건축법 제2조 제1항 제10호에서 ‘리모델링(Remodeling)이란 건축물의 노후화를 억제하거나 기능 향상 등을 위하여 대수선하거나 일부 증축하는 행위를 말한다’라고 정의하고 있다. 건축물의 라이프 사이클 동안 ‘수명 연장’이라는 의미에 있어서, 리모델링은 21세기의 지속 가능한 건축환경을 구축할 수 있는 효율적인 방안으로 건축의 중요한 카테고리라고 할 수 있다(Min & Park, 2001). 현재 리모델링, 리노베이션 등 여러 용어가 혼용되어 사용되고 있지만, 큰 범위에서 리모델링이라는 용어를 사용하고 있다.
리모델링 과정은 기획, 설계, 시공단계로 나눌 수 있으며, 특히 기획 단계는 사업수행을 위한 중요한 플랜(Plan) 작성 단계로 리모델링 사업에 있어서 건축물 각종 성능 유지와 향상을 위해 신축 건축계획과 비교하여 좀 더 면밀한 분석 방법 및 프로세스를 요구한다(Kwon & Chun, 2006).
노후 건축물 리모델링에 관한 관심이 국내에서도 높아지고 있으며 이에 따른 지침이 수립되었다. 국토교통부에서는 노후 건축물의 안전성, 에너지 효율성, 문화유산 보전 등을 위한 지침인 ‘노후 건축물 리모델링 지침’을 발표하였다. 또한 한국 건설생활환경시험연구원(Korea Conformity Laboratories, KCL)에서는 노후 건축물의 리모델링을 위한 기술적 가이드라인을 제공하고 있으며, 에너지 효율성 및 안전성을 강조하고 있다.
이러한 지침들은 건물의 기능성, 안전성 및 지속 가능성을 개선하기 위해 수립되었다. 이를 위해 도면과 실측 데이터는 리모델링 프로세스에서 중요한 역할을 한다.
현재 국내에는 약 31.3% 정도의 건축물이 도면을 보유하고 있지 않다. 이는 국가공간정보포털에서 보유하고 있는 도로명 주소 건물 데이터 수로 건축물대장에 도면이 등록된 건축물 수를 나눈 값을 백분율로 전환했을 때의 수치이다.
리모델링 시, 도면은 기존 건물의 구조, 레이아웃 및 시설물의 위치 등을 이해하는데 필수적으로 필요하다. 도면이 없을 시에는 실측을 통해 데이터 수집을 한다. 특히 건물의 현재 상태를 정확하게 이해하기 위해 현장에서의 측정 데이터 수집 과정을 거쳐야 한다.
도면의 실측 과정은 우선 레이저 거리 측정기, 카메라, 스캐너 등과 안전 장비를 준비하는 단계를 시작으로 건물의 내외부 평면을 측정한다. 이때, 건물의 크기, 구조, 벽면, 창문, 문, 계단 등과 같은 중요한 건축물의 요소를 파악한다. 이후, 세부적인 치수를 측정한다. 천장 높이, 문 폭, 창문 크기, 전기 및 배관 설비 위치 등을 측정한다. 그리고 사진 및 모든 데이터를 문서화하며, 이를 토대로 디지털 데이터를 생성하며 실시간으로 데이터를 분석하고 처리하여 정확한 결과를 얻을 수 있도록 한다.
이러한 방법의 실측기법으로는 수작업실측, 광파기 측정, 사진 실측 이렇게 3가지 방법으로 나눌 수 있는데, 이 모든 방법은 사용하는 도구만 다를 뿐 측정한 치수를 바탕으로 현장 스케치 및 기록을 통해 도면을 추출한다(Kwon et al., 2008). 근래에 들어서는 4차 산업 기술의 개발 및 발달로 3D 레이저 스캐너, 드론, 화상처리 기기 들을 활용하고자 하는 시도가 많아지고 있다(Zhou & Tuzel, 2018). 다음 Figure 2는 조감도 뷰를 탑재한 LIDAR 기기를 통해 얻을 수 있는 3D 객체 측정 도구의 제안 개요이다.
이러한 방법은 건물의 구조와 형태를 정확하고 빠르게 측정할 수 있게 하며, 건물의 외부와 내부를 높은 해상도로 촬영할 수 있게 한다. 따라서 본 연구에서는 이러한 기기 및 기술을 활용하여 보다 효율적인 방법으로의 노후 건축물 리모델링 시 실측 과정을 수행할 수 있는 기술을 개발하고자 한다.
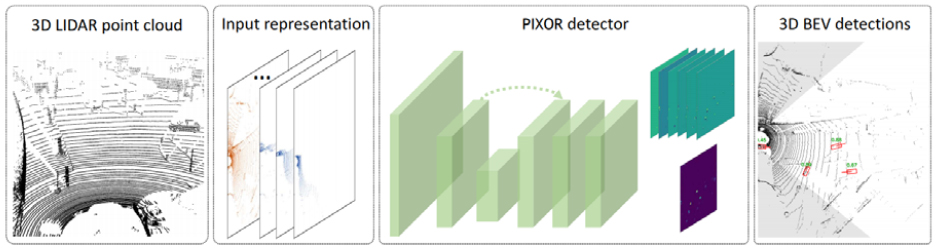
Figure 2.
Overview of the proposed 3D object detector from BEV (Bird’s Eye View) of LIDAR point cloud (Yang et al., 2018)
2.2 딥러닝 기반 객체 분류 기술에 관한 선행연구 분석
시멘틱 세그멘테이션이란 딥러닝 기반의 객체 분류 및 생성에 관한 기술로, 컴퓨터 비전 분야에서 여러 개의 픽셀 데이터를 라벨링하여 구분하는 것을 목적으로 시작되었다. 객체 인식(Object detection)과 다른 점은 객체 인식은 이미지의 특정 영역에 대해 분류 결과를 Bounding Box 형식으로 보여준다면 시멘틱 세그멘테이션은 이미지 내 모든 픽셀에 대한 분류 결과를 나타내 준다. 이를 통해 이미지 내의 각 객체와 그 위치를 정확하게 분할하여 시각적으로 이해할 수 있게 해준다.
