

1. 서 론
1.1 연구의 배경 및 목적
1.2 연구의 범위 및 방법
2. 선행 연구 및 이론 고찰
2.1 IFC 기반 BIM 데이터 운용 문제점 및 관련 연구 동향
2.2 분류에 활용되는 인공지능 알고리즘
3. 연구 방법
3.1 활용 BIM 데이터 개요
3.2 학습모델 구축 및 학습 방법
3.3 학습모델 평가 방법
4. MVCNN
4.1 MVCNN 학습모델 구축
4.2 기하 형상 이미지 데이터 구축
4.3 학습결과
5. MLP
5.1 MLP 학습모델 구축
5.2 기하 속성정보 데이터 구축
5.3 부재 간 관계정보 데이터 구축
5.4 관계정보 학습데이터 모델링 방안
5.5 MLP 모델 간의 결과 비교
5.6 MLP_2 모델의 학습결과
6. 앙상블
6.1 앙상블 모델 구축
6.2 학습결과
7. 종합 결과
8. 결론
1. 서 론
1.1 연구의 배경 및 목적
최근 건설 산업 내 재래식 업무 프로세스 개선을 통한 효율성 향상을 위해 Building Information Modeling (BIM) 기술 도입이 가속화되고 있다. 국내 BIM 도입은 건설 유관 정부부처 및 공기업 주도로 선행되어왔다. 대표적으로 한국도로공사 ‘Ex-BIM 로드맵’, 한국토지주택공사 ‘LH Civil-BIM 로드맵’ 등 도입 방향이 제시되며 공공발주 과정에서 BIM 적용을 의무화하는 추세이다.
각 기관에서 발주하는 사업마다 설계 및 시공 특성이 다르기에, BIM 적용 과정에서 개별 분야에 전문화된 BIM 소프트웨어들도 다수 개발되고 있다. 또한, 단일 사업별로 설계, 구조, 지반, 설비 등 다양한 분야가 복합적으로 참여하므로 이들 작업에 특성화된 BIM 소프트웨어가 필요해지고 있다.
이처럼 다수의 전문 BIM 소프트웨어가 등장함에 따라, 이들 간의 데이터 상호호환성 확보가 프로젝트 효율성 향상을 위한 중요한 요소가 되었다(Koo et al., 2018). 국제표준기구인 빌딩스마트협회에서는 BIM 데이터 간 공유를 위해 중립적 표준 모델인 Industry Foundation Classes (IFC)를 통해 원활한 정보 교환을 지원하고 있으며 주요 BIM 저작 도구들이 IFC 포맷을 지원하고 있다. 그러나 IFC가 가지고 있는 구조적 복잡성과 데이터 표현방법의 중복성으로 인해 BIM 객체의 정확한 형상 분류 및 속성정보가 올바르게 부여되지 않는 문제가 발생하고 있다(Eastman et al., 2010).
IFC 데이터의 이른바 시멘틱 무결성(semantic integrity)이 확보되지 않는 것은 BIM의 활용성 저하를 야기한다. 특히 BIM 부재마다 이에 상응하는 정확한 IFC 엔티티의 매핑이 보장되어야 한다(Lee et al., 2020). 일례로, BIM 모델의 보(beam) 부재는 IfcBeam이라는 IFC 엔티티에 매핑되어야 한다. 기존 연구자들은 BIM 객체 유형과 인스턴스 간의 관계 및 집합, 기하 및 위상정보 등을 토대로 규칙을 명리화하여 정확한 IFC 엔티티를 추론하고자 하는 연구를 진행해 왔다.
최근에는 BIM 부재의 이미지 혹은 3차원 형상 자체를 인공지능 알고리즘에 학습시켜 부재 유형을 분류하는 연구 사례가 등장하고 있다(Bloch and Sacks., 2018; Bienvenido-Huertas et al., 2019; Jung et al., 2019; Ajayakumar, 2021; Shen, 2020; Koo et al., 2021).
이 중 Koo et al. (2021)은 건축 BIM 부재 별 다각도 이미지를 Multi-View Convolutional Neural Network (MVCNN) 알고리즘에 학습시켜 개별 부재의 3D 형상정보를 인식, 부재 유형을 자동분류하고 이를 통해 IFC 엔티티와의 올바른 매핑 여부를 검토하는 연구를 진행하였다. 해당 연구는 7개의 건축 부재를 대상으로 98%의 높은 분류 정확도를 보였다. 그러나 기하 형상이 유사한 부재들의 경우 아직까지 정확히 구분하지 못하는 한계점이 존재하였다. 일례로 BIM 부재 중 바닥(slab)이나 천장(covering)은 외형상 거의 동일하기 때문에 2D 이미지만으로는 구분을 하기 어렵다.
이런 한계 개선을 위해 특정 부재와 인접 부재 간의 위상정보(topology), 그리고 부재별 차이점을 더욱 부각 시키는 구체적 기하속성 정보를 추가해 주면 분류 성능이 나아질 것으로 판단하였다. 그러나 MVCNN은 딥러닝 기법, 즉, 일종의 ‘블랙박스’이기 때문에 개별 특성변수를 인위적으로 학습에 추가할 수 없다. 특성변수를 지정해 주기 위해서는 별도의 기계학습 모델이 필요하다.
본 연구에서는 이의 해결 방안으로 앙상블(ensemble) 기법을 활용하고자 하였다. 앙상블 기법은 두 개 이상의 인공지능 모델을 동일한 데이터로 학습시킨 후, 이들의 분류 결과에 가중치 부여 및 병합하여 분류 성능을 꾀하는 방식이다(Polikar, 2006). 또한, 앙상블 모델은 여러 형태의 상이한 이종 데이터(heterogeneous data)를 기반으로 인공지능 모델을 학습시킬 때 사용할 수 있기에 본 연구 목적에 적합할 것으로 판단되었다(Xu et al., 2021).
이의 구현을 위해 두 가지 인공지능 모델을 활용하고자 하였다. 우선 MVCNN은 기존 연구와 동일하게 개별 BIM 부재의 2D 이미지 기반으로 학습시켰다. 이와는 별개로 BIM 객체 간 물리적 관계를 표현하는 위상정보와 부재 자체의 높이 또는 체적과 같은 기하 속성정보를 딥러닝 모델 중 하나인 다층 퍼셉트론(Multi-Layer Perceptron, MLP)에 학습을 시켰다. 마지막으로 두 모델의 분류 결과를 앙상블 기반으로 설계하여 나은 분류 결과를 최종 제시하도록 구축하였다.
궁극적으로 앙상블 모델을 통해 형상이 유사한 BIM 부재들의 분류 성능을 높이는 것을 목적으로 하였으며, 단순히 부재 이미지만 학습한 MVCNN 기반 분류기와 MVCNN과 MLP를 앙상블 한 분류기의 성능을 비교 검증하여 성능 향상을 확인하였다.
1.2 연구의 범위 및 방법
본 연구에서는 2개의 인공지능 알고리즘(MVCNN, MLP)을 대상으로 앙상블 기법을 적용하여, 형상이 유사한 부재까지 구분 가능한 최적의 BIM 부재 분류 학습모델을 구축하고자 하였다. 이를 위해 20층 규모의 BIM 모델을 대상으로 건축 분야에서 활용도가 높은 10개의 부재 유형을 연구 대상으로 삼았으며, 다음과 같은 단계로 연구를 진행하였다.
1단계: 기존 연구 조사 및 분석 범위 설정
기존 문헌 조사를 통해 기계학습 기반 시멘틱 강화 연구 동향 분석을 수행하고, IFC 데이터에서 추출 가능한 부재 특성들을 파악하였다.
2단계: 데이터 수집
개별 BIM 부재의 특성들은 python 라이브러리 PythonOCC와 KBim Assess-Lite 소프트웨어를 통해 추출하였다. 이때, 해당 정보들은 데이터 포맷이 상이하여 단일 알고리즘 모델로는 학습이 불가능하기 때문에 앙상블 기법 활용을 제안하였다.
