

1. 서 론
1.1 연구의 배경 및 목적
1.2 연구의 범위 및 방법
2. 연구 방법
2.1 실제 이미지 기반 데이터셋
2.2 합성 이미지 기반 데이터셋
2.3 최종 훈련용 데이터셋 구성
2.4 훈련 및 평가 방법
3. 실험 및 결과
4. 결 론
1. 서 론
1.1 연구의 배경 및 목적
최근 건설 프로젝트는 규모가 점점 더 커지고 구조가 복잡해짐에 따라, 시공 현장은 인력, 자재, 중장비와 같은 자원이 동시에 투입되고 서로 맞물려 작동하는 복합적인 공간으로 이루어져 있다. 이러한 환경 속에서 각 자원들의 실시간 상태를 정밀하게 파악하는 기술은 프로젝트의 생산성 향상, 공정 지연 방지, 안전사고 예방을 위해 중요하다. 전통적인 현장 관리 방식은 관리자의 경험과 육안 점검에 의존하는 수동적 절차가 중심이었기 때문에 정보 누락이나 판단 오류가 발생하기 쉽다는 한계가 있었다.
최근 정보통신기술의 발전은 이러한 한계를 극복하고, 데이터 기반의 자동화된 현장 모니터링을 가능하게 하고 있다. 특히 컴퓨터 비전은 이미지, 영상 데이터를 인간처럼 해석·이해하도록 만드는 분야로서, 빠르게 진화하며 다양한 산업 분야로 확산되고 있다. 이 기술을 건설 분야에 응용하면 별도의 물리적 센서를 부착하지 않고도 카메라만으로 현장을 기록·분석할 수 있다는 점에서 효율적인 모니터링 방법으로 주목받고 있다(Golparvar-Fard et al., 2009; Luo et al., 2020). 더 나아가 인공지능 기술의 급격한 발전은 이미지 분석의 수준을 비약적으로 향상시켰으며, 그중에서도 딥러닝 기반 객체 탐지 기술은 다양한 사례에 활용되고 있으며 건설 현장 모니터링 전반에 새로운 가능성을 제시하고 있다.
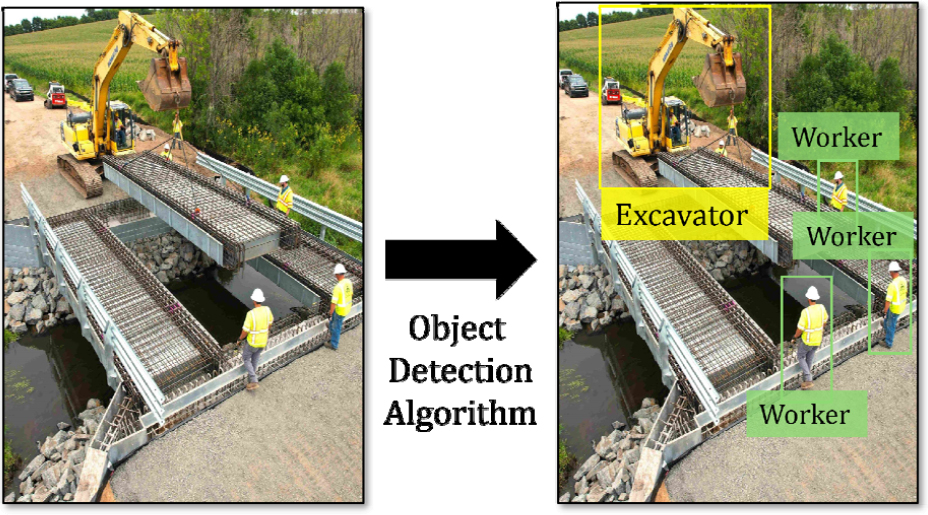
객체 탐지 기술은 이미지 내에서 특정 객체(예: 작업자, 장비 등)의 위치와 종류를 식별하는 기술(Figure 1)이다. 최근 건설 현장 모니터링에 있어 이러한 기술이 단순히 객체를 탐지하는 것에 그치지 않고 안전 관리, 건설 장비 모니터링, 구조물 품질 점검 등 다양한 측면에서 응용되고 있다. 그 예로, 딥러닝 기반 객체 탐지 모델을 활용하여 작업자의 보호구를 탐지하고, 보호구가 탐지되지 않는 작업자를 식별하는 연구(Cheng et al., 2021; Fang et al., 2018; Kumar et al., 2022; Wang et al., 2020)가 수행되어 왔다. 또한, 작업자 및 장비를 탐지해 충돌 위험을 사전에 식별·방지하는 연구도 수행된 바 있다. 