2010년 이후, 딥러닝 기술의 발전으로 CNN (Convolution Neural Network)이 객체 인식 및 분할에 큰 역할을 하게 되었다. CNN은 딥러닝에서 주로 이미지 처리와 패턴 인식 작업을 위해 사용되는 신경망 아키텍처 중 하나이다. CNN은 공간적 정보를 활용하여 입력 데이터에서 인접한 신호들에 대한 상호연관 관계를 컨볼루션(Convolution) 필터를 적용하여 추출해내는 아키텍처이다. 이러한 필터를 여러 번 적용하면 다양한 공간적 특성을 데이터에서 추출하여 특징 지도를 만들어 낼 수 있다(Kim, 2019).
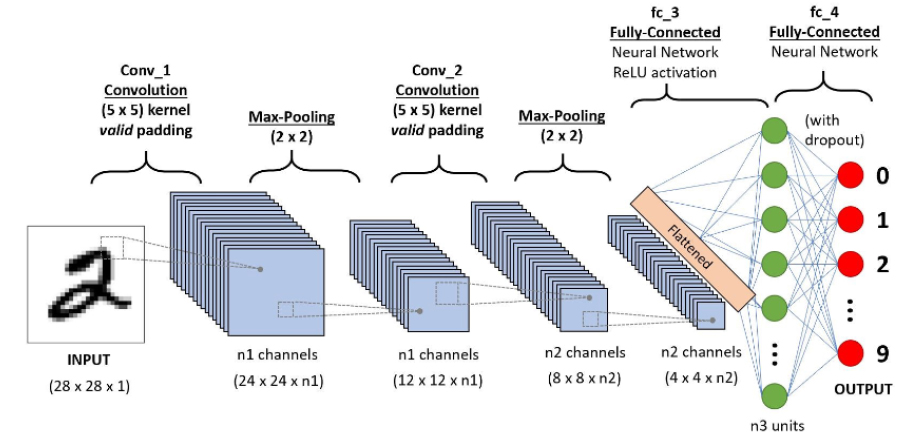
CNN은 이미지 데이터에서 특징을 추출하고 분류, 객체 탐지 또는 세그멘테이션과 같은 다양한 비전 작업을 수행하는 데 사용되었다. 또한 특징 추출과 객체 인식에 탁월한 성과를 보였으며, 이를 통해 시멘틱 세그멘테이션도 개선되었습니다.
2014년에 발표된 FCN (Fully Convolutional Network)은 CNN 아키텍처를 활용하여 이미지에서 픽셀 단위의 객체 분할을 수행하는 첫 번째 모델 중 하나이다. Long et al. (2015)의 논문에서 FCN 모델을 처음으로 제안하였으며, 이 논문은 FCN (Fully Convolutional Network)라고 불리는 아키텍처를 처음으로 제안하여 이미지의 픽셀 단위로 객체 또는 클래스를 분할하는 작업인 시맨틱 세그멘테이션에 대한 혁신적인 접근 방법을 제시하였다. 다음 Figure 4는 FCN의 구조이다.
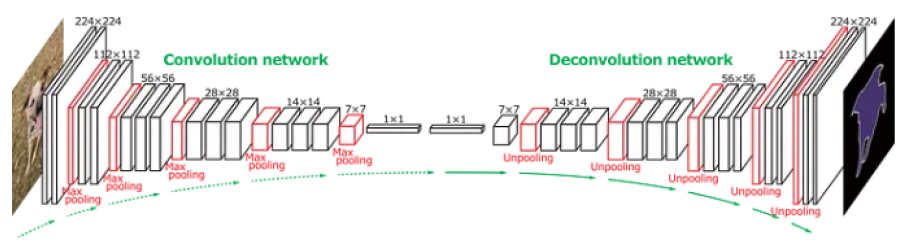
기존의 딥러닝 아키텍처는 이미지 분류를 위한 것이었으며, 출력 레이어에서 각 클래스에 대한 확률값을 제공하였다. 이로 인해 객체의 위치 정보를 잃는 문제가 있었다. 여기서 FCN은 기존의 완전 연결 레이어를 제거하고, 대신에 완전 합성곱 레이어로 대체하는 아키텍처를 도입하였다. 이로써 네트워크는 입력 이미지의 모든 픽셀에 대한 예측을 수행할 수 있게 되었다.포인트 클라우드 데이터 내에 객체를 탐색하는 방법은 기존 이미지에서 객체를 탐색하는 네트워크와 크게 다르지 않다. 기존 이미지에서 객체는 x, y좌표의 Bounding box로 라벨링(Labeling)되어 대부분 Fully Convolutional Neural Network (FCNN)를 기본으로 하는 네트워크를 사용하여 새로운 이미지에서 객체를 찾아낸다. 포인트 클라우드 데이터 내에 객체를 탐색하는 방법 또한 기본적으로 유사하다.
위에 언급한 네트워크인 FCNN는 딥러닝 기술의 발전 속도를 빠르게 한 중요한 네트워크 중 하나로, 고해상도 이미지에서 효과적으로 객체를 분할하는데 사용된다. FCNN는 기존의 합성곱 신경망을 확장하여 이미지 분할 작업에 적합하도록 설계되었다(Kang & Wang, 2014). 이 네트워크는 도로, 자율주행, 의료 영상 분석 등 시맨틱 세그멘테이션(Semantic Segmentation) 분야 및 객체의 위치와 경계를 정확히 예측하는 객체 탐지(Object detection) 그리고 자연어 처리 분야에 주요 응용되고 있다.
포인트 클라우드의 시멘틱 세그멘테이션 또한 기존 2D 이미지의 시멘틱 세그멘테이션과 크게 다르지 않다. 기존의 2D 이미지의 경우 하나의 픽셀(Pixel)마다 라벨링을 하여 학습하는 구조였다면, 3D의 경우 포인트들을 픽셀과 같이 라벨링하여 학습하는 구조이다.