3단계: 기하 형상 이미지 기반 MVCNN 모델 구축
다중 이미지를 대상으로 3차원 형상을 학습하는 MVCNN 알고리즘을 활용하여 개별 BIM 부재의 유형을 자동분류하는 1차 학습모델을 구축하였다.
4단계: 기하 속성정보 및 관계정보 기반 MLP 모델 구축
기하 속성정보와 부재 간 물리적 관계정보를 학습한 MLP 모델을 구축하였다. 이때 물리적 관계정보는 3차원 경계상자(bounding box)를 활용하여 추출하였으며, 이를 TF-IDF 표현법을 적용하여 학습에 적합한 데이터 구조로 변환하였다.
5단계: 앙상블 모델 구축
BIM 부재별 기하 형상 이미지를 학습한 MVCNN 모델과 기하 속성정보 및 관계정보를 학습한 MLP 모델을 대상으로 앙상블 기법을 적용하여 최종 BIM 부재 자동분류 학습모델을 구축하였다.
6단계: 분류 결과 비교 및 검증
상기 과정을 통해 구축한 앙상블 모델(MVCNN + MLP)과 단순 이미지만 학습한 MVCNN 모델의 성능을 비교 분석하였다. 이를 통해 이미지 데이터 기반 학습의 한계점 개선을 위한 관계정보 및 기하 속성정보 활용의 효용성을 검증하였으며, 추가로 활용 방향을 제시하였다.
2. 선행 연구 및 이론 고찰
2.1 IFC 기반 BIM 데이터 운용 문제점 및 관련 연구 동향
IFC는 기본적으로 XML을 표현방법으로 채택하며, 건축물을 객체지향 방식으로 분석하고 있어 건축물의 구성요소 객체와 그 객체들의 연관 관계로 구성되어 있다. 이러한 관계들을 효과적으로 표현하기 위하여 IFC는 데이터 모델링 표준 언어인 EXPRESS 기반으로 표기되어 있으며(Hwang et al., 2012), EXPRESS 언어는 개방형 데이터의 표준 모델링 언어로 데이터를 다루는 많은 분야에서 활용되고 있다. 이를 통해 개방형 데이터 형태로 활용이 가능하며, 객체의 방대한 정보 운용함에 있어서 제한이 없게 되어 여러 BIM 소프트웨어에서도 활용 가능하다(Kim et al., 2012).
IFC는 객체 간 관계를 별도의 추상적인 클래스(IfcRelationship)로 표현하는 것이 특징이다. 그러나 IFC와 개별 BIM 소프트웨어에서 정의하는 객체의 정보 형태가 서로 상이하여 데이터 상호 운용 시 무결성이 확보되지 않는 문제가 발생한다. 일례로 벽체(wall)와 문(door) 부재가 물리적으로 인접해 있다는 관계정보는 IfcRelvoidsElement, IfcRelFillsElement 등의 IFC 엔티티에 의해 표현된다. 이는 상용 소프트웨어의 데이터베이스 모델을 수용할 수 있는 유연성을 제공하지만, IFC 내 정의되지 않거나 특수한 속성정보의 경우 모두 IfcPropertySet 엔티티로 표현되며, 결국 데이터 표현의 중복성 문제가 발생하게 된다(Lee et al., 2009). 또한, 앞서 언급하였듯이 IFC는 엔티티 간 추상적인 관계를 정의하는 방식이지만 상용 BIM 소프트웨어는 직접적인 관계 정의를 통해 모델을 구축하고 있다(Khemlani, 2004).
따라서 BIM 데이터의 이종 소프트웨어 간 상호운용성 확보를 위해서는 IFC 변환 시 발생하는 데이터 무결성 문제해결이 필수적이다. 이는 개별 BIM 객체와 IFC 엔티티 간 데이터 매핑이 올바른지 검증하는 시멘틱 강화를 통해 해결할 수 있으며, 과거부터 유관 연구들이 다수 수행되었다.
2.1.1 규칙기반 시멘틱 강화 선행연구 고찰
시멘틱 강화 연구는 과거에 규칙기반 접근법이 주를 이루었으나, 최근에는 기계학습 접근법이 점차 많아지는 추세이다. 여기서 규칙기반 접근법은 일련의 추론적 규칙(inference rules)를 사전에 정의하고, 이들 규칙을 활용하여 시멘틱 무결성(semantic integrity)을 검증하는 방식을 의미한다.
일례로, Park and Jeong. (2010)은 다양한 분야가 협업하는 AEC 산업의 특성을 고려하여, 데이터 호환을 위한 BIM 정보 내 시멘틱 정보를 생성 및 부여하는 온톨로지(ontology) 기술과 필터를 통해 특정 데이터를 검색 가능한 새로운 데이터 표현 방법론을 제시하였다.
Wang et al. (2015)은 레이저 스캐너를 통해 완공된 건축물의 점군(point cloud) 데이터를 취득하고, 이를 규칙기반 접근법으로 해당 건축물을 구성하고 있는 부재 유형(창문, 문, 벽, 천장 등) 분류에 성공하였다.
Cursi et al. (2017)은 ‘S-ENr BIM‘ 시스템을 구축하여 BIM의 시멘틱 강화 접근법으로 BIM 환경과 온톨로지 기반의 지식 베이스 간 매핑, 비교, 데이터 전송할 수 있게 하였다. 그러나, 규칙기반 접근법은 규칙을 일일이 정의해야 하는 특성으로 인해 확장성에 제한이 있으며, 이러한 한계를 개선하기 위해 기계학습 접근법이 활용되었다.
2.1.2 기계학습 기반 시멘틱 강화 선행연구 고찰
기계학습 접근법은 부재의 기하 속성정보, 2차원 이미지 혹은 3차원 형상을 학습데이터로 활용하여 기계학습 알고리즘을 학습시키는 방식으로 사전에 학습되지 않는 부재라도 구분할 수 있기 때문에 확장성에서 상대적으로 강점을 갖는다. 특히 최근에는 컴퓨팅 기술의 발전에 따라 이미지, 3차원 형상을 활용하는 연구가 활발히 진행되고 있으며 그 정확도 또한 우수한 것으로 조사되었다.
Bienvenido-Huertas et al. (2019)은 건축 부재 중 바닥 타일의 치수, 위치, 체적, 색채 등의 특성을 J48 알고리즘에 학습시켜, 문화유산 건축물의 타일 유형을 자동으로 분류하는 연구를 수행하였다.
Ajayakumar, (2021)는 3차원 형상정보와 기하학적 복잡성을 학습하는 딥러닝 알고리즘을 기반으로 BIM 부재의 LOG (Level of Geometry) 수준을 자동으로 평가하고 감지하는 프레임워크를 구축하였다.
이외에도 최근 점군(point cloud) 데이터를 인공지능 모델에 학습시켜 부재를 분류하는 연구가 진행된 바 있다. Shen, (2020)은 3D 공간 모델을 점군 데이터로 변환하고 이를 PointNet 알고리즘에 학습시킴으로써 부재 유형 분류를 위한 적합한 점군 밀도를 탐색하였다. 그러나 점군 데이터 활용 시 특징점 탐색 난이도가 높아 분류 정확도가 73%에 그치는 것으로 조사되었다. 이와 유사하게 Koo et al. (2021)은 개별 BIM 부재를 대상으로 다중 이미지 기반의 MVCNN 모델과 점군 데이터 기반의 PointNet 모델로 각각 학습하여 그 성능 차이를 비교 분석한 사례가 있다. 본 사례에서도 점군 데이터 활용 시 정확도가 상대적으로 저조한 것으로 확인되었으며, 이에 따라 본 연구에서도 다중 이미지 기반의 MVCNN 모델을 기본 활용 알고리즘으로 채택하였다.