예를 들어, 딥러닝 기반 객체 탐지를 통해 얻어진 장비와 작업자의 bounding box를 지면에 투영한 뒤, 장비 주변에 원형 또는 반타원형의 위험 영역을 정의하고, 해당 영역에 진입하는 작업자를 충돌 위험이 높은 상태로 판정하는 연구가 발표된 바 있다(Seong et al., 2023). 또한, 딥러닝 기반 객체 탐지를 수행한 결과로 산출된 bounding box의 이동 궤적을 추적하여 경로를 예측하고 충돌을 방지하는 연구(Son and Kim, 2021)가 수행된 바 있으며, 이 외에도 건설 장비 탐지 모델의 성능 향상을 목표로 한 연구(Eum et al., 2025), 객체 탐지 모델을 활용하여 콘크리트 구조물의 균열을 탐지하여 구조물 상태를 모니터링하는 연구(Deng et al., 2021; Hacıefendioğlu and Başağa, 2022; Ribeiro et al., 2024; Park et al., 2020; Wu et al., 2022) 등이 보고된 바 있다.
그러나 이러한 딥러닝 기반 모델의 성능은 본질적으로 훈련 데이터의 규모와 다양성에 크게 의존한다(Shorten and Khoshgoftaar, 2019). 다양한 환경과 상황 속에서 객체를 안정적으로 탐지하기 위해서는, 조명 변화, 배경, 객체의 위치·방향 등 여러 조건을 반영한 방대한 훈련 데이터가 필요하다. 하지만 실제 건설 현장은 야외라는 특성상 조명이 수시로 변하고, 작업자, 장비, 구조물, 먼지 등이 혼재하여 객체가 자주 가려지는 등 동적이고 복잡한 환경이 조성된다. 이러한 이유로 모든 조건을 포괄하는 데이터를 확보하는 것은 과도한 이미지 수집·레이블링을 요구하는 노동집약적 과정이 될 수 있다.
이와 같은 문제를 완화하기 위해 ACID (Xiao and Kang, 2021; Xiao et al., 2022), MOCS (Xuehui et al., 2021) 등 건설 현장 이미지로 이루어진 대규모 공개 데이터셋이 구축되어 왔다. 그러나 이런 공개 데이터셋만으로는 여전히 한계가 존재할 수 있다. 우선, 공개 데이터셋 내에서도 특정 객체의 수가 비교적 충분하지 않을 수 있고, 사용자가 훈련된 모델을 적용할 현장에서는 동일한 건설 장비 종류라 하더라도 세부 유형이나 제조사에 따라 외형이 크게 다를 수 있다(Figure 2). 더 나아가 앞서 언급한 건설 현장의 동적 특성까지 고려하면, 이러한 공개 데이터셋만으로는 사용자가 원하는 현장의 구체적 상황이나 특정 장비의 특성을 충분히 반영하기 어려울 수 있고, 결국 추가적인 데이터 수집과 레이블링 과정이 요구될 수 있다.

