

1. 서 론
1.1 연구의 배경 및 목적
1.2 연구의 범위 및 방법
2. 건설 사고: 시스템적 접근과 비정형 데이터
2.1 시스템적 접근법
2.2 비정형 데이터 활용: NLP와 LLM
3. 연구 방법론
3.1 인적 요인 분석 및 분류 시스템(HFACS)
3.2 대규모 언어 모델(LLM) 구현
4. 실험 설계
4.1 데이터 수집 및 전처리
4.2 프롬프트 엔지니어링
4.3 결과 검증 및 개선
4.4 분석
5. 연구 결과
5.1 HFACS 분류 결과
5.2 자체 판단 신뢰도 분석
6. 논 의
6.1 결과해석
6.2 한계 및 향후 연구 방향
7. 결 론
1. 서 론
1.1 연구의 배경 및 목적
인적 오류는 인간의 실수를 포괄하는 개념으로, 건설업을 포함한 다양한 산업 분야에서 사고의 주요 원인으로 인식되고 있다(Garrett & Teizer, 2009; Ye et al., 2018). 예를 들어, 한국의 국토안전관리원이 제공하는 건설공사 안전관리 종합정보망(CSI)의 사고 사례 분석 결과에 따르면, 2019년 7월 1일부터 2024년 7월 7일까지 총 24,577건의 사고 중 '작업자 부주의'로 인한 사고는 13,594건으로, 전체의 55%를 차지하며 58개의 사고원인 중 가장 높은 비중을 나타내고 있다. 국토안전관리원의 정의에 따르면, 작업자 부주의는 인양로프 해체 방법 미흡, 장애물 충돌, 임시 받침목 제거 등 작업자의 단순과실을 의미하며(KALIS, 2023), 이는 인적 오류의 한 형태로 간주된다. 이와 같은 통계는 한국 건설 산업에서도 인적 오류가 사고의 주요 원인임을 명확히 시사한다.
그러나 대부분의 인적 오류에 대한 접근은 직접적인 원인 파악과 대책 수립이 쉽다는 실용성 등의 이유로 일선 근로자의 행위에 초점을 맞춘다(Read et al., 2021). 이러한 접근은 근로자 재교육에 그치며(Read et al., 2021), 근본적인 문제 해결에는 한계를 보인다. 이에 근본적인 개선을 위해서는 인적 오류를 단순히 개인의 실수로 간주하는 것이 아니라, 시스템의 상위 및 잠재적 요인의 결과까지 고려하여 근본 원인을 해결하는 체계적 접근 방식(Wang et al., 2016)의 필요성이 대두되고 있다.
이러한 시스템적 접근은 사고 기여 요인들을 파악하고, 사고를 종합적으로 검토하기 위해 사고 관련 텍스트 데이터를 활용한다(Ma & Chen, 2024). 그러나 텍스트와 같은 비정형 데이터는 주로 수동 분석이 필요하여 시간 소요(Chokor et al., 2016), 분석자에 따른 관점 차이(Yoo et al., 2024) 등으로 인해 잠재적으로 부정확한 분석을 초래할 수 있는 어려움이 존재한다(Kumi et al., 2024).
본 연구는 한국 건설 산업에서 작업자 부주의로 인한 사고가 과반수를 차지하는 심각성과, 이에 대한 시스템적 접근의 필요성을 인식한다. 특히 시스템적 접근에서 비정형 데이터 분석의 현실적 한계에 주목하며, 이를 효과적인 방안으로 활용하여 작업자 부주의 사고를 체계적으로 분석하고자 한다. 이를 통해 작업 조건과 조직적 영향까지 포함하는 사고 예방 대책을 제시하고 근본적인 건설 안전 개선에 기여하고자 한다.
1.2 연구의 범위 및 방법
본 연구는 건설공사 안전관리 종합정보망(CSI)에 등록된 사고 사례 중 작업자 부주의로 인한 사고를 대상으로 한다. 특히 가장 빈번한 '떨어짐' 사고 1,816건으로 연구 범위를 한정하며, 사례별로 비정형 데이터인 사고경위와 구체적 사고원인을 포함하여 6가지 변수('안전방호', '개인보호', '기상상태 - 날씨', '공종 - 중분류', '사고경위', '구체적 사고원인')를 분석 대상으로 삼았다. 이 떨어짐 사고는 CSI의 분류 체계에 따라 5개의 높이 범주로 구분하여 높이별 근본 원인과 원인의 변화를 분석하였다. 연구 방법은 인적 오류에 특화된 체계적 분석 프레임워크인 인적 요인 분석 및 분류 시스템(Human Factors Analysis and Classification System, HFACS)과 비정형 데이터를 자체적으로 이해, 분석하기 위한 대규모 언어 모델(Large Language Model, LLM)로 구성되었다. 또한 LLM의 효과적 적용을 위해 LLM의 입력을 설계하는 프롬프트 엔지니어링을 도입하였다.
2. 건설 사고: 시스템적 접근과 비정형 데이터
작업자 부주의로 인한 건설 사고 분석을 위하여 시스템적 접근법과 비정형 데이터 활용 기술에 주목하였다. 건설 사고 분석에서 두 방법론의 적용 현황 및 한계점을 검토함으로써 인적 요인 분석 및 분류 시스템(HFACS)과 대규모 언어 모델(LLM)의 결합 가능성을 제시하였다.