그러나 기존 이미지 데이터 기반 연구들의 높은 분류 정확도에도 불구하고, 개별 부재의 기하학적 특징들만 학습하여 형상이 유사한 부재들을 구별하는데 어려움이 존재하였다. 이에 개별 부재 간 관계를 표현하는 위상정보를 학습 과정에 활용하는 연구가 등장하였다(Koo et al., 2018). 여기서 위상정보는 관계정보, 3차원 위치 관계, 위상 공간 등 객체 간 연결된 정보를 의미하며 이 중 관계정보를 활용하는 연구가 가장 활발히 진행되고 있다. 관계정보를 추가 특성변수로 활용함으로써 기존 객체가 보유한 특성을 부각시킬 수 있으며 이는 기하 속성정보 기반 모델의 분류 성능을 향상시킬 수 있는 것으로 검증되었다(Yu et al., 2021). 즉, 관계정보가 표현하는 공간적 맥락(spatial context)은 단순히 부재의 기하 정보만 활용할 때 보다 객체의 특징을 강하게 표현할 수 있다(Ma et al., 2017).
그러나 상기 연구들은 BIM 모델을 구성하는 모든 부재 간 관계를 반영하지 못했다는 한계점이 있으며, 관계정보 데이터를 수동으로 추출함에 따라 데이터 구축 시간 증가 및 휴먼 에러에 따른 신뢰도 하락 문제를 해결하지 못하였다. 또한, 관계정보를 추출하는데 개별 객체의 관계를 추상적으로 표현하는 IFC 엔티티를 활용함에 따라 모든 부재 간 관계정보를 추출하지 못하였다. 이에 본 연구는 3차원 경계상자(bounding box) 기반 부재 간 물리적 관계정보 추출 방법론을 고안하여 관계정보 데이터 구축 시 발생하는 문제들을 해결하고자 하였다.
2.2 분류에 활용되는 인공지능 알고리즘
앞서 소개한 바와 같이, 본 연구에서는 BIM 모델에서 추출한 3가지 종류의 데이터(부재 별 이미지, 기하 속성정보, 관계정보)를 한 개의 단일 모델로 학습하기 위해서 MVCNN, MLP 알고리즘 기반의 앙상블 모델을 구축하고자 하였다. 본 장에서는 이들 알고리즘의 레이어 구조와 이를 활용한 이유를 제시하였다.
2.2.1 Multi-View Convolutional Neural Network
MVCNN은 3차원 기하 형상을 인식하는 대표적인 기하 딥러닝 모델(geometric deep learning)중 하나이다. MVCNN은 3차원 객체를 다각도에서 촬영한 다중 2D 이미지를 학습하여 해당 객체를 분류하는 알고리즘으로(Su et al., 2015), 여타 3차원 인식 딥러닝 알고리즘 대비 뛰어난 분류 성능을 보여준다. VoxNet (Maturana and Scherer, 2015), PointNet (Qi et al., 2017) 등은 3차원 객체 인식을 위해 우선적으로 모델을 큐브 형태의 복셀화(voxelization) 및 다면체로 구성된 폴리건 메쉬(polygon mesh) 등의 형태로 변환하는 별도의 전처리 과정이 필요하다. 이 경우 데이터의 크기가 대폭 증가하거나 세부 특징점들이 소실되는 문제가 발생하기 마련이다. 이에 비해 MVCNN은 높은 해상도의 2D 이미지를 활용하기에 형상 디테일의 소실이 없고, 2차원 픽셀 기반의 데이터를 쓰기 때문에 높은 분류 성능을 유지한다.
Koo et al. (2021)은 MVCNN을 건축 BIM 부재 분류에 활용 가능한 것을 입증하였고, 대부분 부재에 대해 높은 성능을 제시하였다. 그러나 일부 형상이 유사한 부재들의 경우, 즉 천장(covering), 바닥(slab) 또는 얇은 벽(wall)과 두꺼운 기둥(column) 등은 분류오류가 여전히 존재하는 한계가 있었다(Table 1 참고).


이는 객체의 형상만을 학습에 활용하는 MVCNN 특성상 유사한 형상을 보유하고 있는 객체 간 차이점을 구분하기 어렵기 때문이다. 또한, 단일 딥러닝 모델을 기반으로 분류를 수행한다는 점에서 필연적인 데이터 편향 문제가 발생한다(Eom et al., 2020).
2.2.2 Multi-Layer Perceptron
MLP는 대표적인 딥러닝 모델이자 가장 기본적인 인공신경망(artificial neural network)의 일종이다. MLP의 가장 기본 구조는 단일 퍼셉트론(single-layer perceptron)으로 데이터를 받는 입력층(input layer), 결과값을 출력하는 중간층(hidden layer), 그리고 결과값을 전달하는 출력층(output layer)으로 구성되어 있으며, 각 층 사이에는 가중치(weight)들의 곱을 모두 더한 뒤 활성화 함수(activation function)을 적용하여 임계점에 따라 하나의 결과를 출력한다.
단층 퍼셉트론은 선형 분류만 가능하다는 한계점이 존재하여 보다 진일보한 다층 퍼셉트론(Multi-Layer Perceptron, MLP)을 사용한다. 다층 퍼셉트론은 입력층과 출력층 사이에 하나 이상의 중간층인 은닉층을 두어, 입력된 정보가 은닉층에서 새로운 값으로 변환되는 과정을 거쳐 출력층으로 전달되는 구조를 가지고 있다(Figure 1 참고).
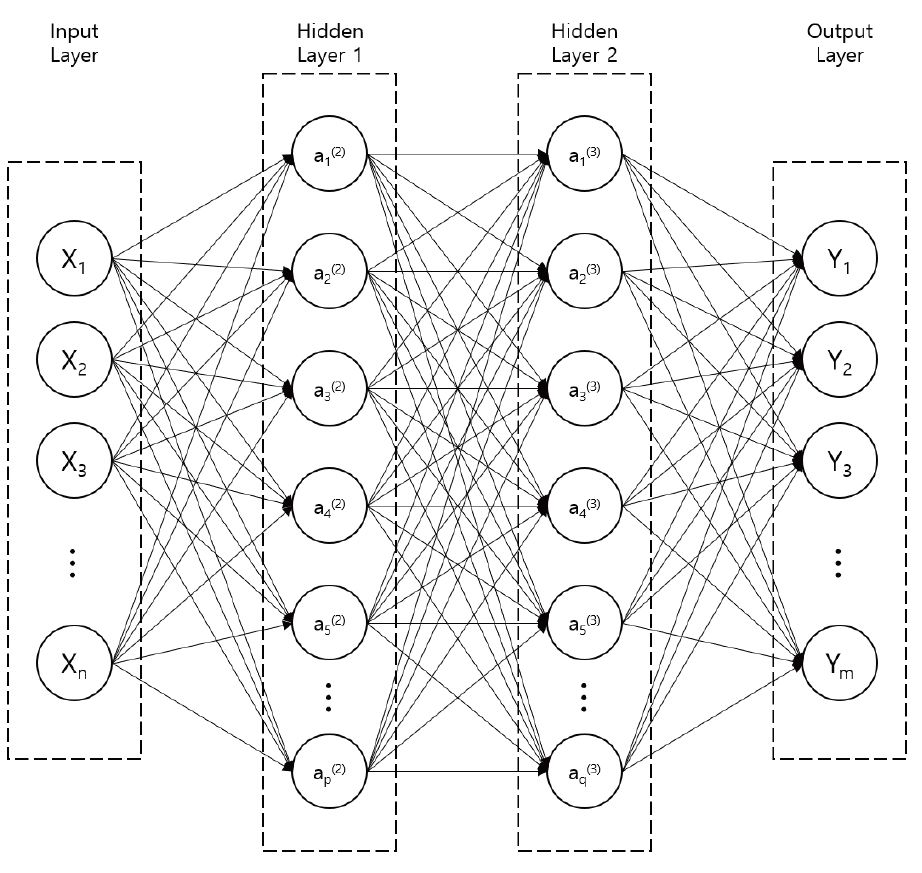
MLP의 출력층에 적용하는 활성화 함수에는 항등함수(identity function)와 softmax 함수를 활용한다. 항등함수는 입력값을 그대로 출력되는 구조로 분류가 필요하지 않은 회귀문제에 활용된다. 반면 softmax는 2개 이상의 다중 클래스 분류에서 주로 사용되는 활성화 함수로 계산식은 식 (1)과 같다. 클래스의 총 개수를 m라고 할 때, m차원의 벡터를 입력받아 각 클래스에 대한 확률을 추정하여 출력한다. 즉, 각 입력의 지수함수를 정규화하여 출력하고 모든 출력의 합은 반드시 1이 된다는 특징을 갖는다.