포인트 클라우드를 처리하는 딥러닝 모델 중 현재 성능 측면에서 가장 대표적인 모델으로 PointNet이 있다. PointNet은 기존의 2D 이미지 처리 기술을 3D 공간으로 확장함으로써 3D 객체 분류, 분할, 인식 등의 작업을 수행하는데 매우 효과적이다(Qi et al., 2017a). PointNet은 점 또는 포인트로 표현된 3D 데이터를 입력하여 사용된다. 이 모델은 각 포인트의 특성을 학습하고 이를 통합하여 객체를 인식하거나 분할한다. 이는 입력 순서에 무관하게 동일한 결과를 생성하는 특징을 가진다.
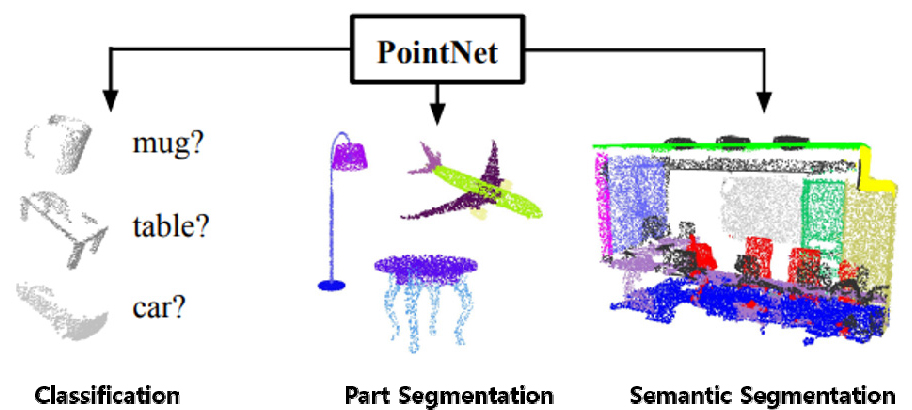
위의 Figure 5와 같은 원리인 PointNet은 2017년에 Qi 등에 의해 처음 제안되었으며 이후 성능을 향상시킨 PointNet++가 등장하였다(Qi et al., 2017b). 초기버전은 단일 포인트 클라우드를 처리하는데 중점을 두었다면 이후 개발된 PointNet++ 는 계층 구조를 통해 고해상도 포인트 클라우드를 처리하고 공간 계층적 정보를 캡처하는 성능이 향상되었다. 이들은 3D 객체를 효과적으로 분류하며 3D 객체 및 경계를 인식하는 분야에 유용하게 활용되고 있다.
3. 포인트 클라우트 데이터 기반 건축 객체 자동 분류 데이터세트 및 네트워크 구축
3.1 건축 객체 분류를 위한 세그멘테이션 데이터세트 구축
다음 Figure 6은 본 연구의 프로세스이다.
대부분의 학습 데이터는 앞서 언급한 AI-Hub에 있는 공공 데이터인 ‘실내 공간 3D 종합 데이터’를 활용하였다. 해당 데이터셋은 일반주택(아파트, 빌라 등)을 포함하여 특별 시설물인 병원, 도서관, 공장, 놀이공원 등의 건물에서 실내 공간 데이터를 기존에 시멘틱 세그멘테이션에서 널리 활용되고 있는 폴리곤(Polygon) 형식으로 라벨링 하였다. 다음 Figure 7은 원시 데이터이다.
그리고 실제 스캔한 데이터는 대구광역시 북구 복현1동 일원에서 수행되었던 ‘복현1동 피란민촌 기록화 사업’의 대상지 내에 있는 노후 건축물(주택)을 촬영한 3D 스캐닝 데이터를 활용하였으며 그 예시는 다음 Figure 8과 같다.
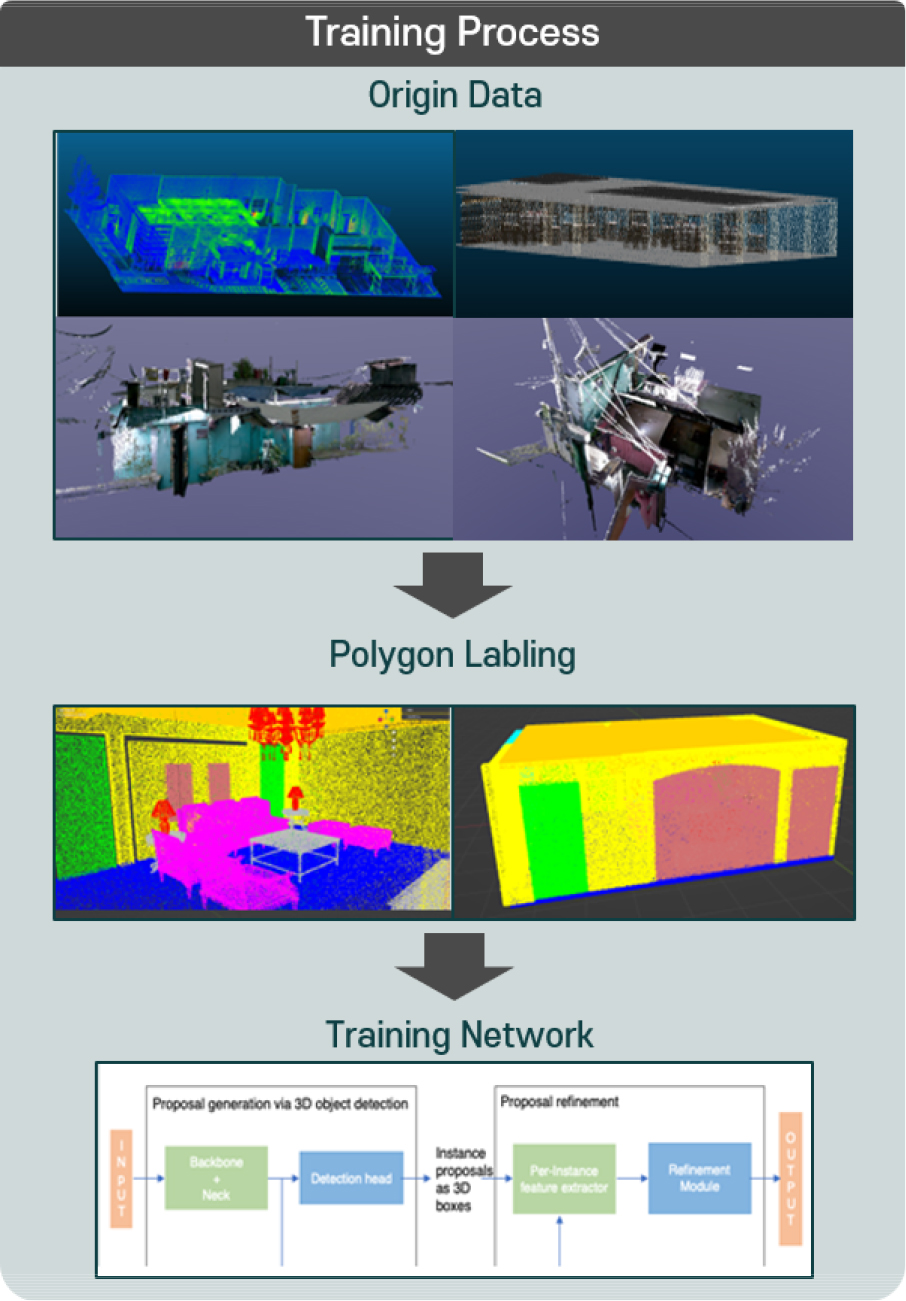


다음 Figure 9는 라벨링한 학습용 데이터이다.