2.1 시스템적 접근법
시스템적 접근법은 사고를 인적 요인을 포함한 시스템 전체의 상호작용으로 인식하여 포괄적인 분석을 지원한다. Woolley et al. (2020)은 건설 산업에 시스템 이론적 사고 모델 및 프로세스(Systems Theoretic Accident Modelling and Processes, STAMP)를 적용하여 행위자, 조직, 통제, 의사소통 루프 및 관계를 보여주는 제어 구조 모델을 제시하였다. Kang et al. (2021)은 사고 사례를 인적 요인 분석 및 분류 시스템(HFACS)으로 분류하여, 의미 네트워크 분석(Semantic Network Analysis, SNA)을 통해 요인 간의 관계를 분석하였다. Rafindadi et al. (2022)은 계층분석법(Analytic Hierarchy Process, AHP)을 사용하여 건설업의 치명적 추락 사고의 원인과 하위 요인들을 분석하였다. Wang et al. (2024)은 작업 환경과 조직, 2가지 수준에서 4가지 오류를 고려하는 2-4 모델을 사용하여 건설 근로자의 불안전 행위 영향 요인을 분석하였다. 이러한 접근은 다양한 변수를 고려하여 사고의 근본적인 맥락을 파악하는 데 유용하다. 그러나 이 방법은 주로 인간 전문가가 직접 사고 보고서를 읽고 각 접근법에 맞게 분석해야 하는 수동적 절차가 요구된다. 이는 앞서 언급된 것처럼 많은 시간이 소요되고, 분석자의 주관이 개입될 여지가 있으며, 분석의 일관성 유지에도 한계가 존재한다. 예를 들어, Kang et al. (2021)의 연구에서 약 6만 건의 사고 사례 분류에 15명의 전문인력이 필요하였다는 점은 이러한 수동 분석의 규모와 복잡성을 보여준다.
2.2 비정형 데이터 활용: NLP와 LLM
비정형 데이터 이용 시 수동적 분석의 한계를 극복하고 이를 효율적으로 활용하기 위해 다양한 인공지능 기술이 적용되고 있다(Jia et al., 2024). 본 연구에서는 특히 자동화가 가능한 자연어 처리(NLP)와 대규모 언어 모델(LLM)에 초점을 맞추어 선행 연구를 고찰하였다.
2.2.1 자연어 처리(NLP)
자연어 처리(Natural Language Processing, NLP)는 컴퓨터가 인간의 언어를 이해, 해석 및 처리하는 인공지능 분야로, 비정형 데이터로부터 정보를 자동으로 추출하고 분류할 수 있어, 사고 보고서의 비정형 데이터를 활용하여 분석하는 데 이용된다. Tixier et al. (2016)은 NLP 시스템을 개발하여 비정형 건설 사고 보고서에서 95% 이상의 정확도로 정의된 변수를 자동 추출하는 데 성공하였다. Zhang et al. (2019)은 NLP 기술과 대량의 텍스트에서 유용한 정보를 추출하는 텍스트 마이닝을 이용하여 건설 사고 보고서에서 사고원인 분류, 위험 객체를 식별하였다. Pan et al. (2022)은 NLP 기술로 사고 보고서에서 사고-부상 유형과 신체 부위 요인을 자동으로 식별하는 프레임워크를 개발하였다. Li & Wu (2023)은 NLP 기술을 이용하여 사고 서술을 자동으로 분류하고 핵심 정보를 추출하는 방법을 개발하였으며, 딥러닝 모델로 사고 유형을 분류하고, 단어의 중요도를 계산하는 TF-IDF 알고리즘으로 핵심 정보를 추출하였다. Khan et al. (2024)은 NLP와 데이터를 유사한 그룹으로 묶는 클러스터링 기법을 사용해 사고 유형과 활동 간의 연관성을 분석하는 의사결정 지원 시스템을 개발하였다. Kumi et al. (2024)은 NLP와 기계학습을 이용하여 사고 사례를 자동으로 분류하는 시스템을 개발하였다. Ma & Chen (2024)은 시스템적 접근법인 Accimap과 NLP를 결합하여 자동화된 과정으로 사고 보고서를 분석하였다. 이러한 연구들은 비정형 데이터에서 정보를 자동으로 추출하고 활용하는 데 상당한 진전을 보여준다. 그러나 전통적인 NLP 기술은 주로 사전에 정의된 규칙이나 훈련된 모델에 의존하여 단일 차원의 정보에 초점을 맞춘다(Ma & Chen, 2024). 이로 인해 NLP 기반 분석은 조직이나 관리적 차원을 포함한 사고의 잠재적 맥락을 충분히 고려하지 못하는 한계를 보인다.
2.2.2 대규모 언어 모델(LLM)
대규모 언어 모델(LLM)은 방대한 양의 자연어 텍스트로 자기 지도 학습된 인공지능 모델이다. 또한, LLM은 트랜스포머 아키텍처를 기반으로, 텍스트 내 모든 요소의 상호작용을 동시에 처리한다. 이러한 학습 방식과 구조적 특성으로 LLM은 텍스트의 맥락을 포괄적으로 이해하고, 함축적 의미까지 파악할 수 있는 능력을 보여주고 있다. 일부 LLM은 인간과 유사한 텍스트 생성 능력까지 보유하여 단순 사고 분석을 넘어선 새로운 활용 가능성을 제시한다. Smetana et al. (2024)은 GPT-3.5 모델을 사용하여 사고 서술의 맥락적 특성을 바탕으로 사고 유형을 분류하였으며, 93.7%의 높은 정확도를 달성하였다. Yoo et al. (2024)은 기존 NLP의 한계를 인식하고 LLM을 제안하여, 사고 보고서의 비정형 데이터를 분류하는 데 있어 GPT와 이전 사고 분류 모델을 비교 분석함으로써 GPT의 우수성을 입증하였다. 이러한 연구들은 LLM이 비정형 데이터 활용에 있어 기존 NLP 기술의 한계를 상당 부분 보완할 수 있음을 시사한다. 그러나 현재까지의 LLM 연구는 대부분의 NLP 연구와 마찬가지로 단순 분류 등의 표면적 분석에 머무는 경향이 있어 LLM의 장점을 충분히 활용하지 못하는 한계로 이어진다. 특히, 건설 산업에서의 LLM을 활용한 연구는 아직 초기 단계에 머물러 있어, 심층적 사고 분석 연구는 부족한 상황이다.