이러한 문제를 효과적으로 해결하기 위해 이 연구는 생성형 AI를 활용하여 건설 장비 이미지를 생성하는 방안을 검토하고자 한다. 최근 주목받고 있는 생성형 인공지능 모델 중 하나인 Text-to-Image 모델은 사용자가 입력한 텍스트 요청에 따라 다양한 조건을 반영한 합성 이미지를 자동으로 생성할 수 있는 모델로, 최근 빠르게 발전하고 있다. 대표적인 사례로는 DALL·E (Ramesh et al., 2021)와 Imagen (Saharia et al., 2022)이 보고된 바 있다. 이를 건설 분야에 적용하면 실제 현장에 나가지 않고도 여러 상황이나 조건을 반영한 이미지를 생성할 수 있어, 이미지 데이터의 양과 다양성을 효과적으로 보충할 수 있을 것으로 기대된다. 따라서 이 연구는 Text-to-Image 모델로 생성한 건설 장비 이미지를 활용하여 객체 탐지 모델을 훈련시킨 뒤 성능 변화를 실험적으로 확인하고, 건설 현장 이미지 데이터 보충에 있어 그 활용 가능성을 검토하고자 한다.
1.2 연구의 범위 및 방법
이 연구는 딥러닝 기반 객체 탐지 기술을 건설 현장에 응용하는 방안 자체를 다루기보다는, 이 기술을 1.1절에서 제시한 다양한 응용 분야에 활용할 때 학습에 필요한 이미지 데이터가 부족할 수 있고, 데이터를 생성하는 과정이 노동집약적일 수 있다는 점에 주목하였다. 그렇기에 이 연구는 Text-to-Image 모델로 생성한 합성 이미지가 실제 이미지 기반 데이터셋에서 부족한 이미지를 보완하거나 실제 이미지를 대체할 수 있는지 가능성을 검토하는데 초점을 두었다. 구체적으로, 합성 이미지를 실제 이미지 기반 데이터셋에 추가했을 때의 효과와 합성 이미지만으로 학습했을 때의 성능 등을 분석하였다. 이를 위해 공개 데이터셋인 ACID와 MOCS를 활용하여 실제 이미지 기반 데이터셋을 구성하였고, OpenAI의 ChatGPT (OpenAI, 2023)를 사용하여 합성 이미지를 생성하였다. 이후 (1) 실제 이미지 단독, (2) 합성 이미지 단독, (3) 실제·합성 이미지를 결합 세 가지 유형의 데이터셋을 마련하여 Ultralytics의 YOLO11n (Jocher and Qiu, 2024) 객체 탐지 모델을 훈련시키고 성능을 평가·비교하였다. 객체 탐지 모델의 탐지 대상은 건설 현장의 대표적인 중장비 중 하나인 롤러와 도저로 한정하였다.
2. 연구 방법
2.1 실제 이미지 기반 데이터셋
2.1.1 롤러, 도저 데이터 추출
이 연구에서는 롤러와 도저에 한하여 성능을 검토하기 위해, ACID와 MOCS에서 해당 클래스가 포함된 이미지만을 추출하였으며, 추출 과정은 다음과 같다.
1.롤러, 도저 클래스 중 하나라도 포함되어 있는 경우 에만 해당 이미지를 추출하였다.
2.추출된 이미지에서 롤러, 도저 이외 클래스의 라벨은 모두 제거하였다.
이 과정을 거쳐 ACID와 MOCS의 원본 데이터셋으로부터 롤러, 도저에 한정된 데이터셋을 구성하였고, 그 규모는 Table 1과 같다.
Table 1.