3.2 건축 객체 분류 네트워크 구축
본 연구에서 활용한 네트워크는 시멘틱 세그멘테이션과 함께 객체의 구분이 되어야 하므로 인스턴스 세그멘테이션이 가능해야한다. 또한 3D 데이터들은 용량의 규모가 다른 데이터에 비해 상당히 크다. 따라서 이를 학습하기 위해서 컴퓨팅 자원의 효율이 좋은 네트워크 중 특히 최근 좋은 성능을 보여준 TD3D (Top-Down Beats Bottom-Up in 3D Instance Segmentation, Maksim Kolodiazhnyi et al.) 네트워크를 활용하였다.
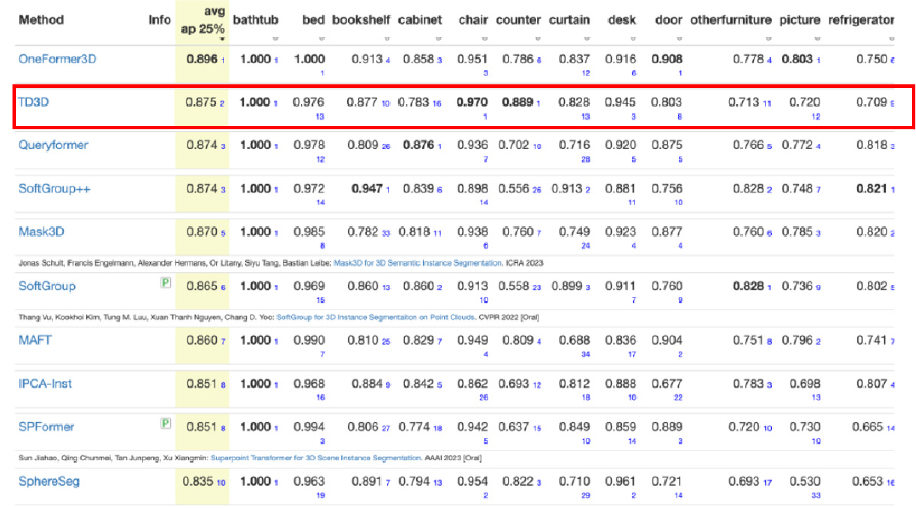
기존 3D 시멘틱 세그멘테이션은 Bottom-up 방식을 활용하여 구동하는 CNN 구조로 학습하였다. Bottom-up 방식은 경계나 질감 등 추상적인 특징을 추출한 후 점차 복잡하고 구체적인 특징을 추출해내는 과정이라고 볼 수 있다. Top-down 방식은 반대로 고수준의 정보나 특징을 파악한 뒤 저수준의 특징을 파악해 가는 방식이라고 볼 수 있다.
TD3D 네트워크는 Point cloud 데이터에서 먼저 객체를 탐지하고 객체의 경계를 찾아내는 Top-down 방식으로 학습을 진행한다. 각 객체의 라벨을 유추하고, 각 객체별로 구분하는 인스턴스 세그멘테이션을 목표로 하는 네트워크이다. 기존의 3D 시멘틱 세그멘테이션에서는 Bottom-up 방식으로 각 포인트가 어떤 클래스인지 알 수 있지만 객체로서 분류할 수 없기에 이후 클러스터링 과정을 별도로 거쳐야 한다. 그러나 TD3D 네트워크에서는 객체 탐지 네트워크인 FCAF3D를 통해 객체를 탐지하여 3D box로 된 Instance proposal을 만든 후 객체의 클래스를 추론한다(Rukhovich et al., 2021). 이러한 방식은 학습의 속도 개선뿐만 아니라 정확도 또한 향상되었다.
본 연구에서 활용한 TD3D 네트워크 내에는 여러 네트워크가 합성되어 구성되었다. 이를 연결되고 추가되면서 활용하기 위해 MMDetection3D를 활용하였다.
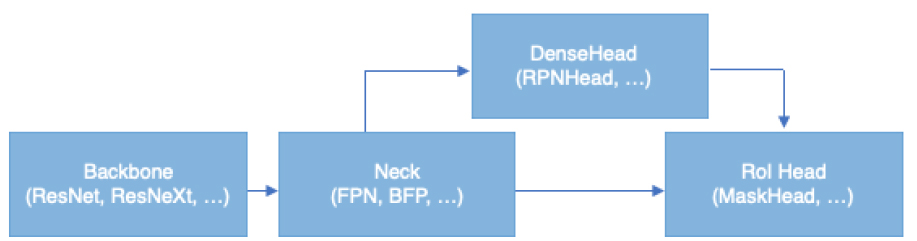
MMDetection3D는 PyTorch 기반의 Object detection, semantic segmentation, instance segmentation 등 다양한 모들을 하나의 ToolBox로 구현한 오픈 소스 라이브러리이다. 중국 칭화대학 중심의 OpenMMLab의 주도로 만들어 시작되었고 Config 기반으로 데이터 관리부터 모델의 학습, 평가까지 적용이 가능하다. MMDetection 3D는 MMDetection에서 파생되어 3D 데이터 관리, 학습, 평가를 모듈화하여 쉽게 관리하고 Backbone, Neck 등의 모듈도 쉽게 교체하여 학습할 수 있도록 지원한다. Fast R-CNN, Mask R-CNN 등 널리 쓰이는 네트워크 구조가 속해 있는 Two-state method의 구조를 살펴보면 다음 Figure 11과 같다.