3. 연구 방법론
선행 연구 고찰 결과, 시스템적 접근법은 수동 분석으로 인한 비효율성과 주관적인 한계가 있었다. 또한 비정형 데이터 활용 기술인 NLP와 LLM 연구들은 단순 분류에 집중되어, 시스템 전반의 심층적 분석으로 나아가지 못하였다. 이에 본 연구에서는 시스템적 접근법의 체계적 분석 구조와 LLM의 맥락 이해 능력을 통합하는 새로운 방법론을 고안하였다. 건설 사고 분석 분야에서 시도되지 않았던 이러한 통합적 접근을 통해 기존 연구의 한계를 상호 보완하고자 한다. 구체적으로 본 연구는 인적 오류에 특화되고 대규모 통계 분석이 가능한 HFACS와 LLM의 결합 방법론을 제안한다. 이 방법론을 건설 현장의 작업자 부주의 사고 중 떨어짐 사고에 적용하여 높이별 원인을 체계적으로 규명하고자 한다. 이를 위해 HFACS의 특성과 구조를 분석하고 연구 목표에 맞게 적용하였으며, LLM의 구체적인 모델과 프롬프트 엔지니어링을 설계하였다.
3.1 인적 요인 분석 및 분류 시스템(HFACS)
인적 요인 분석 및 분류 시스템(HFACS)은 항공 분야의 인적 오류로 인한 사고를 분석하기 위해 개발된 체계적 프레임워크(Shappell & Wiegmann, 2000)로, 그 효용성이 입증되어 건설업을 포함한 여러 산업 분야에 적용되고 있다(Lim et al., 2020; Kaptan et al., 2021; Jalali et al., 2023). HFACS는 사고의 원인을 4가지 주요 단계와 단계별 요인으로 분류하는 계층적 구조로 이루어져 있다. 4가지 단계는 각각 1단계 불안전한 행위, 2단계 불안전한 행위의 전제 조건, 3단계 불안전한 감독, 4단계 조직 영향이며, 하위 단계는 상위 단계의 영향을 받는다는 원리를 바탕으로 한다(Yoon et al., 2017). HFACS는 기본적으로 4단계 구조를 기반으로, 연구 대상과 목적에 따라 세부 요인을 수정하여 적용된다.
본 연구에서는 Wong et al. (2016)의 수정된 버전을 채택하였으며, 그 이유는 다음과 같다. 첫째, Wong et al. (2016)은 추락 사고 사례를 분석하여 기존 HFACS의 2단계에 타인에 의한 위험(Hazard by others, Hbo) 요인을 추가하였다. 이는 본 연구의 범위인 떨어짐 사고의 특성을 반영하기에 적합하였다. 둘째, 각 요인별로 상세한 정의와 다양한 예시를 포함한다. 이는 LLM이 각 요인의 특성을 명확히 이해하고 사고 사례를 분류하는 데 풍부한 맥락을 제공하였다. 셋째, 국내 건설 현장에 대한 적용 가능성이 검증되었다. Kang et al. (2021) 은 국가와 무관한 데이터 특성을 고려해 일부 요인만을 제외하고 적용하였다. 이에 본 연구에서도 채택한 HFACS 버전의 단계, 요인, 정의 및 예시를 수정 없이 활용하였으며, Table 1은 각 단계별 요인들에 대한 원문의 정의를 있는 그대로 보여준다. 이러한 계층적 분류를 기반으로 LLM이 HFACS 구조를 체계적으로 이해하고 이를 사고 분석에 효과적으로 적용할 수 있도록 하였다.
Table 1.
Hierarchical structure of factors in HFACS (Integrated without modification from Wong et al., 2016)
3.2 대규모 언어 모델(LLM) 구현
본 연구에서는 비정형 사고 데이터의 맥락을 이해하고 HFACS의 적절한 요인을 선택하기 위해 LLM을 체계적인 프롬프트 엔지니어링을 통하여 활용하였다.
3.2.1 Claude 3.5 sonnet 선정
사고 분석 과정에서 LLM의 텍스트 생성 능력을 활용하고자 이와 같은 기능을 보유한 LLM을 대상으로 선정 과정을 진행하였다. 이 중 최고 성능 모델인 GPT-4o와 이에 유사한 Claude 3.5 Sonnet (Anthropic, 2024)을 초기 후보로 선정하였다. 연구의 대상이 한국어 사고 사례임을 고려하여, 두 모델의 한국어 처리 능력을 비교 평가하였다. 평가 결과, 상대적 우위를 보인 Claude 3.5 Sonnet을 최종 모델로 선정하였다.
3.2.2 프롬프트 엔지니어링 활용
프롬프트 엔지니어링은 LLM이 목표 결과를 얻을 수 있도록 최적화된 입력을 설계하는 과정이다. 본 연구에서는 입력된 사고 데이터를 이해하고, HFACS의 단계별로 가장 적절한 요인을 1개씩 선택한 후, 그 선택에 대한 자기 신뢰도를 판단하여 지정된 출력 형식에 맞추어 결과를 도출하는 것을 목표로 하였다. 또한, LLM의 주요 한계로 지적되는 존재하지 않는 정보를 생성하는 환각(hallucination)과 해석 과정을 알 수 없는 모델의 불투명성 문제를 해결하는 것도 목표로 설정하였다.
Figure 1은 연구에서 사용된 프롬프트의 요소와 기법을 나타낸다. 이를 통해 목표 달성을 위한 방법을 설명하고, 세부 내용과 구현 방법은 4.2절에서 상세히 기술한다.