Dataset configuration after extracting roller and dozer
| Image source | Total images | Class |
Image count |
Instance count |
| ACID | 2,063 | Roller | 1,098 | 1,200 |
| Dozer | 1,017 | 1,114 | ||
| MOCS | 1,611 | Roller | 872 | 1,015 |
| Dozer | 1,025 | 1,166 |
2.1.2 객체 크기 기반 데이터 전처리
ACID와 MOCS 데이터셋에는 Figure 3(a)와 같이 크기가 작은 객체가 다수 포함되어 있었으며, 이러한 객체는 육안으로도 해당 장비의 특징을 명확히 식별하기 힘들었다. 이 연구에서는 객체 탐지 모델의 입력 이미지 크기로 YOLO11n 기본 입력 이미지 크기인 640x640 pixel을 적용하였는데, 원본 이미지가 이 크기로 변환될 때, 객체의 모습이 더욱 왜곡되거나 흐릿해질 수 있다고 판단하였고, 이에 따라 모델의 훈련뿐 아니라 검증과 평가 단계에서도 작은 객체로 인해 왜곡된 결과가 발생할 가능성이 있다고 판단하였다. 따라서 전체 이미지 면적 대비 5%를 최소 객체 크기 기준으로 설정하였고, 이보다 작은 객체가 포함된 이미지는 모두 제거하였다. 그 결과, MOCS 데이터셋에서는 977장, ACID 데이터셋에서는 361장이 제외되었으며, 이러한 과정 이후의 남은 이미지의 샘플은 Figure 3(b)에 제시하였으며, 데이터셋 규모는 Table 2에 제시하였다.

Table 2.
Dataset configuration after removing objects smaller than 5%
| Image source | Total Images | Class | Instance Count |
| ACID | 1,702 | Roller | 899 |
| Dozer | 868 | ||
| MOCS | 634 | Roller | 263 |
| Dozer | 386 |
2.1.3 Train, validation, test 데이터 분할
앞선 과정들을 거쳐 구성한 ACID와 MOCS의 데이터셋을 훈련, 검증, 평가용으로 각각 70%, 15%, 15% 비율로 분할하였다(Table 3). 이후 두 데이터셋에서 검증용으로 분할한 데이터셋을 합치고, 평가용으로 분할한 데이터셋을 합쳐 최종 검증용, 평가용 데이터셋을 구성하였다(Table 4). 이렇게 마련한 최종 검증용, 평가용 데이터셋은 모든 검증 및 평가 과정에서 공통으로 사용하였으며, 훈련에 있어서는 훈련용으로 분할한 이미지만을 활용하여 검증용 및 평가용 데이터셋과 명확히 분리하였다. 검증 및 평가용 데이터셋에 합성 이미지를 포함하지 않고 ACID와 MOCS의 실제 이미지로만 구성한 것은, 이 연구의 목적이 ChatGPT 기반 합성 이미지가 실제 이미지 데이터 부족을 보완할 수 있는지를 실험하는 데 있으므로, 검증과 평가 단계에서는 실제 현장 이미지를 활용하는 것이 보다 적절하다고 판단했기 때문이다.
Table 3.
Data composition by train, validation, test split
Table 4.
Configuration of validation and test sets
| Image source |
Train/Test/ Valid |
Total images | Class |
Instance count |
|
ACID, MOCS | Valid | 350 | Roller | 171 |
| Dozer | 190 | |||
| Test | 350 | Roller | 186 | |
| Dozer | l172 |
2.2 합성 이미지 기반 데이터셋