MLP는 각 층 사이의 뉴런이 모두 연결된 Fully connected network 이란 점에서 CNN 및 RNN과 같은 딥러닝 모델과 구분된다. 또한, 지역 특성(region feature)을 학습하는 CNN과 달리 MLP는 특성변수를 설계자가 선정할 수 있다는 점에서 구별된다. 본 연구에서는 위상정보 중 부재 간 물리적 인접 여부를 나타내는 관계정보와 부재의 기하 정보를 특정 변수로 사용하고자 하기에 본 목적에 부합하는 모델로 활용하였다.
2.2.3 앙상블 학습
앙상블 학습(Ensemble Learning)은 다수의 알고리즘 모델들의 예측값들을 이용하여 더 정확한 분류 성능을 이끌어내는 결정기법이다. 앙상블 학습의 핵심은 단일 분류기만으로는 데이터 편향 및 비대칭 문제로 학습이 어려운 데이터들을 여러 개의 하위분류기로 나누어 학습함으로써 단일 분류기보다 정확한 예측 결과를 도출해내는 것이다(Dietterich, 2002).
1) 앙상블 구축 기법
앙상블 학습방법에는 단일 알고리즘으로 병합하는 앙상블 구축기법과 개별 알고리즘의 결과값을 병합하는 분류기 결합기법이 있다(Rokach, 2010).
앙상블 구축기법은 배깅(bagging), 부스팅(boosting), 스태킹(stacking)과 같이 여러 분류기 단계를 거치며 특정 결과에 가중치를 계산하여 최종 분류 결과를 추론하는 방식이다(Polikar, 2006).
이에 비해 결합기법은 다른 두 개 이상의 분류기의 결과를 특정 연산 기준으로 가중치를 주어 분류하는 방식으로 보팅(voting) 또는 대수 결합(algebraic combiners)방식 등이 존재한다. 보팅은 개별 알고리즘들의 결과에 대해 투표로 최종 결과를 예측한다. 보팅에는 다수결의 원칙을 따르는 하드 보팅(hard voting)과 각 알고리즘의 레이블 결정확률을 평균 내어 가장 높은 레이블을 최종값으로 예측하는 소프트 보팅(soft voting)으로 나눌 수 있다. 대수 결합방식은 개별 분류기의 결과들을 간단한 함수(평균, 총합, 최댓값, 최솟값 등)로 최종 결정한다(Table 2 참고).
2) 앙상블 기법 적용 사례
앙상블 기법을 통해 기계학습 알고리즘들을 병합하여 최적의 학습모델을 구축한 연구 사례는 다수 존재한다. Xu et al. (2021)은 도시의 기능에 따른 영역 분할 및 인식을 수행하기 위해 지형, 도로, 애플리케이션 체크인 기록, 인구 밀도와 같이 이종 데이터를 각각 적합한 알고리즘에 학습시킨 뒤, XGBoost 앙상블 학습을 통해 최적의 학습모델을 구축하였다.
Eom et al. (2020)은 기업의 부도 위험을 예측하는 모델을 구축하고자 의사결정나무(random forest), MLP, CNN 알고리즘 간 스태킹 앙상블 학습을 수행하였다. 이는 기업의 부도 위험을 나타내는 다양한 정보를 단일 모델로 학습 시 발생하는 편향 문제를 줄이는 동시에 데이터 간의 비선형적 관계들을 포착할 수 있다. 특히 앙상블 기법을 통해 각 서브 모델의 편향을 줄이는 동시에 단일 모델에서 가장 우수한 성능을 보인 의사결정나무 모델의 예측값을 상회하는 결과를 도출하였다.
마찬가지로 본 연구에서 제안한 MLP와 MVCNN의 앙상블은 주로 다수의 기계학습 알고리즘을 사용하는 보편적 앙상블 기법과 달리 2개의 딥러닝 모델로 구성된 앙상블이며, 각 모델이 학습하는 데이터의 형태가 상이하여 특징점이 다를 수 있다.
따라서 본 연구에서는 각각의 하위 모델에서 데이터 인스턴스들이 갖는 softmax를 비교하여 최댓값을 갖는 레이블로 최종결정하는 대수 결정기법을 활용하였다.
Table 2.
Ensemble method (Polikar, R., 2006)
| Algorithm | Method | Rule |
| Ensemble | Creating an Ensemble | Bagging |
| Boosting | ||
| Stacking | ||
| Combining Classifiers | Soft voting | |
| Hard voting | ||
| Algebraic combiners |
3. 연구 방법
본 연구는 개별 BIM 부재를 인공지능 기반으로 자동 분류하는 목적을 기본으로 하고 있다. 특히 부재의 기하 이미지 기반으로 학습하는 MVCNN의 한계를 보완하고자 딥러닝 모델인 MLP를 별도로 학습시키고 이후 MVCNN과 MLP의 예측 결과를 병합시키는 앙상블 모델 구축을 목표로 하였다. MLP 모델에는 위상정보 중 부재 간 관계정보를 추가로 학습시켜 개별 부재의 전체 형태 이미지만으로 학습하는 MVCNN의 단점을 보완하는데 역점을 두었다. Figure 2에는 전체 연구 프로세스를 제시하였으며 세부 범위 및 방법은 다음과 같다.
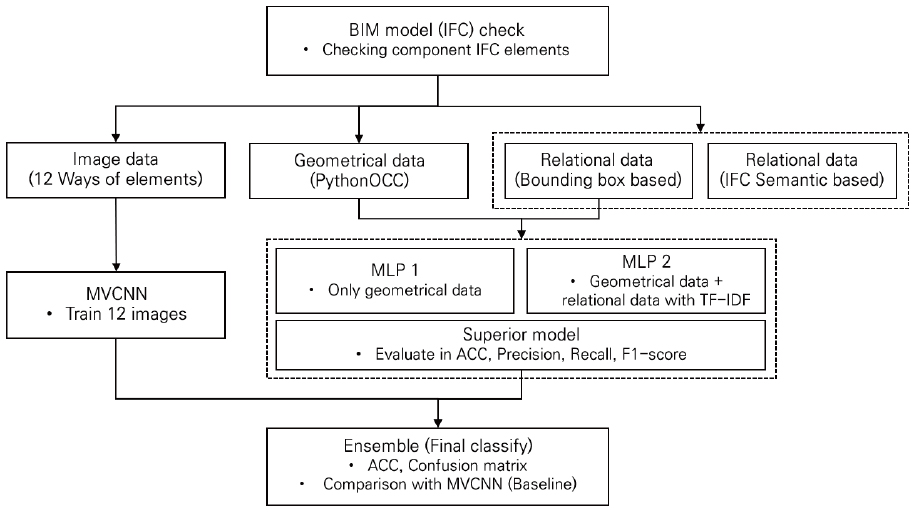
3.1 활용 BIM 데이터 개요
활용 데이터는 건축설계사무소에서 제공하는 20층 규모의 건축 BIM 모델을 대상으로 삼았다(Figure 3 참고). 해당 BIM 모델을 구성하고 있는 부재 중 건축 분야에서 활용도가 높은 8개의 IFC 엔티티(beam, column, covering, door, railing, slab, wall, window)를 분류대상으로 구성하였다. 이 중 문(door)의 경우 동일한 유형이라도 형상 및 활용도가 다르기 때문에 기타문(door etc.), 이중문(double door), 단일문(single door)로 세분화하였으며, 최종적으로 10개 부재 유형의 총 11,459개 부재가 연구 대상으로 활용되었다(Table 3 참고).