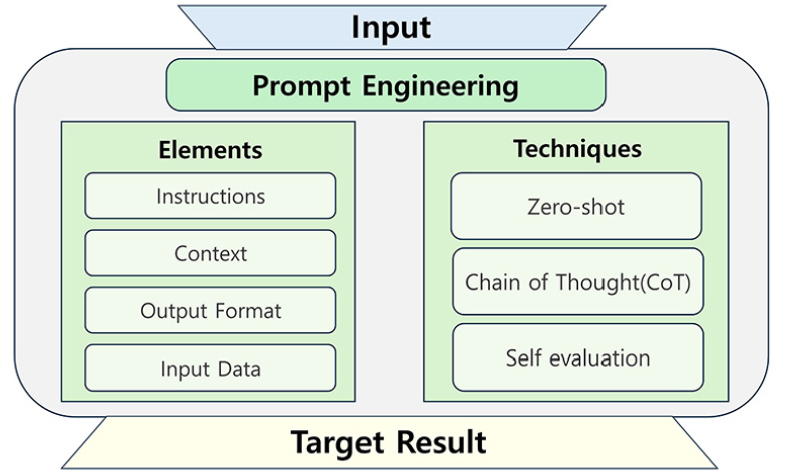
주요 구성 요소는 지시 사항, 맥락, 출력 형식, 입력 데이터가 있다. 본 연구에서는 HFACS 분석 과정과 자기 신뢰도 판단을 지시 사항으로 하고, HFACS 정보와 자기 판단 기준을 맥락으로 제공하였다. 출력 형식은 서술형과 분류형 두 가지로 설정하였으며, 데이터 처리의 정확성과 독립성을 확보하기 위해 입력 데이터는 개별적으로 제공하였다. 환각을 최소화하기 위해 사전 예시나 훈련 없이 작업을 수행하는 Zero-shot 기법과 단계별로 추론을 유도하는 Chain of Thought (CoT) 기법을 활용하여 HFACS 1 ~ 4단계 요인 선택 과정을 진행함으로써 정확도를 향상하였다(Wei et al., 2022). 해석 과정의 불투명성 문제는 서술형 출력과 자신의 출력을 평가하는 Self evaluation (Zhang et al., 2024) 기법을 통해 해결하고자 하였는데, 이는 텍스트 생성이 가능한 Claude를 활용하여 자신의 분석 과정을 명시적으로 서술한 결과와 이에 대한 자체 판단 신뢰도를 연구자가 직접 검토함으로써 해결하고자 하였다. 이 같은 체계적인 프롬프트 엔지니어링을 활용하여 LLM이 사고 데이터를 이해하고, HFACS 분석을 수행하여 근본 원인을 파악하고자 하였다.
4. 실험 설계
실험은 데이터 수집 및 전처리, 프롬프트 엔지니어링, 결과 검토 및 수정, 분석으로 진행하였다.
4.1 데이터 수집 및 전처리
데이터는 건설공사 안전관리 종합정보망(CSI)에서 제공하는 사고 사례를 활용하였다. 2019년 7월 1일부터 2024년 7월 7일까지 총 24,641건의 사고 사례를 수집하였으며, 데이터 전처리 과정에서 중복이 의심되는 사례들을 검토하고 제거하여 최종적으로 24,577건의 유효 사례를 선별하였다.
분석 대상 데이터의 추출과 선정은 51개의 변수로 구성된 CSI의 사고 분류체계를 활용하였다. 먼저, ‘사고원인’ 변수를 통해 작업자 부주의 13,594건의 사고를 확인하고, 이 중 ‘인적사고’에서 높이가 명시된 떨어짐 사고 1,816건의 데이터를 추출하였다. 이후, 분석을 위해 나머지 49개의 변수 중 사고의 맥락을 파악할 수 있는 6개의 주요 변수를 선별하였다. 비정형 변수로는 사고의 발생 상황과 배경을 제공하는 '사고경위'와 '구체적 사고원인'을 채택하였다. 정형 변수의 경우, 물리적 환경 요소인 '기상상태 – 날씨', 안전관리 수준과 작업자의 안전 확보 여부를 나타내는 '안전방호', '개인보호', 그리고 작업 특성을 반영하는 '공종 – 중분류'를 선정하였다. 선정되지 않은 변수들은 사고 발생과의 연관성이 낮은 행정 정보(공사시작일, 공사비, 낙찰률 등), 사후 처리 정보(피해금액, 재발방지대책 등)와 같은 근거로 제외하였다.
또한, 떨어짐 사고는 CSI의 분류를 따라 5개의 범주([2미터 미만], [2미터 이상 ~ 3미터 미만], [3미터 이상 ~ 5미터 미만], [5미터 이상 ~ 10미터 미만], [10미터 이상])로 구성되었다. 이러한 구분은 산업안전보건기준에 관한 규칙(제14조, 제28조, 제32조, 제57조 등)에 따른 개인보호구 착용, 안전 시설물 설치 및 점검 등의 안전관리 규정과 연관되어, 본 연구는 이 높이 범주를 기준으로 분석을 수행하였다.
4.2 프롬프트 엔지니어링
프롬프트 엔지니어링은 Anthropic의 Claude API를 활용하였으며, 구체적으로 claude-3-5-sonnet-20240620 모델을 사용하였다. 출력의 최대 토큰(max_tokens)은 분류형일 때 100 토큰, 서술형일 때 1,024 토큰으로 설정하였으며, 0과 1 사잇값을 가지는 온도(temperature) 파라미터는 낮을수록 일관된 출력을 생성하기에 일관성을 위해 0으로 설정하였다.
또한, API의 토큰 제한을 고려하여, 1,816건의 데이터는 나누어 처리하였다. 2미터 미만 사고(1,051건)는 5개 세트, 2미터 이상 ~ 3미터 미만 사고(379건)는 2개 세트, 나머지 높이 범주의 사고(3미터 이상 ~ 5미터 미만 214건, 5미터 이상 ~ 10미터 미만 103건, 10미터 이상 69건)는 각각 단일 세트로 총 10개의 데이터 세트로 구성하였다. 초기 실험에서 1회의 API 호출로 1개 세트 전체를 분석하는 방식을 시도하였으나, HFACS 분석의 복잡성으로 인해 결과의 품질이 저하되는 문제가 발견되었다. 이에 따라 각 사고 사례를 개별 API로 처리하는 방식으로 수정하여 10회의 실행에서 총 1,816회의 API를 호출하여 진행하였다. 이 과정에서 프롬프트는 입력 데이터, 지시 사항, 맥락, 출력 형식의 네 가지 주요 요소로 구성하였다.