합성 이미지는 ChatGPT-4o mini 모델을 활용하여 생성하였다. 초기에는 합성 이미지를 생성하는 과정에서 레이블링 자동화를 함께 시도하였다. 이미지 생성과 함께 이미지에서 장비에 해당하는 영역의 bounding box 좌표를 요청하였으나, ChatGPT가 출력한 좌표는 부정확하여 최종적으로는 연구자가 직접 레이블링을 수행하였다. 한편, 이미지 생성에 있어서는 시점, 장비의 색상, 장비의 개수 등 다양한 조건의 이미지를 프롬프트 입력만으로 반영할 수 있었다. 최초에는 텍스트만으로 장비 이미지 생성을 요청하였으나, 도저 이미지 생성을 요청하였는데 로더 이미지를 생성하는 등 텍스트 설명만으로는 특정 장비 이미지를 올바르게 생성하지 못하는 사례가 발생하였다. 이를 보완하기 위해, ChatGPT가 장비의 특징을 명확히 이해할 수 있도록 해당 장비의 외형이 뚜렷하게 나타나는 실제 이미지를 롤러, 도저 각각 4장씩 참조자료로 제공하였다. Figure 4는 참조자료로 활용한 이미지와 이를 기반으로 생성한 합성 이미지를 보여준다. Figure 4(a)는 도저에 대해 제공한 참조 이미지이며, Figure 4(b)는 이를 바탕으로 생성한 합성 이미지이다. 이후 Figure 4(b)와 같이 생성된 이미지를 바탕으로 객체와의 거리를 멀리한 이미지를 생성해 달라는 요청을 하였으며, 그 결과는 Figure 5(a)와 같다. 이어서 시점을 정면, 측면, 후면으로 변경해 달라는 요청을 하였고, 그 결과는 Figure 5(b)에 제시하였다. 또한 장비의 색상을 변경하도록 요청한 결과는 Figure 5(c)에 제시하였으며, 장비의 수량을 변경해 달라 요청한 결과는 Figure 5(d)에 제시하였다. 이러한 방식으로 순차적인 요청을 통해 다양한 합성 이미지를 생성하였다.


앞서 언급한 요청 외에도, 실제 건설 현장에서는 먼지를 비롯한 다양한 환경적 요인이 빈번하게 발생하기에, 이를 반영하기 위해 ChatGPT에 먼지가 날리는 효과 등 환경적 요인을 추가하도록 요청하였으며, 그 결과는 Figure 6에 제시하였다. Figure 6(a)는 먼지가 날리는 현장 배경을 요청한 결과이고, Figure 6(b)는 Figure 6(a)를 토대로 더욱 많은 먼지를 요청한 결과이다. 이러한 요청 사항들을 반복적으로 적용하여 합성 이미지들을 생성하였으며, 롤러, 도저 모두 같은 방식으로 생성하였고 생성된 롤러 이미지 샘플은 Figure 7에 제시하였다. 최종적으로 생성한 데이터셋의 규모는 Table 5에 제시하였다.


Table 5.
Configuration of generated synthetic data
| Image source | Total images | Class | Instance count |
| ChatGPT | 988 | Roller | 876 |
| Dozer | 929 |
2.3 최종 훈련용 데이터셋 구성
이 연구에서는 2.1절, 2.2절의 과정을 통해 만들어진 데이터들을 조합하여 최종적으로 Table 6와 같이 7가지 데이터셋을 구성하여 실험을 진행하였다. 각 데이터셋은 1.3절에서 언급한 것과 같이 (1) 합성 이미지 단독 (2) 실제 이미지 단독 (3) 실제·합성 이미지를 결합한 데이터셋으로 구분하였다. 또한, 각 데이터셋을 편하게 구분하여 표현하기 위해 약칭을 정의하였으며, 이는 Table 6의 Dataset Notation 열에 정리하였다. 최종적으로 데이터셋을 Table 6와 같이 구성한 목적은 (1)과 (2)를 비교하여 실제 이미지 기반으로 훈련한 모델과 대비했을 때 합성 이미지만으로 훈련한 모델의 성능을 검토하고, (2)와 (3)을 비교하여 실제 이미지 기반 데이터셋에 합성 이미지를 추가했을 때의 효과를 분석하기 위함이다. 이를 통해 ChatGPT로 생성한 합성 이미지가 실제 이미지를 대체하거나, 실제 이미지 기반 데이터셋을 보완할 수 있는 가능성을 평가하고자 하였다.
Table 6.