Table 3.
Dataset for learning model training
| Type | Beam | Column | Covering | Door etc. | Double door |
| Image |  |  |  |  |  |
| No. of element | 1,247 | 586 | 286 | 191 | 108 |
| Type | Railing | Single door | Slab | Wall | Window |
| Image |  |  |  |  |  |
| No. of element | 9 | 450 | 1.394 | 7,086 | 102 |
| Total | 11,459 | ||||
3.2 학습모델 구축 및 학습 방법
상기 데이터를 기반으로 MVCNN, MLP를 학습 및 훈련시키기 위해 7:3의 비율로 구분한 학습 데이터세트를 구축하였다. MVCNN은 이들 부재의 이미지 데이터, 그리고 MLP는 이들의 기하 속성정보와 관계정보를 기반으로 학습시켰다.
이때, 관계정보를 BIM 모델로부터 추출하는 두 가지 방법을 비교 분석하여 이 중 제반 관계를 일관되게 표현하는 방식을 선정하였다. 또한, 관계정보의 학습 효과를 파악하기 위해 MLP는 기하 속성 기반 모델(MLP_1) 및 기하 및 관계정보 기반 모델(MLP_2)로 학습을 구분하여 성능 분석을 실시하였다. 이 중 성능이 가장 높은 MLP 모델과 학습된 MVCNN 모델을 병합하여 앙상블 모델을 구축하고, 이에 대한 검증 결과를 제시하였다.
3.3 학습모델 평가 방법
최종적으로 구축된 앙상블 모델의 성능 평가를 위해 MVCNN 모델과 앙상블 모델 간 분류 정확도와 confusion matrix 비교를 통해 평가하였다. 이후 분류 정확도가 향상된 부재와 오분류된 부재들을 확인하여 원인분석 및 시사점을 도출하였다.
구축되는 개별 모델의 평가는 보편적으로 많이 활용되는 4가지 성능지표인 정확도(accuracy, 이하 ACC), 정밀도(precision), 재현율(recall), 1)를 활용하였다. 또한, 임계값(threshold)에 따른 정밀도와 재현율의 변화를 확인하기 위해 precision-recall curve를 활용하였다. Precision-recall curve는 일반적으로 이진분류 모델 평가에 활용된다. 이에 본 연구는 다중 클래스분류이므로 softmax 값으로 출력되는 각 인스턴스의 결과를 이진화(binarize)한 뒤, 클래스별 그래프를 구축하였다(Su et al., 2015). 단, 앙상블 모델은 최대값에 기반하여 최종 분류 결과의 softmax 값만 도출이 가능하다. 따라서, 임계점에 따라 변하는 재현율과 정밀도를 계산할 수 없으므로 precision-recall curve를 도출할 수 없다.
다음 4, 5, 6 장에서는 이들 BIM 부재들을 기반으로 MVCNN, MLP 및 앙상블 모델을 학습시킨 방법과 각 모델의 결과에 대해 제시하였다.
4. MVCNN
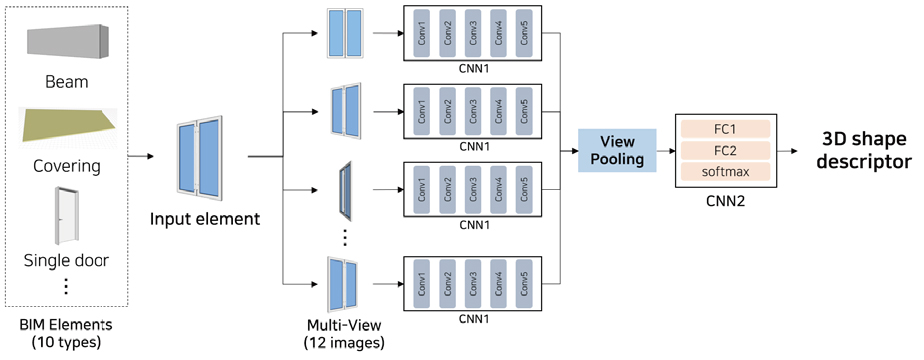
4.1 MVCNN 학습모델 구축
본 연구에서 구축한 MVCNN 모델의 구조를 Figure 4에에 제시하였다. 대상 부재에 대해 다각도로 촬영한 2D 이미지 데이터를 각각 개별 CNN()에 적용하여 데이터의 특징 패턴을 추출하고, 추출된 모든 패턴들은 view-pooling 층을 통해 통합된다. 이후 fully-connected 층과 softmax 층으로 구성된 를 거쳐 최종 분류한다. 이때 MVCNN에 활용된 CNN은 5개의 convolution 층과 2개의 fully-connected 층, 마지막으로 최종 softmax 분류층으로 구성된 VGG-M 모델을 활용하고 있다.
4.2 기하 형상 이미지 데이터 구축
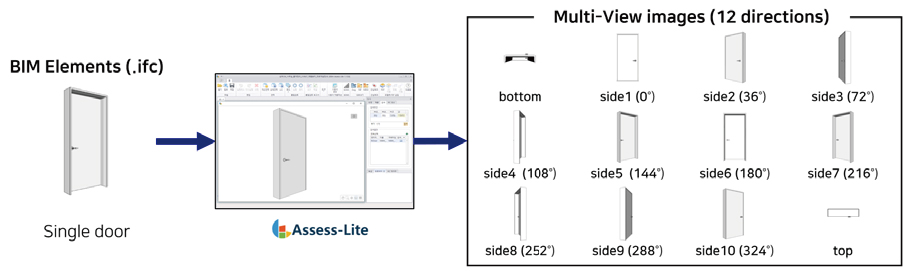
부재의 기하 형상 이미지를 학습하는 MVCNN 알고리즘 구축을 위해 상용 설계품질 평가 프로그램인 KBim Assess-Lite를 활용하여 개별 부재를 다각도(밑면, 측면 36° 간격으로 10장, 윗면)에서 촬영한 12개의 2D 이미지 데이터로 구축하였다(Figure 5 참고).
구축한 2D 이미지 데이터를 7:3의 비율로 나누어 훈련(train)과 검증(test)을 진행하였다. 최종적으로 MVCNN 알고리즘 학습에 8,021개의 부재에 대한 12방향 이미지 96,252개와 검증에 3,438개 부재에 대한 41,256개로, 총 137,508개의 2D 이미지 데이터가 활용되었다(Table 4 참고).
Table 4.
Training and test set for MVCNN
4.3 학습결과
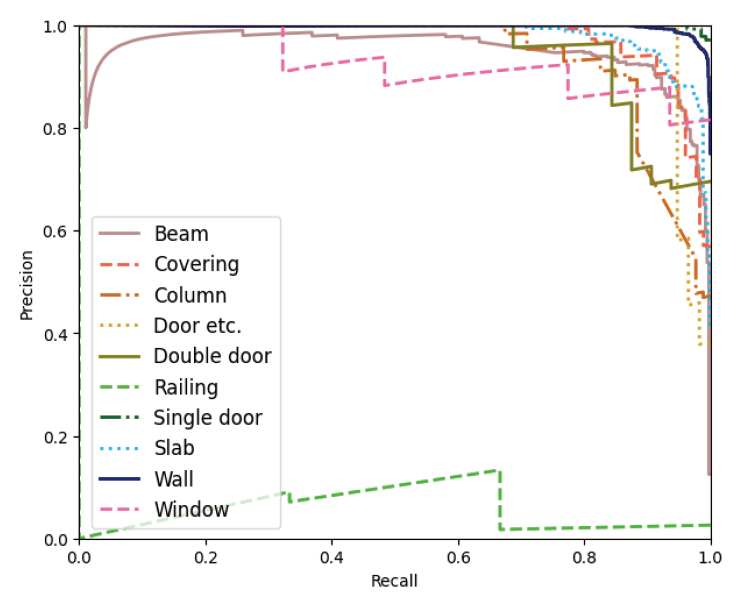
Table 5는 MVCNN 모델의 학습결과를 나타내며, Figure 6는 MVCNN 모델의 precision-recall curve를 나타낸다. MVCNN 모델의 ACC는 0.93이며, 는 0.82로 도출되어 전반적으로 양호한 성능을 보였다. 그러나 난간(railing)의 경우 모두 오분류한 문제가 있으며, 천장(covering)의 ACC 또한 0.71로 저조한 것을 볼 수 있다.