4.2.1 입력 데이터
각 사고 사례의 6개 핵심 변수('안전방호', '개인보호', '기상상태 - 날씨', '공종 - 중분류', '사고경위', '구체적 사고원인')는 데이터 처리의 효율성과 일관성을 높이기 위해 JSON 형식으로 구조화하여 입력하였다. Figure 2는 이러한 데이터의 예시를 보여준다.

4.2.2 지시 사항
지시 사항은 TXT 파일 형식의 Instructions와 System Message로 구성하였다. Figure 3에 제시된 Instructions에는 HFACS 분석 방법론, 그리고 분석 시 고려해야 할 주요 사항들이 상세히 기술되어 있다. 특히, HFACS가 영어로 제공됨을 명시하여 한국어 사고 사례에 적용 시 발생할 수 있는 언어적 혼란을 줄이고자 하였다. 또한, 데이터에 언급된 내용을 우선으로 고려하도록 지시하여 분석의 객관성을 높이고자 하였으며, 분석 순서를 명확히 제시하여 체계적인 접근을 유도하였다. HFACS 단계별 요인 선택 과정에서는 CoT 기법을 적용하여 해당 단계의 모든 요인을 충분히 고려할 수 있도록 하였다. 구체적으로, 1단계 불안전한 행위의 요인 선택에서는 작업자의 행위와 그 이유, 안전 규정 위반 여부와 행위의 의도성을 순차적으로 고려하여 5가지 요인을 종합적으로 평가한 후, 가장 적합한 요인을 선택하게 하였다. 선택 후에는 선택 요인과 선택 이유를 토대로 자기 신뢰도 판단을 요구함으로써 분석 결과의 신뢰성을 자체적으로 검증할 수 있도록 설계하였다.

Figure 4의 System Message는 API 호출 시 전체적인 대화의 흐름을 결정하는 System 파라미터로, LLM의 역할을 사고 분석 전문가로 정의하고, 분석에 필요한 지침과 참조 문서를 안내하였다. 또한, 분석 결과의 일관성 확보를 위해 주어진 전문 용어의 사용과 확실한 표현을 주의 사항으로 지시하였다.

4.2.3 맥락
맥락 정보로는 HFACS의 상세 구조와 Self Evaluation 기준을 제공하였다. HFACS의 단계부터 예시까지 통합된 표는 Figure 5와 같이 JSON 형식으로 변환되어 첨부되었다. 이러한 구조화된 형식으로 LLM이 HFACS의 계층적 구조와 각 요인의 의미를 정확히 이해하고 이를 분석에 적용할 수 있도록 하였다.
Self Evaluation은 추론 과정을 알 수 없는 LLM의 해석 불투명성 문제를 보완하기 위해 도입하였다. 본 연구에서는 요인을 선택할 때 데이터의 언급된 내용을 바탕으로 가능성을 고려하지 않을수록 높은 신뢰도로 삼았다. 또한 1점부터 5점까지 총 5개의 점수에 대한 기준을 각각 설정하여 일관성을 가질 수 있도록 하였으며, 범주를 명확히 표현하기 위해 JSON 형식으로 변환하였다.

4.2.4 출력 형식
출력 형식은 정량적 통계 분석을 위한 분류형과 분류 과정의 타당성을 검증하기 위한 서술형, 두 가지로 설계하였다. Figure 6의 분류형 출력은 대량의 데이터를 효율적으로 처리하고 분석하기 위해 설계하였다. 각 HFACS 단계 요인의 약자와 해당 선택에 대한 신뢰도 점수만을 쉼표로 구분하여 반환하도록 하였다.

Figure 7의 서술형 출력은 LLM의 분석 과정과 논리를 검증할 수 있도록 설계하였다. 다만, 계산 자원의 효율적 사용을 위해 모든 데이터에 대해 서술형 출력을 생성하기보다는 각 세트에서 무작위로 선정된 1건 이상의 사례에 대해서만 생성하도록 하였다. 이 서술형 출력에는 분류형 결과와 더불어 각 HFACS 단계별 요인 선택의 근거가 요구되었다.

4.3 결과 검증 및 개선
결과 검증은 두 단계로 진행되었다. 먼저, 분류형 결과를 통해 입력 세트의 전체 데이터와 출력 데이터의 수량이 일치하는지 확인하였다. 다음으로, 서술형 결과를 검토하였다. 이 과정에서 서술형 결과에 해당하는 분류형 결과, 그리고 원본 입력 데이터를 비교 분석하였다. 분석의 일관성, 사용한 어휘의 적절성, 논리 전개의 타당성, 신뢰도 판단의 적합성 등을 다양한 측면에서 평가하였다. Table 2와 Table 3은 원본 입력 데이터와 결과 데이터 예시이다.
Table 2.
Example of input accident data (translated from the original text written in Korean)
Table 3.
Example of output results (translated from the original text written in Korean)
검증 과정에서 도출된 문제점을 바탕으로 프롬프트를 반복적으로 개선하였다. 예시로, 초기 설계에서는 LLM의 구조 이해를 위해 Instruction을 JSON 형식으로 입력하였으나, 이는 예상과 상반되게 맥락 정보에 대한 이해도 저하를 보여 TXT 형식을 채택하였다. 또한, 출력 형식에서 표 형태, HFACS 단계별 다중 요인 선택 등 다양한 방식을 시도하였으나, 출력 형식의 복잡도가 증가할수록 결과의 품질이 현저히 저하되는 현상이 관찰되었다. 이러한 시도와 검증의 반복을 통해 4.2절에서 서술한 프롬프트 구조와 형식이 확립되었다.