4. 노후 건축물 리모델링을 위한 건축 객체 자동 분류 모델 개발
4.1 세그멘테이션 데이터세트 학습
학습은 모델의 블록 개수를 4, 5개로 학습하거나 복셀의 크기를 변경해가면서 진행하였다. 기본적으로 블록의 개수를 4개로 진행하고 복셀의 크기를 1cm, 1.5cm, 2cm로 변경하여 진행하였을 때의 학습 결과는 각각 Figure 12, 13, 14와 같다. 복셀의 크기를 각각 1cm, 1.5cm, 2cm로 변화시키며 학습한 결과 2cm로 변화시켜 진행했을 때 성능이 저하된 것을 알 수 있었다. 또한 1cm인 경우가 가장 정확도가 높은 결과물을 나타내는 것을 확인하였다. 원인은 복셀의 크기를 작게 할수록 중첩되는 셀의 크기는 줄어든다. 하지만 셀의 전체를 놓고 봤을 경우, 중첩되는 면적은 더 늘어난다. 이에 따라 학습의 정확도는 그만큼 올라갈 것으로 예상되며 그 결과 또한 마찬가지로 나타났다.
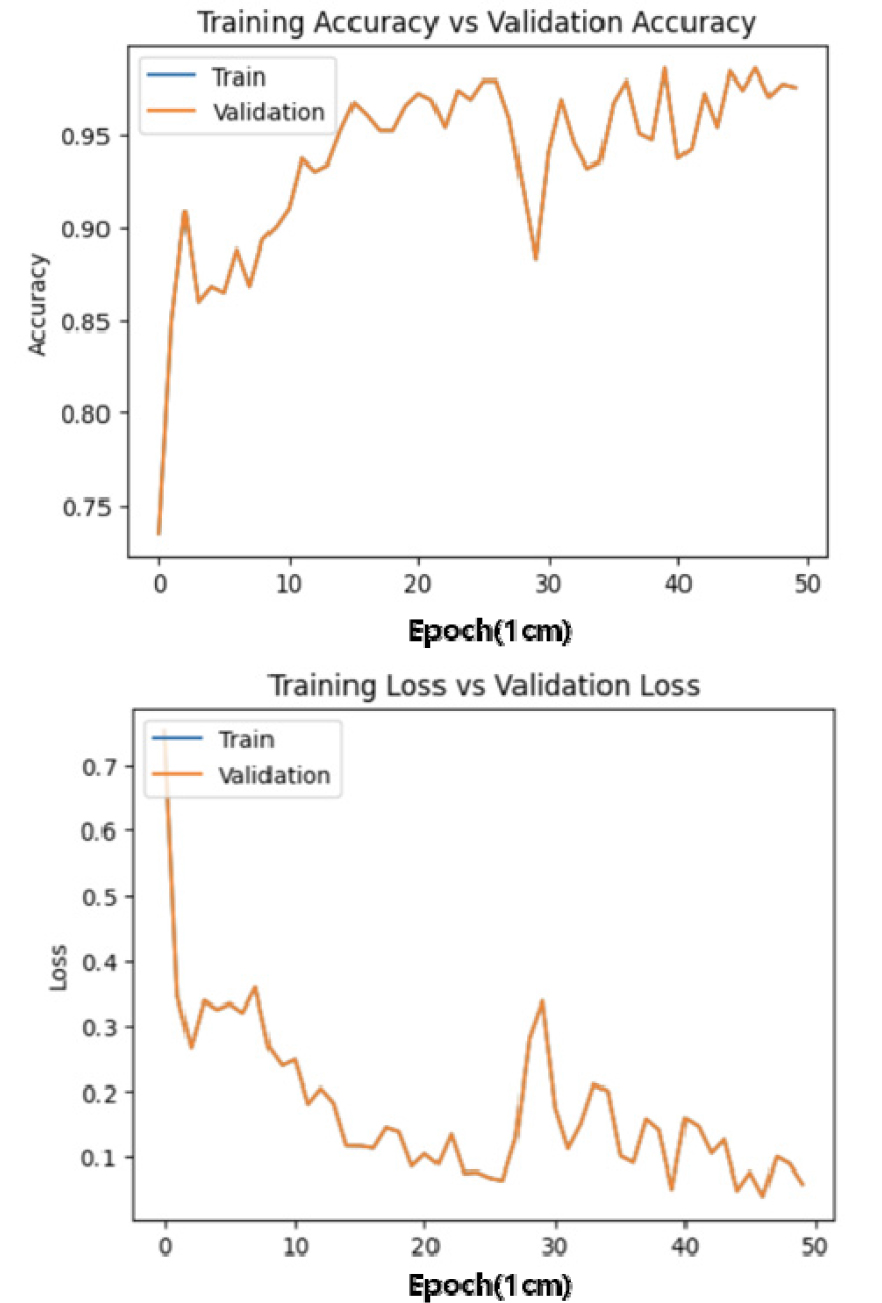
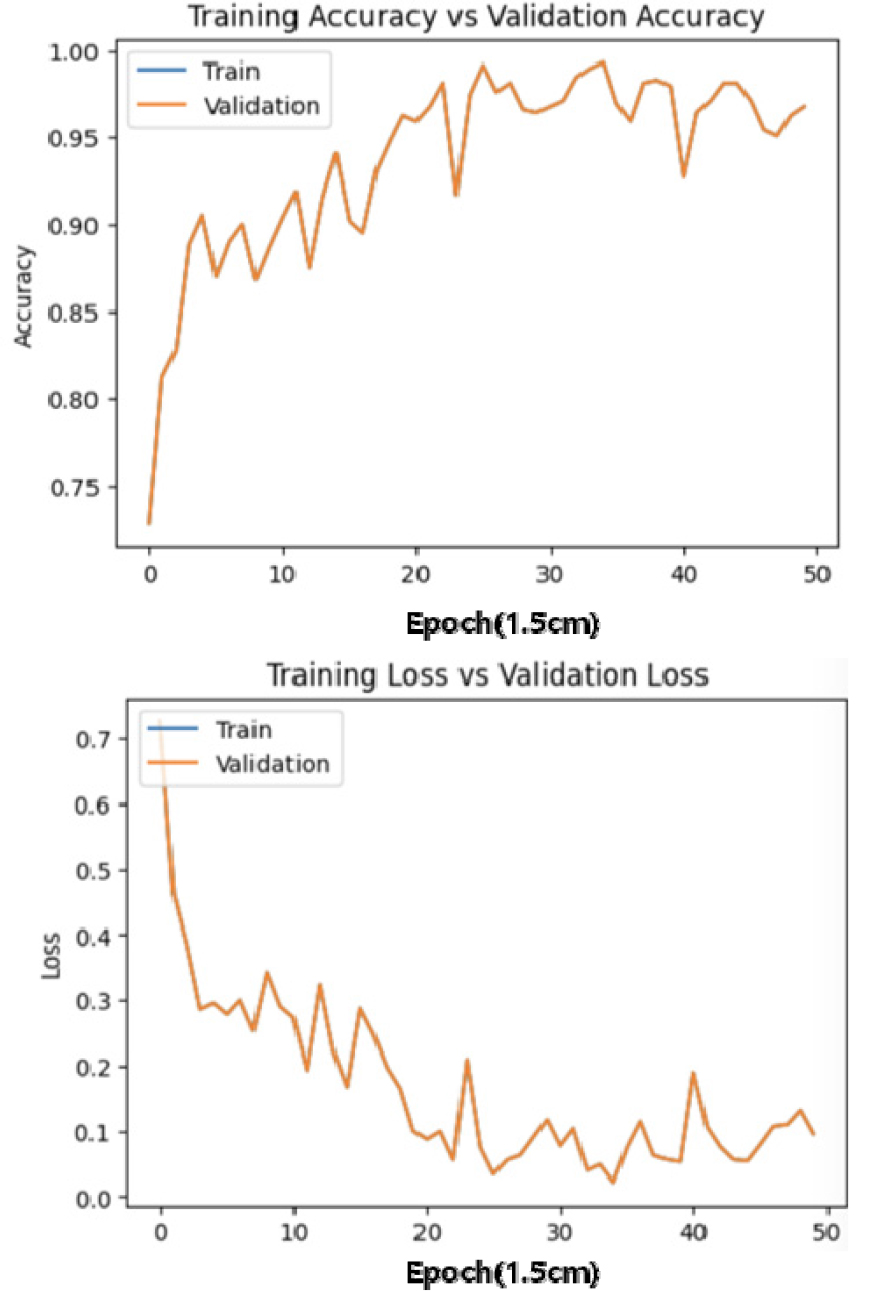
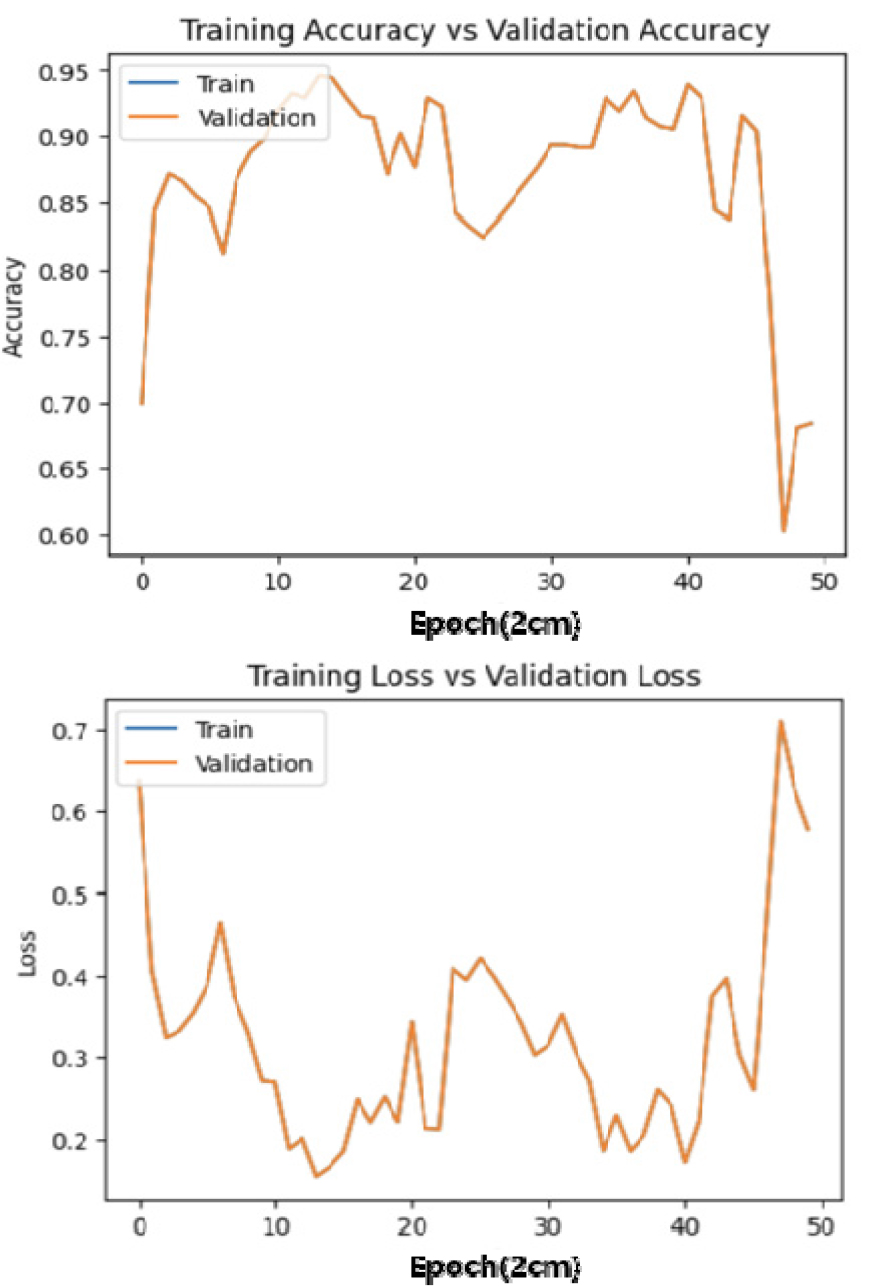
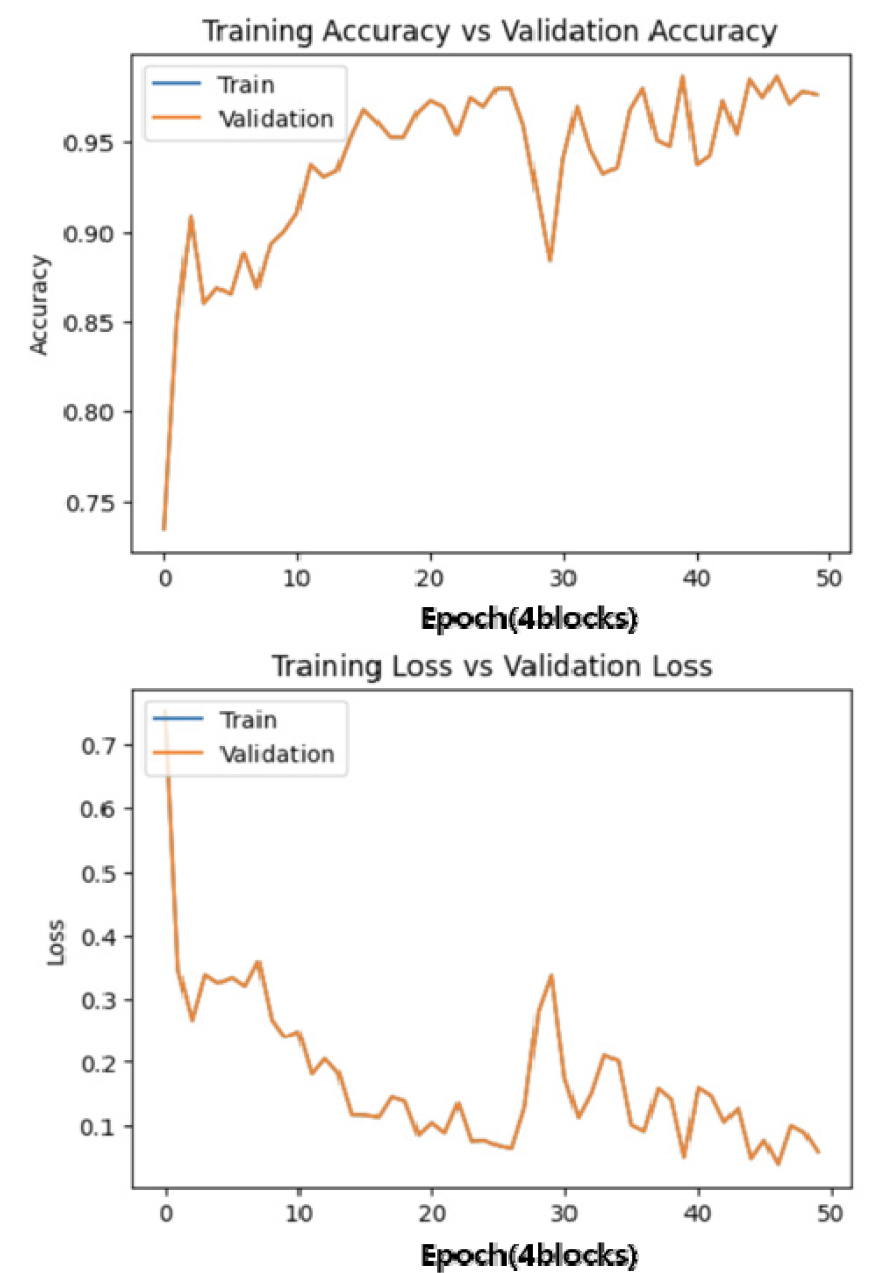
앞의 Figure 15, 16은 동일한 복셀의 크기에서 블록의 개수를 변화시키며 학습한 결과이다.
블록의 개수를 변화시켰으나 네트워크 성능에는 크게 영향을 미치지 않았으나, 학습의 속도는 블록이 4개인 경우가 더 빠른 것으로 나타났다. 이 또한 앞서 복셀의 크기를 달리했을 때와 마찬가지로 복셀의 구조로 봤을 때, 반복되어 학습되는 경우의 수가 많아지기 때문이다.
4.2 포인트 클라우트 데이터 기반 건축 객체 자동 분류
본 연구에서 활용한 TD3D 네트워크 및 학습 모델을 통해 학습 데이터로 활용된 포인트 클라우드 데이터 이외의 건축물 데이터를 통해 앞서 언급한 건축 객체 5가지(벽, 기둥, 바닥, 지붕, 기타) 중 기둥과 지붕을 제외한 3가지 객체로 분류 검증을 하였다. 본 실험 건축물에는 기둥과 지붕이 없었으며 경계가 모호하여 분류 대상에서 제외하였다. 다음 Figure 17, 18, 19, 20은 각각의 건축 객체로 분류된 결과이다.