난간의 경우 검증(test) 세트에 3개 밖에 없어 데이터 불균형에 기인한 것으로 보인다. 천장의 경우 총 86개 중 17개를 바닥(slab)으로 오분류한 것을 볼 수 있다(Table 6 참고). 이는 천장과 바닥의 기하학적 형상 차이가 거의 없는 것에 기인하는 것으로 판단하였다.
이처럼 MVCNN은 기하 형상이 특이한 부재를 분류하는데 우수한 성능을 보였으나, 학습 개수가 적거나 기하 형상이 유사한 경우에는 적절히 분류하지 못하며 이는 앞서 2.2.1절에서 언급한 바와 같이 이미지 데이터 기반 분류모델의 한계로 볼 수 있다.
Table 5.
Validation results for MVCNN
Table 6.
MVCNN classification results (confusion matrix)
5. MLP
5.1 MLP 학습모델 구축
3장에 언급한 바와 같이 MLP 모델은 학습 과정에 기하 속성정보와 관계정보를 활용한다. MLP는 변수 설정이 가능한 딥러닝 모델이므로 우리가 원하는 특정 기하 속성과 관계정보를 특성변수로 지정해 줄 수 있다.
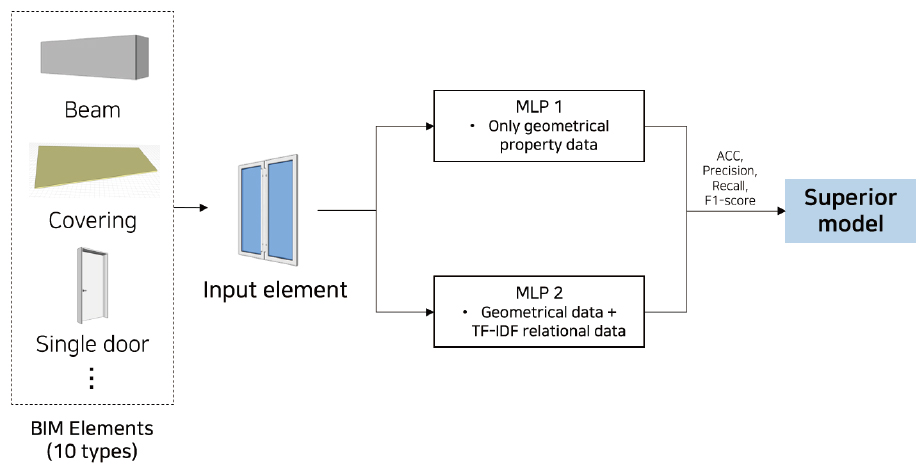
단, 모델 학습 과정에서 관계정보 활용의 효용성을 확인하기 위해 (1)단순 기하 속성정보만을 활용하여 학습한 모델(MLP_1)과 (2)기하 속성정보와 관계정보를 모두 활용하여 학습한 모델(MLP_2)로 각각 구축하여 성능 비교를 우선적으로 실시하였다(Figure 7 참고). 이때, 본 연구에서 수집한 관계정보는 TF-IDF 형태로 변수화하여 학습에 활용하였다.
MLP 모델의 네트워크 구조는 1개의 입력층(input layer), 98개의 은닉층(hidden layer), 1개의 출력층(output layer)으로 총 100개의 층으로 구성하였다. 이때 은닉층이 깊어질수록 과적합(overfitting) 현상으로 인해 성능이 오히려 떨어질 수 있으므로, 최적의 은닉층 개수는 여러 번의 하이퍼 파라미터(hyper-parameter) 튜닝 실험을 통해 도출하였다. 각 은닉층의 활성화 함수(activation function)는 ReLU (Rectified Linear Unit), 가중치(weight) 최적화를 위한 solver는 adam, 출력층의 활성화 함수는 softmax를 사용하여 구축하였다.
MLP 모델은 python 기반의 오픈소스 라이브러리인 scikit-learn package로 구현하였다.
5.2 기하 속성정보 데이터 구축
3.1절에서 제시한 수집 BIM 부재를 7:3 비율로 분할하여 학습데이터 세트를 구축하였다. 따라서 학습에는 8,021개, 검증에는 3,438개가 활용되었다(Table 7 참고).
개별 부재의 기하 속성정보 추출을 위해서는 python 오픈소스 라이브러리인 PythonOCC (Krijnen, 2015)를 활용하였다. 본 프로그램을 통해 개별 부재로부터 기하 속성정보(면적, 부피, 회전반경, 면적 대비 체적 비율, 회전 반경 대비 체적 비율 값, 객체의 3차원 경계상자 넓이, 폭, 높이)를 추출하였다(Table 8 참고). 이들 특성변수는 기존 연구에서 BIM 부재를 분류하는데 유효성이 높은 것으로 검증된 바 있다(Koo et al., 2018).
Table 7.
Training and test set for MLP
Table 8.
MLP Training property features
5.3 부재 간 관계정보 데이터 구축
부재 간 관계정보는 개별 부재가 다른 부재와 특정 연관을 갖고 있는지 여부를 의미한다. BIM 모델 내 부재는 여러 형태로 타 부재와 연관성을 가지며, 이는 연결(connected to), 포함(enclosed by), 지지(supported by) 등 다양한 시멘틱 관계를 가지고 있다(Koo and Fischer 2000).
본 연구에서는 이러한 연관성이 부재 유형별로 다르기에 이들의 정보가 개별 부재의 특성으로 활용할 수 있을 것으로 판단하였다. 일례로, 바닥(slab)은 문(door)과 인접 관계가 있지만, 천장(covering)은 본 관계가 성립하지 않을 것이다. 따라서, 이러한 관계상 차이를 활용하여 분류 성능을 높이고자 하였다.
부재 간 연관 관계 추출을 위해서는 두 가지 방식, 즉, (1) IFC 내 추상 클래스(abstract class)로 정의된 객체 간의 인접 관계를 활용하는 방법과 (2) 개별 객체의 3차원 경계상자(bounding box)를 활용하는 방법을 선정하였으며, 이 중 본 연구에 적합한 방식을 채택하였다.
1) IFC 시멘틱 관계를 활용한 추출
IFC는 BIM 모델의 개별 부재를 엔티티로서 객체화(object)하는 동시에 부재 간의 관계도 별도의 엔티티 또는 클래스로 객체화한다. 최상위에는 IfcRelationships 이라는 추상 클래스가 있으며, 세부적 관계유형에 따라 종류와 의미가 다른 다수의 하위 엔티티로 구성되어 있다. 일례로 벽체(wall)와 창문(window) 혹은 문(door)의 관계는 IfcRelVoidsElement - IfcOpeningElement – IfcRelFillsElement의 3가지 추상 엔티티를 매개로 벽체 안에 창문 혹은 문이 존재한다는 관계를 시멘틱하게 표현하게 된다. 이들 관계 엔티티를 기반으로 특정 부재의 연관 관계를 추출하고자 하였으며, 본 연구에서 분류를 목표로 하는 각 부재별로 연관 관계를 표현한 세부 관계 엔티티를 분석하였다.