4.4 분석
최종적으로 HFACS 결과의 분류 오류를 검증하였다. 오류를 제거한 후, 분류형 결과를 활용하여 전체 떨어짐 사고의 HFACS 분류 분석, 높이별 HFACS 분류 분석, 분류 결과의 신뢰도 분석을 진행하였다.
5. 연구 결과
총 1,816개의 분류형 결과 중, 14개가 해당하는 단계가 아닌 다른 단계의 요인을 선택하는 오류가 파악되었다. 결과적으로 Table 4와 같이 1,804개의 결과가 확보되어 99.34%의 높은 분류 유효율을 달성하였다. 이후의 분석은 이 1,804개의 유효 데이터를 대상으로 수행되었다.
Table 4.
Height distribution of result fall data
5.1 HFACS 분류 결과
5.1.1 전체 HFACS 요인 분석
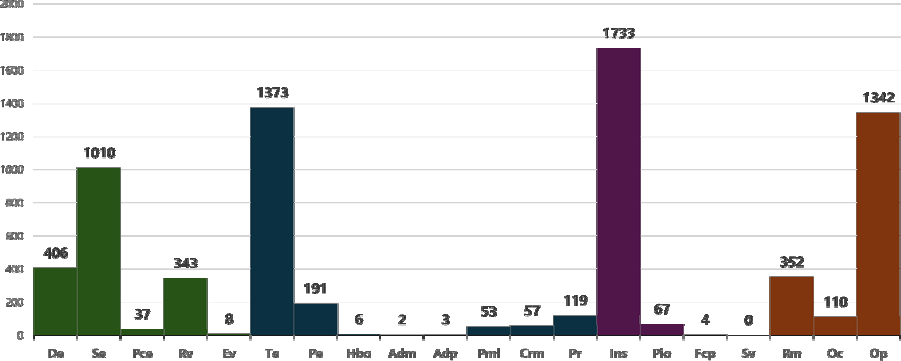
Figure 8은 전체 HFACS 분류 데이터에 대한 단계별 요인 분포를 나타낸다. 각 단계의 주요 요인들을 빈도순으로 정리하면 다음과 같다. 1단계 불안전한 행위에서는 기술 기반 오류(Se) 1,010건, 결정 오류(De) 406건, 일상적 위반(Rv)이 343건이었으며, 2단계 불안전한 행위의 전제 조건에서는 기술적 환경(Te)이 1,373건, 물리적 환경(Pe) 191건, 개인 준비(Pr) 119건 순으로 확인되었다. 3단계 불안전한 감독에서는 부적절한 감독(Ins)이 1,733건으로 HFACS 전체 요인 중에서 가장 높은 빈도를 보였으며, 이어서 부적절한 작업 계획(Pio) 67건, 문제 해결 실패(Fcp)가 4건이었다. 4단계 조직 영향에서는 조직 프로세스(Op)가 1,342건, 자원 관리(Rm) 352건, 조직 문화(Oc) 110건으로 나타났다.
5.1.2 높이별 HFACS 요인 분석
Table 5는 높이별 HFACS 분류 결과를 상세히 제시한다. Figure 9은 Table 5의 결과를 이용하여 높이에 따른 HFACS 단계별 요인을 백분위로 나타낸다. 1단계는 높이에 따른 변화가 관찰되었으나, 2, 3, 4단계는 높이와 관계없이 유사한 경향을 보였으며, 이는 전체 높이 분류 경향과도 일치하는 양상을 나타내었다.
Table 5.
Height-based distribution by HFACS factors: frequency and percentage

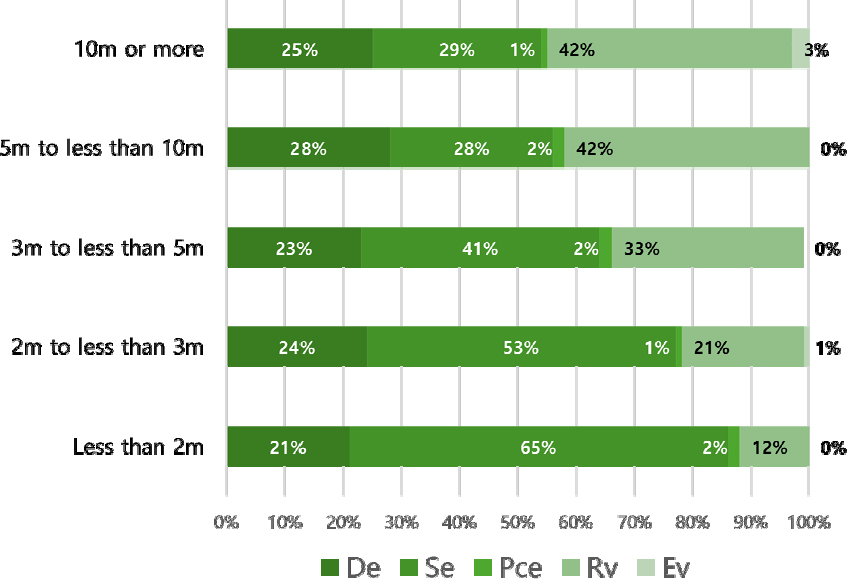
Figure 10은 Figure 9에서 높이에 따른 변화를 보인 1단계 불안전한 행위의 결과를 자세히 보여준다. 높이가 증가함에 따라 다음과 같은 변화가 있었다. 2미터 미만에서 2미터 이상 ~ 3미터 미만으로 상승 시, 기술 기반 오류(Se)가 12%p 감소, 일상적 위반(Rv)이 9%p 증가하였다. 2미터 이상 ~ 3미터 미만에서 3미터 이상 ~ 5미터 미만으로 상승 시에는 기술 기반 오류(Se)의 12%p 감소와 일상적 위반(Rv)의 12%p 증가가 확인되었다. 3미터 이상 ~ 5미터 미만에서 5미터 이상 ~ 10미터 미만으로의 상승은 기술 기반 오류(Se) 13%p 감소, 일상적 위반(Rv)의 9%p 증가를 보였다. 5미터 이상 ~ 10미터 미만에서 10미터 이상의 상승은 기술 기반 오류(Se) 가 1%p 증가하였으며, 일상적 위반(Rv)은 변화를 보이지 않는다. 이러한 결과는 10미터 미만까지의 높이 증가에 따라 기술 기반 오류(Se)의 비중은 감소하고, 일상적 위반(Rv)의 비중은 증가하는 경향을 나타내고 있다.