위의 Figure 17에서 20은 각각 벽, 바닥, 기타(의자, 책상)로 분류한 이미지이다. Figure 17과 같이 벽을 분류하였을 경우, 노란색의 Bounding box의 아래쪽과 위쪽의 공간이 남는 것을 볼 수 있다. 현재 대상 건축물의 지붕과 기둥은 명확하게 구분되지 않아 인식하지는 않았지만, 데이터셋 구축 시 벽, 바닥, 지붕, 기둥, 기타의 5가지 분류로 하였기에, 지붕에 해당하는 위쪽 부분과 바닥에 해당하는 아래쪽 부분은 벽에 포함되지 않았음을 알 수 있다.

Figure 18의 경우 바닥을 분류한 결과물이다. 이때, 데이터 셋이 포인트 클라우드 데이터로 이뤄져 있기 때문에 바닥의 두께 즉 부피까지는 분류하지 못하였다. 포인트 클라우드 데이터를 추출할 시, 3D 스캐너에서 레이저를 발사하여 반사되는 시간 등을 고려하여 포인트를 추출하게 된다. 이때 바닥의 표면은 레이저 반사를 통해 포인트 추출이 가능하다. 하지만, 두께에 따른 바닥 밑면은 얻지 못하기 때문에 바닥의 표면만 얻을 수 있으며, 이로 인해 분류 결과 바닥 표면만 분류되었다.

Figure 19와 20은 건축 객체를 제외한 기타 객체를 분류한 결과이며, 그 중에서 의자와 책상을 분류한 결과이다. 현재 기타 분류에는 다양한 종류를 포함하고 있다. 각 객체를 기타의 클래스로 하여 Figure 17의 벽 클래스 중 벽 하나를 찾게 된 경우와 마찬가지로, 이들의 경우 또한 의자와 책상 각각의 기타 분류 안에 있는 객체들을 인식하여 분류하게 된 결과물이다.


5. 결론
본 연구에서는 도면 없이 지어진 무수히 많은 건축물을 대상으로 리모델링 과정에서 효율적으로 활용될 수 있는 건축 객체 인식 기술을 개발하였다. 이러한 노후 건축물들은 시간이 지남에 따라 리모델링 과정을 거치게 되는데, 이 과정에서 현재 대부분 인력에 의존하여 진행되고 있으며, 비효율적인 프로세스로 진행되고 있다.
최근 4차 산업 시대를 통해 여러 스마트기술이 개발되어 산업 전반에 활용되고 있다. 또한 3D 스캐너, 드론 등 스마트 기기들을 이용하여 실측 분야에 널리 활용되고 있다. 따라서 본 연구에서는 기존의 비효율적인 방식을 포인트 클라우드 데이터 및 스마트기술을 활용하여 딥러닝 기반의 자동 객체 분류 및 인식 기술을 개발하였다.
다양한 종류의 딥러닝 모델과 네트워크가 있지만, 본 연구에서는 복셀을 사용하는 TD3D 네트워크를 사용하였다. 복셀의 크기 및 블록의 개수를 달리하여 최적의 학습 네트워크 환경을 찾았으며 이를 통해 성능을 최적화하였다. 즉 복셀의 크기는 1cm, 블록의 개수는 4개로 하여 학습을 진행하였다. 이를 통해 실제 건축물 3D 스캐닝 데이터를 활용하여 건축 객체를 벽, 바닥, 지붕 그리고 기타 객체로 분류하였다.
분류한 결과 건축물 내의 객체인 벽, 바닥, 지붕을 분류함에 있어서는 Polygon 형식으로 라벨링을 진행하여 경계가 모호한 부분이 발생을 줄였지만, 서로 중첩되는 부분이 존재하여 객체 경계 부분 분류에서 오류가 발생하였다. 기타 분류는 건축 객체와는 경계가 맞닿아 있는 부분이 있지만, 형태적으로 다른 객체들과는 전혀 다르며 크기에서도 많은 차이를 보여 분류가 다른 객체들보다는 명확하게 됨을 확인할 수 있었다. 이를 통해 본 모델을 통해 3D 스캐닝 및 포인트 클라우드 데이터를 정합한 후 건축물 내의 객체가 아닌 기타 객체를 자동으로 분류하여 정합 과정에서 수작업으로 삭제하는 업무를 줄일 수 있음을 알 수 있었다.
또한 건축 객체를 자동 분류할 수 있어 리모델링 과정 중 철거하는 요소와 그렇지 않은 요소를 자동 구분할 수 있음을 볼 수 있었다.
본 연구에서는 학습 데이터 셋을 구축하는 과정에서 x, y, z의 최솟값과 최댓값을 활용하여 라벨링하여 Loss 공간을 최소화하였다. 본 연구에서는 건축물의 객체를 보다 효율적으로 구분해내는 기술을 개발하여, 건축물 리모델링 과정에서 인력투입을 줄이고 효과적인 시간활용을 통해 건축 계획적인 측면에서 품질의 향상을 목적으로 연구를 진행하게 되었다. 이에 본 연구를 통해 개발한 기술을 볼 때, 초기 연구 목적에 부합하게 연구를 진행한 것으로 사료된다.
이후 본 연구를 토대로 폴리곤 형태로 라벨링 된 데이터세트를 활용하여 분류된 객체를 파라메트릭 도구를 활용하여 객체를 생성하게 된다면, 생성 결과를 통해 수치 산출 결과물이 의미있게 활용될 수 있을 것으로 기대된다.
본 연구에서는 현재 실험을 통해 본 연구에서 개발한 알고리즘을 적용한 건축물은 철근 콘크리트조의 건축물이다. 철근 콘크리트조의 건축물은 역설계를 수행할 경우 다른 구조의 건축물보다는 특이사항이 적어 비교적 고려해야 할 사항이 많지 않다. 따라서 앞으로 다양한 구조에 따른 노후 건축물 리모델링 시에 맞는 알고리즘 개발이 필요할 것이다.
하지만, 이러한 결과물들을 향후 BIM (Building Information Modeling)과 연계한 연구를 통해 분류된 객체의 BIM 정보를 통해 건축물 폐기량, 철거되지 않는 건축 골조 등의 물량산출 등으로 활용되기에 충분할 것으로 보인다. 이러한 방향으로 지속적인 연구가 진행된다면 건축물 리모델링 프로세스에 고효율의 발전을 이룰 수 있을 것으로 기대된다.