Final configuration of datasets
2.4 훈련 및 평가 방법
이 연구는 COCO 데이터셋(Lin et al., 2014)으로 사전 학습된 YOLO11n 모델을 기반으로 Ultralytics 라이브러리를 이용하여 모든 데이터셋에 대해 동일한 하이퍼파라미터로 훈련을 진행하였다. 훈련은 총 300 epochs, 입력 영상 크기 640×640 pixel로 수행하였다. 100 epochs 동안 검증용 데이터셋에 대해 mAP (mean Average Precision)이 개선되지 않으면 훈련을 조기 종료하였으며, 최종적으로 성능 지표 중 mAP가 가장 높은 모델을 평가에 사용하였다. 평가 지표로는 precision, recall, mAP50, mAP50-95를 사용하였다. 객체 탐지 모델의 성능 평가는 일반적으로 precision과 recall을 기반으로 이루어진다(Padilla et al., 2020). precision은 모델이 탐지한 결과 중 정확하게 탐지한 결과의 비율을 나타내며, 예측의 정밀도를 확인할 수 있다. 반면 recall은 실제 존재하는 모든 객체 중 모델이 올바르게 탐지한 객체의 비율을 의미하며, 모델이 얼마나 누락 없이 탐지하는지를 나타낸다. 모델이 특정 객체를 탐지했을 때의 confidence score는 해당 탐지가 올바를 것이라는 모델의 확신 정도를 의미하며, 이 값의 임계값을 어떻게 설정하느냐에 따라 precision과 recall은 상충 관계를 가진다. 이러한 특성을 종합적으로 검토하기 위해서, 다양한 confidence score 임계값을 변화시키면서 precision-recall 곡선을 작성하고 그 면적을 계산한 값인 AP (Average Precision)를 평가 지표로서 사용한다. 이때 mAP는 각 클래스별 AP를 평균한 값으로, 모델의 전반적인 성능을 평가하는 지표이다. 이 연구에서 사용한 mAP50은 예측된 bounding box와 정답 bounding box 간의 겹침 정도를 나타내는 IoU (Intersection over Union)가 50% 이상일 때를 정확한 탐지로 인정하여 계산한 mAP이며, mAP50-95는 정확한 탐지로 인정하는 IoU를 50%에서 95%까지 5% 간격으로 변화시키며 산출한 mAP의 평균값으로, 보다 엄격한 성능 지표로 볼 수 있다.
3. 실험 및 결과
2.4절의 훈련 방법으로 객체 탐지 모델들을 훈련 시켰고, 각 모델의 성능 평가 결과는 Table 7과 같다. 편의상, 3절에서는 각 모델을 Table 7의 Dataset Notation 열에 해당하는 각 데이터셋의 약칭(예: AC, MO, AC+GPT 등)으로 통칭한다. 평가는 롤러와 도저 클래스 별로 수행하였으며, 두 클래스의 평균 성능은 All 항목에 제시하였다. 예를 들어, 표에서 롤러와 도저에 제시된 mAP50 및 mAP50-95 값은 해당 클래스의 AP을 의미하며, 이를 평균한 mAP은 All 항목에 제시하였다. 또한 precision과 recall은 confidence score 임계값 변화에 따라 달라지므로, 두 지표의 균형을 가장 잘 반영하는 F1 score (precision과 recall의 조화 평균)이 최대가 되는 지점의 값을 대표 성능으로서 표기하였다.
Table 7.