5.2 자체 판단 신뢰도 분석
Table 6은 전체 HFACS 분류에 대한 Claude의 자체 판단 신뢰도 분석 결과를 제시한다. 신뢰도 분석은 1,804개의 전체 데이터에 대해 수행되었다. 분석 결과, 1단계부터 3단계는 1점부터 5점까지의 점수가, 4단계는 1점부터 4점까지의 점수가 고르게 부여됨을 확인하였다. 표준 편차는 전 단계에서 0.6에서 0.7 사이로 비교적 작게 나타났다. 이는 각 단계의 신뢰도 점수가 평균을 중심으로 밀집된 분포를 보이고 있음을 의미한다. 이러한 결과는 데이터를 개별적으로 입력하였음에도 불구하고, 동일한 단계 내에서 유사한 정보량을 바탕으로 신뢰도 분석이 이루어졌음을 시사한다.
Table 6.
Analysis of reliability scores by HFACS steps
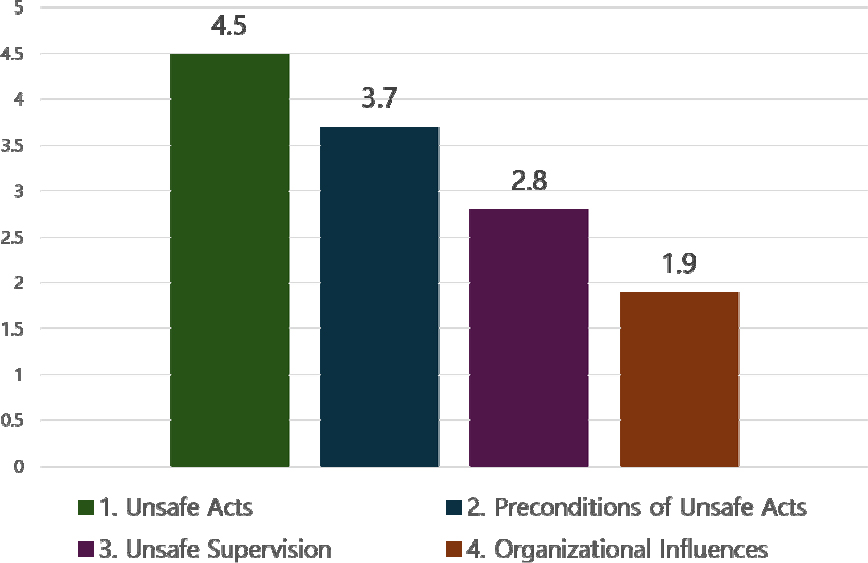
이에 따라, 단계별 평균값을 활용하여 신뢰도를 분석하였다. Figure 11은 HFACS 각 단계의 신뢰도 평균을 나타내며, HFACS 단계가 상승할수록 감소하는 경향을 보였다. 이는 상위 단계로 갈수록 데이터 내에 직접적으로 언급된 내용이 부족하여, 더 많은 추론이 필요하였음을 드러낸다.
6. 논 의
본 연구에서는 대규모 언어 모델(LLM)인 Claude와 인적 요인 분석 및 분류 시스템(HFACS)을 활용하여 건설 사고 분석을 수행하였다. 총 1,816건의 사고 사례 중 1,804건이 올바르게 분류되어 99.34%의 높은 분류 유효율을 달성하였으며, 이는 비정형 데이터의 시스템적 분석이 성공적이었음을 나타낸다. 또한, 체계적인 프롬프트 엔지니어링을 통해 사고 맥락 이해와 분석을 돕고 LLM의 한계를 보완하였다. 설계된 프롬프트를 반복 사용하여 분석의 효율성을 높이고, 사고마다 독립적으로 분석을 수행함으로써 일관성을 확보하였다. 이러한 접근 방식은 선행 연구에서 도출된 한계점인 시스템적 접근법의 수동 분석으로 인한 한계, 기존 NLP 방식의 사고 맥락 고려 어려움, 그리고 LLM과 심층적인 분석 방법 간의 결합 부재 등의 문제점을 잠재적으로 해결할 수 있음을 보여준다.
6.1 결과해석
결과 중 가장 주목할 만한 점은 작업 높이에 따른 불안전한 행위의 변화패턴이다. 2미터 미만에서 10미터 미만까지 높이가 증가함에 따라 기술 기반 오류(Se)는 65%에서 28%로 감소한 반면, 일상적 위반(Rv)은 12%에서 42%로 증가하였다. 이러한 패턴은 Lavie (1995)의 지각부하 이론을 통해 해석할 수 있다. 이에 의하면 지각부하가 높을수록 선택적 주의 집중이 이루어진다. 따라서 본 연구의 결과는 높이가 증가할수록 위험 부담으로 인해 작업 자체에 집중하게 되어 기술 기반 오류(Se)는 감소하지만, 안전에 대한 주의는 소홀해져 일상적 위반(Rv)이 증가하는 것으로 보인다.