그러나 추상 클래스는 요구되는 제반 부재 간 물리적 인접 관계를 명확히 추출하지 못한다는 한계점이 존재하였다. 대부분 부재의 경우, IfcRelContainedInSpatialStructure, IfcRelSpaceBoundary의 추상 엔티티를 통해 단순히 동일한 층(level) 및 공간(space)에 종속되어 있다는 관계만 추출 가능하였다. 또한, IFC의 문제점 중 하나인 중복표현으로 인해 관계정보가 일관되게 표현되지 않는 문제도 존재하였다(Eastman et al., 2009). 일례로, 커튼월(curtainwall)과 문의 관계는 3가지 추상 엔티티를 통해 표현되는 기존 벽체와 창문 혹은 문의 관계와 달리 IfcRelAggregates라는 1개의 추상 엔티티를 통해 관계가 표현된다. 즉, 필요 유형에 따라 객체 간의 시멘틱 관계정보를 추출이 가능하지만, 본 연구에서 필요로 하는 모든 부재 간 물리적 인접 관계정보는 해당 방법으로 추출이 불가하였다.
2) 3차원 경계상자 기반 관계정보 추출
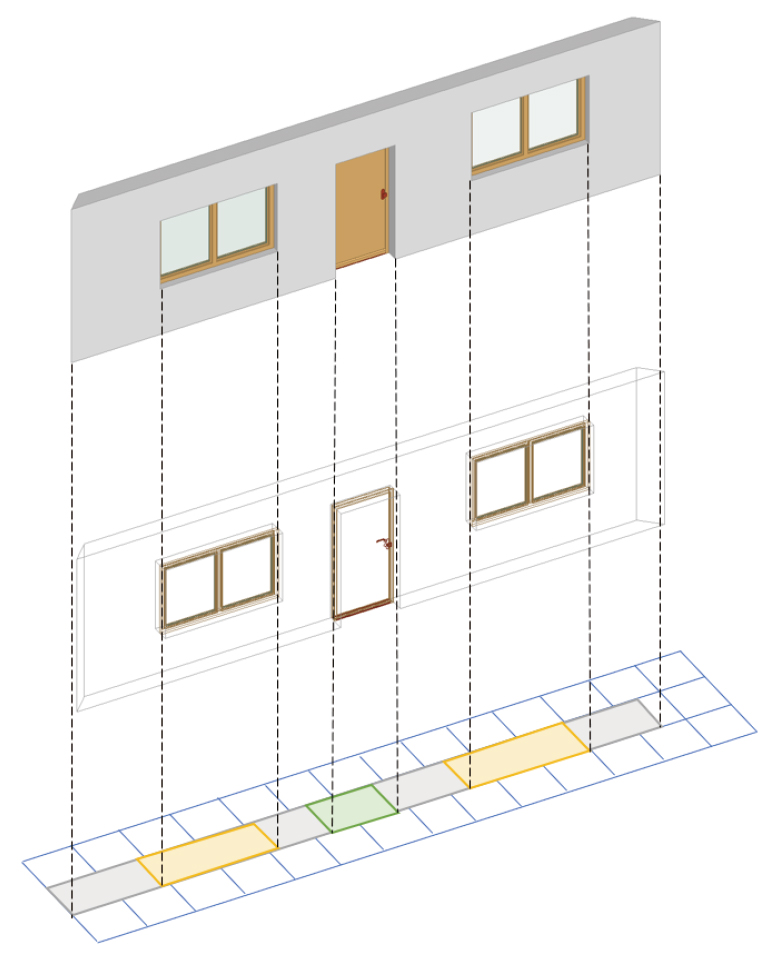
두 번째 방식은 BIM 모델 내 특정 부재 간 물리적 인접 여부를 파악하여 연관 관계를 도출하는 방식이다. 이 경우 개별 부재에 각각 3차원 경계상자(bounding box)를 씌운 후 이를 2D 평면에 투영시킨다. 이때 각각의 투영체가 중첩된다면 이들은 서로 인접해 있다는 관계를 확정시킨다.
일례로 Figure 8과 같이 벽체, 창문, 문의 3차원 경계상자를 형성 후 이를 2D 평면에 투영시키면, 벽체의 투영체에 창문와 문의 투영체가 겹치게 된다. 따라서 이들은 서로 연관 관계가 성립한다. 반면, 창문과 문의 투영체는 중첩되지 않기에 이들은 연관 관계가 존재하지 않는다.
본 방식으로 연관 관계를 도출할 경우, 요구되는 관계정보가 올바르게 추출되는 것을 확인할 수 있었다.
3) 소결
상기 두 방식 중 본 연구에서 필요로 하는 부재 간의 연관 관계 도출은 두 번째 방식이 더 적합한 것으로 드러났다. IFC 기반 방식은 관계의 유형을 다양하고 시멘틱적으로 정확하게 표현할 수 있는 장점이 있으나, 본 연구에서 필요한 제반 관계를 도출하기에는 부족하다. 반대로, 두 번째 방식은 연관 관계를 의미론적으로 세분화하여 표현할 수는 없지만, 본 연구에서 원하는 일률적 연결 관계를 도출하는데 더 적합하였다.
5.4 관계정보 학습데이터 모델링 방안
3차원 경계상자(bounding box) 기반으로 추출한 개별 부재 간 관계정보 데이터는 단순 물리적 연관 관계를 나타내는 형태의 데이터이다. 이러한 데이터 구조를 MLP 학습 과정에 그대로 적용할 경우 BIM 부재 GUID (Globally Unique Identifier) 별 관계정보를 일일이 명시해야 하며, 이로 인해 학습에 활용하는 특성변수의 수가 늘어남에 따라 모델의 분류 성능을 하락시키는 요인이 된다2). 따라서 관계정보를 모델학습에 적합한 분류 특성으로 활용하기 위하여 부재 단위가 아닌 부재 유형별로 변환하였다. 이후 특정 부재가 다른 부재 유형과의 인접 여부를 별도의 특성변수로 규정하였으며 이를 학습에 적합한 TF-IDF (Term Frequency – Inverse Document Frequency) 표현법으로 변환하였다(Figure 9 참고).
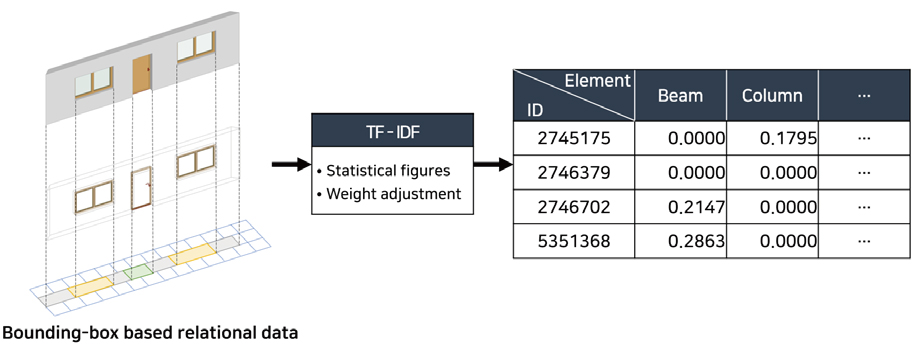
TF-IDF는 주로 텍스트 마이닝 분야에서 활용되는데 여러 문서에서 단어가 특정 문서 내 중요성을 계산하는 통계기반 기법으로 그 문서의 핵심 내용이나 주제를 파악하는데 활용된다(Ramos, 2003). 본 연구에서는 특정 부재와 인접해 있는 여러 타 부재 유형 중 해당 부재와 인접 빈도가 높은 부재 유형에 TF-IDF 값이 높아진다. 즉, 모든 관계정보 내 자주 등장하는 부재 유형은 중요도가 낮다고 도출되며, 특정 부재와의 관계에서만 자주 등장하는 부재는 중요도가 높게 추론된다. 일례로 벽체(wall) 부재는 대부분의 부재와 연결되어 있어 빈도수는 높지만 연결돼있는 부재 유형 역시 많으므로 TF-IDF 값이 낮게 도출된다. 따라서 부재 별 인접도를 기반으로 가중치를 조정하여 모든 유형 별 관계정보가 학습 과정에 반영될 수 있다는 특징이 있다.