Training results
Table 7을 살펴보면, 합성 이미지만으로 훈련하였을 때가 실제 이미지만으로 훈련한 것에 비해 mAP50과 mAP50-95 모두에서 낮은 성능을 보였다. 그러나 실제 이미지에 합성 이미지를 추가하였을 때는 실제 이미지만으로 훈련한 것에 비해 대부분의 지표에 개선이 있었으며 그 증감률은 Table 8에 제시하였다. 구체적으로는 AC 대비 AC+GPT에서는 mAP50이 0.61%p, mAP50- 95가 2.31%p 증가하였고, MO 대비 MO+GPT에서는 각각 3.75%p, 9.47%p 증가하였다. 또한 AC+MO 대비 AC+MO+GPT에서도 0.41%p, 1.00%p 증가한 것이 확인되었다. 이처럼 합성 이미지를 추가했을 때 전반적으로 탐지 정확도가 개선되었으며 특히 데이터 규모가 가장 작은 MO에서 성능 개선 효과가 가장 높았고, 데이터 규모가 가장 큰 AC+MO에서는 상대적으로 개선 효과가 낮게 나타났다. precision과 recall의 가장 큰 변화 역시 모두 MO와 MO+GPT의 비교에서 나타났다. 롤러 클래스에서 precision이 +17.68%p로 가장 크게 증가하였으며, 도저 클래스에서 recall이 +8.43%p로 가장 크게 나타났다. Figure 8과 Figure 9는 이러한 precision과 recall이 개선된 경우를 보이고 있다. Figure 8과 Figure 9는 모두 confidence score의 임계값을 0.3으로 설정하여 탐지하였을 때의 결과이다. Figure 8은 MO와 MO+GPT를 비교했을 때 롤러에 대한 precision이 상승된 경우를 보여준다. MO의 탐지 결과인 Figure 8(a)에서는 덤프 트럭이 롤러로 잘못 탐지되었으나, MO+GPT의 탐지 결과인 Figure 8(b)에서는 덤프 트럭에 대한 잘못된 탐지가 일어나지 않았다. 또한, Figure 9는 MO, MO+GPT 간의 비교에서 도저의 recall이 상승된 경우를 보여준다. MO 모델의 탐지 결과(Figure 9(a))에서는 도저가 탐지되지 않았으나, MO+GPT 모델의 탐지 결과(Figure 9(b))에서는 도저가 탐지된 것을 확인할 수 있었다.
Table 8.
Increase rates in evaluation metrics


Table 8을 살펴보았을 때, AC+MO와 AC+MO+GPT의 차이는 비교적 작았으며, 롤러에 대해 precision이 1.01%p 만큼 하락하였고, 도저에 대해서는 precision이 0.31%p 만큼 상승하였으며, recall은 롤러, 도저 모두에서 각각 1.34%p, 0.41%p 만큼의 상승이 있었다. Figure 10의 탐지 결과에서는 두 모델의 차이가 관찰되었다. 실제 이미지는 롤러 2대가 겹쳐 있는 이미지이며 AC+MO의 탐지 결과인 Figure 10(a)에서는 이를 하나의 bounding box로 묶어 탐지하였으며, 도저로 잘못 탐지된 것을 확인할 수 있었다. AC+MO+GPT의 탐지 결과(Figure 10(b))에서는 도저로 잘못 탐지 하진 않았으나 롤러를 3대로 분리하여 탐지한 것을 확인할 수 있었다. 두 모델 모두 완전히 정확한 결과는 아니었지만, AC+MO+GPT는 두 롤러의 영역을 분리하여 탐지하였고, 도저로 잘못 탐지하지 않았다는 점에서 precision과 recall 측면에서 의의가 있을 수 있다. Figure 10(a)에서는 탐지하지 못한 롤러 2대를 Figure 10(b)에서는 탐지하였으므로 롤러의 recall이 상승하는 경우로 볼 수 있고, Figure 10(a)에서는 롤러를 도저로 잘못 탐지하였고 Figure 10(b)에서는 도저로 잘못 탐지하지 않았기에 도저에 대해 precision이 상승하는 경우로 볼 수 있다. Figure 11과 같이 AC+MO에서는 잘못된 탐지가 발생하지 않았지만, AC+MO+GPT에서 잘못된 탐지가 발생한 경우도 존재하였다. AC+MO의 결과인 Figure 11(a)에서는 우측의 트럭에 대해 롤러로 잘못 탐지하지 않았지만, AC+MO+GPT의 결과인 Figure 11(b)에서는 우측의 트럭을 롤러로 잘못 탐지하여 롤러의 precision 하락에 영향을 미칠 수 있는 경우로 해석될 수 있다.