반면, 2단계 불안전한 행위의 전제 조건, 3단계 불안전한 감독, 4단계 조직 영향에서는 1단계와 달리 높이에 따른 변화가 관찰되지 않았다. 이는 작업자의 직접적인 행위를 제외한 다른 단계들은 작업 높이와 관계없이 사고에 영향을 미치고 있음을 의미한다. 이와 같은 결과는 떨어짐 사고를 예방하기 위한 2가지 접근의 가능성을 제시한다. 첫째, 높이에 따라 변화하는 작업자의 행위를 고려한 맞춤형 안전 대책 수립이 가능하다. 둘째, 높이와 관계없이 일정하게 유지되는 작업 조건, 감독, 조직의 영향을 고려한 전반적인 안전관리 체계를 구축할 수 있다.
한편, HFACS의 단계가 상승할수록 신뢰도가 낮아지는 경향이 보였다. 1, 2단계는 각각 4.5와 3.7의 높은 신뢰도를 보이지만, 3, 4단계는 2.8과 1.9로 상대적으로 낮은 신뢰도를 나타냈다. 본 연구에서 신뢰도는 Claude의 자체 판단 지표로, HFACS 요인 선택 시 사고 데이터에 명시된 내용을 기반으로 추론이 적게 이루어질수록 높은 점수가 나오도록 정의되었다. 이러한 기준에서 신뢰도 감소는 단계가 높아질수록 정보가 부족하여 추론을 바탕으로 요인 선택이 이루어졌음을 의미한다. 따라서 3, 4단계의 분석 결과는 신중하게 해석해야 할 필요성이 제기된다. 또한, 이는 현재 CSI 사고 보고 체계에서 시스템의 상위 요인에 대한 기록이 부족함을 드러내며, 시스템 전체를 신뢰성 있게 고려하기 위해서는 향후 보고 체계의 개선이 필요함을 시사한다.
6.2 한계 및 향후 연구 방향
본 연구는 LLM을 활용한 HFACS 분류를 통해 건설 사고 분석에 새로운 접근을 시도하였으나, 몇 가지 한계점이 존재한다. 연구 범위 측면에서 '작업자 부주의'는 국토안전관리원의 정의를 따르지만, 기록자의 주관적 판단에 따라 '불안전한 행동' 등 다른 형태의 인적 오류와 중첩될 가능성이 있다. 또한 높이별 분석에서는 데이터 불균형(2미터 미만 1,051건, 10미터 이상 69건)으로 인한 결과 해석의 신중함이 요구되며, 프롬프트 엔지니어링의 설계와 검증이 연구진 자체 평가에 기반하여 외부 검증이 제한적이었다. 이러한 한계점들을 보완하기 위한 향후 연구 방향은 다음과 같다. 우선, 표본 오류를 줄이기 위해 인적 오류를 포괄하는 확장된 분석이 수행될 필요가 있으며, 데이터 불균형은 범주 통합이나 언더샘플링 등의 통계적 기법을 적용하여 해결할 수 있다. 프롬프트 엔지니어링의 경우, 다양한 설계안의 비교 분석과 건설안전 전문가의 검토 과정을 추가하여 분석의 객관성을 확보할 수 있다. 또한, 본 연구에서 발견된 높이에 따른 작업자의 행위 변화가 지각부하 이론과 연관된다는 해석에 대해 실증적 검증이 필요하며, 이와 HFACS 상위 단계 간의 상관관계 분석을 통해 떨어짐 사고를 보다 체계적으로 이해할 수 있다. 더불어, 각 높이 구간에서 요구되는 법적 안전 규정과의 연계 분석으로 더욱 실질적인 예방 대책 수립이 가능할 것으로 기대된다. 추가로, HFACS 상위 단계로 갈수록 나타나는 LLM 신뢰도 저하는 조직 영향 등 사고 발생의 근본 원인에 대한 정보 부족과 같은 현재 사고 보고 체계의 한계일 가능성이 높으나, LLM의 프롬프트 설계 개선 및 고도화된 모델의 필요성을 드러내는 근거가 될 수 있다. 이러한 발전 방향들을 토대로 더욱 신뢰성 있는 분석이 도출될 것으로 기대되며, 본 연구의 학술적, 실용적 가치를 한층 더 높일 수 있을 것으로 판단된다.
7. 결 론
본 연구에서는 건설 현장에서의 작업자 부주의로 인한 떨어짐 사고의 높이별 근본 원인을 시스템적으로 분석하였다. 이를 위해 대규모 언어 모델(LLM)을 활용하여 인적 요인 분석 및 분류 시스템(HFACS)의 분류를 수행하였다. 연구 결과, 전체 높이 구간에서의 분포를 통하여 사고를 일으킨 작업자의 행위, 행위의 조건, 감독, 조직의 영향을 확인하였다. 또한, 높이에 따른 HFACS 단계별 분석으로 원인의 변화를 식별하였다. 1단계 불안전한 행위에서는 높이가 2미터 미만에서 10미터 미만까지 증가할수록 기술 기반 오류(Se)는 65%에서 28%까지 감소하고, 일상적 위반(Rv)은 12%에서 42%까지 증가하는 경향을 보였다. 이를 통해 높이에 따른 작업자의 행위 변화패턴을 확인할 수 있었다. 반면, 2단계 불안전한 행위의 전제 조건, 3단계 불안전한 감독, 4단계 조직 영향은 높이와 관계없이 일정한 요인이 영향을 미치는 것을 보여주었다. 본 연구는 인적 오류 사고의 근본 해결을 위한 시스템적 접근의 중요성과 접근을 위하여 비정형 데이터를 효과적으로 활용하는 방법의 필요성에서 출발하였다. 연구 결과, 시스템의 상위 요인까지 고려하여 사고 사례를 효율적으로 분석할 수 있음을 입증하였으며, 높이에 따른 사고원인의 변화를 분석함으로써 고소 작업에서의 안전관리 방안을 수정하는 데 활용될 수 있을 것으로 기대된다.