Figure 8, Figure 9, Figure 10을 통해, 합성 이미지를 추가하였을 때 precision과 recall이 상승한 이유에 해당하는 결과들을 살펴보았으며, Figure 11에서는 일부 잘못된 탐지로 인해 precision이 하락할 수 있는 경우도 살펴보았다. 그러나 전반적으로 합성 이미지를 추가했을 때 대부분의 성능 지표가 개선되었으며, 이는 합성 이미지를 추가하였을 때 모델이 객체를 더 정확하게 탐지하고, 실제 객체 중 더 많은 객체를 탐지할 수 있는 가능성을 보여준다. 또한, Figure 10의 경우에서, 실제 이미지 기반 데이터셋의 훈련용 데이터에는 장비가 두 대 이상 겹쳐 있는 이미지가 거의 존재하지 않았으나, 합성 이미지 기반 데이터셋에는 이러한 이미지가 다수 포함되어 있었다(Figure 12). 이러한 점을 고려할 때, 합성 이미지가 실제 데이터셋에서 부족한 특정 조건(예: 장비가 겹쳐져 있는 상황)에 대해서 훈련에 일정 부분 기여했을 것으로 보인다.

4. 결 론
이 연구에서는 건설 현장의 부족한 이미지 데이터를 보완하기 위해 Text-to-Image 모델을 활용하여 이미지를 생성하였고, 그 효과를 실험적으로 검증하였다. ChatGPT를 활용하여 건설 장비 합성 이미지를 생성하고 (1) 합성 이미지 단독, (2) 실제 이미지 단독, (3) 실제·합성 이미지를 결합한 세 가지 유형의 데이터셋을 구성하여 YOLO11n 객체 탐지 모델을 훈련시키고 각 모델의 성능을 비교하였다. 그 결과, 실제 이미지에 합성 이미지를 추가했을 때 mAP50, mAP50-95와 같은 주요 성능 지표가 전반적으로 개선되는 것을 확인할 수 있었고, 특히 이러한 개선은 데이터 규모가 작은 데이터셋일수록 성능 개선 폭이 더 크게 나타났다. 이러한 결과는 Text-to-Image 모델로 생성한 합성 이미지가 실제 데이터, 특히 소규모 데이터셋의 부족한 데이터 규모를 보완하는 효과적인 수단이 될 수 있을 가능성을 보여주었다.
향후 연구에서는 건설 현장에서의 더욱 다양한 상황들을 반영하여 합성 이미지를 생성해 볼 필요가 있다. 건설 분야는 조명, 기상 조건, 장비 간의 상호작용, 작업자와 장비의 혼재 등 다양한 환경 요인이 있고 현장에서 이러한 모든 환경 요인이 반영된 데이터들을 확보하는 것에는 큰 제약이 따를 수 있다. 이 연구에서 확인된 합성 이미지 데이터의 가능성을 확장하여, Text-to-Image 모델을 활용해 더욱 다양한 상황을 반영한 합성 이미지를 생성한다면 건설 현장에서의 객체 탐지 모델 성능을 한층 더 높이고, 건설 현장 이미지 데이터셋 보완에 실질적인 기여를 할 수 있을 것으로 기대된다.
또한, 이 연구에서는 건설 장비만을 대상으로 실험을 진행하였으며, 건설 현장에서 중요할 수 있는 다른 객체들에 대해서는 다루지 않았다. 따라서 향후 연구에서는 안전모·조끼와 같은 보호 장비, 구조물, 건설 자재 등 다양한 객체에도 Text-to- Image 모델을 적용해 보는 시도가 필요하다. 이러한 확장은 합성 이미지의 활용 가능성을 건설 장비 탐지를 넘어 건설 현장 전반으로 확장시킬 수 있을 것이며, 실제 데이터 수집의 제약을 보완하고 건설 현장 대상 객체 탐지 모델의 성능을 향상시키는 데 기여할 수 있을 것으로 기대된다.