상기 과정에서 구축한 관계정보 표현법의 성능 향상에 기여하는 정도를 확인하기 위해 단순 기하 속성정보만으로 학습한 모델(MLP_1)과 TF-IDF로 학습한 모델(MLP_2)을 구축하여 이들의 성능을 비교하였다.
5.5 MLP 모델 간의 결과 비교
관계정보 데이터를 학습한 모델의 성능 향상 정도를 검증하기 위해 학습데이터가 다른 MLP 모델별 ACC를 비교하였다(Table 9 참고). 그 결과, 부재 간 관계정보를 TF-IDF로 학습한 MLP_2의 ACC는 0.92로 나타났다. 즉, 개별 BIM 부재의 기하 속성정보와 TF-IDF 형태로 표현된 관계정보를 함께 학습한 MLP_2의 성능이 더 우수하였으며, 이는 단순 기하 속성정보만 학습한 MLP_1 대비 +0.04 향상된 수준이다. 이에 따라 MVCNN과 앙상블 기법을 진행할 모델은 MLP_2로 선정하였다.
Table 9.
Comparison for MLP models
| MLP_1 | MLP_2 | |
| ACC | 0.88 | 0.92 |
| Features | • Geometrical property | • Relational data represented using TF-IDF (i.e., Weight adjusted) |
5.6 MLP_2 모델의 학습결과
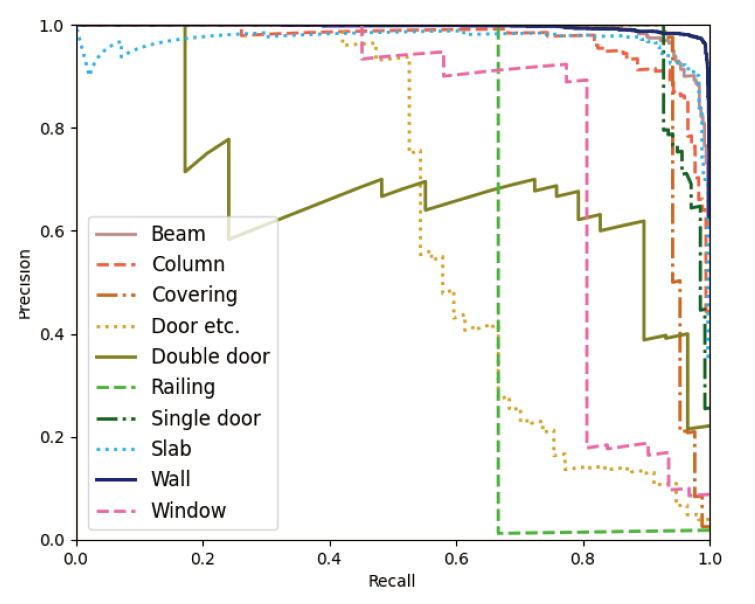
앞서 4장에서 구축한 MVCNN과 동일하게 분할된 데이터 세트를 MLP_2 모델에 학습하여, Table 10에 부재별 분류 성능과 Figure 10에 precision-recall curve를 제시하였다. MLP_2 모델의 ACC는 0.92, 는 0.73으로 도출되었으며, 특히 보(beam), 바닥(slab), 벽체(wall) 부재 분류에 높은 성능을 보였다. 그러나 기타문(door etc.), 이중문(double door), 창문(window) 부재는 상대적으로 낮은 분류 성능이 나타난 것을 확인하였다.
Table 10.
Validation results for MLP_2
개별 상세분류결과를 나타내는 Table 11의 confusion matrix를 보면, 기타문, 이중문, 창문 부재를 주로 벽체 부재로 오분류하였다. 이는 해당 부재들의 겉넓이, 부피와 같은 기하 속성정보가 균일하지 않으며 벽체 부재와 관계정보가 유사하기 때문에 분류에 어려움이 있는 것으로 판단된다.
일례로 기타문의 경우, 총 57개 중 22개를 벽체로, 3개를 단일문으로 오분류하였다. 이는 문의 특성상 벽에 포함되어있는 부재이기 때문에 관계정보 자체는 벽과 유사하다. 따라서 모델이 기타문을 분류하기 위해서는 기하 속성정보를 중점으로 분류해야 하지만, 기타문 부재의 속성정보가 균일하지 않아 모델이 해당 부재를 충분히 학습할 수 없었기 때문이다.
단, MVCNN 모델에서는 분류하지 못하였던 난간 부재를 경우 MLP_2 모델은 ACC 0.67 수준으로 분류하였다. 천장(covering) 부재의 경우 ACC가 0.79으로 MVCNN 대비 상대적으로 분류 성능이 높게 나왔다. 이처럼 MLP 모델은 관계정보를 통해 MVCNN 모델에서 분류하지 못하는 부재들의 인식을 상대적으로 잘할 수 있는 것으로 파악하였다.
Table 11.
MLP_2 classification results (confusion matrix)
6. 앙상블
6.1 앙상블 모델 구축
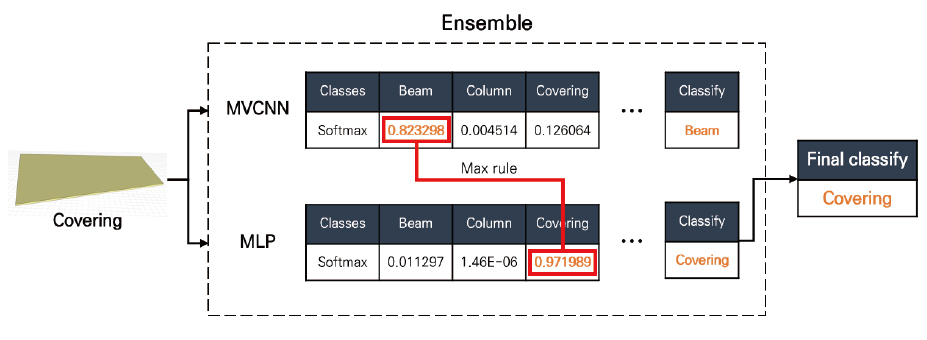
본 연구에서 구축하고자 하는 앙상블 모델은 대수결합법에 기반하였다. 즉, MVCNN과 MLP_2 두 모델 모두 개별 부재들을 대상으로 예측값을 출력하되, 두 모델이 각각 출력한 예측값 중 가장 높은 수치의 부재 유형으로 추론한다. Figure 11에 제시한 앙상블 모델 결정 과정의 예시를 보면, 특정 부재를 MVCNN은 0.82의 확률로 보(beam)로 예측하였고, MLP는 0.97의 확률로 천장(covering)으로 분류하였다. 이때 MLP에서 도출한 예측값이 MVCNN의 분류 예측값보다 높기 때문에 앙상블 모델은 MLP의 분류 결과를 수용한다. 이는 최댓값 규칙(max rule)에 기반한 병렬 접근법이라는 특징을 가지고 있다.
6.2 학습결과
MVCNN과 MLP_2을 병합한 앙상블 모델의 ACC는 0.95이며, 는 0.89로 도출되었다(Table 12 참고). 특히 보(beam), 단일문(single door), 바닥(slab), 벽체(wall), 창문(window) 부재 분류 성능이 우수하게 나타났다. 또한, Table 13의 부재별 상세분류결과를 살펴보면, 검증에 사용된 31개의 창문 부재를 모두 맞출 정도로 높은 ACC가 검측되었다.
그러나 난간(railing) 부재의 경우, MLP_2에서 0.67의 ACC가 도출되었으나, 앙상블 모델에서 0.33으로 하락하였다. 이는 MLP_2 모델이 난간으로 올바르게 분류한 일부 인스턴스의 softmax 값보다 MVCNN이 오분류한 softmax 값이 커서 앙상블 모델이 MVCNN의 분류 결과를 수렴한 것으로 확인되었다.
Table 12.
ACC of ensemble
Table 13.
Ensemble classification results (confusion matrix)
7. 종합 결과
앞서 구축한 모델별 분류 ACC를 살펴보면, MLP_2의 ACC는 0.92, MVCNN 모델의 ACC는 0.93, 앙상블 모델의 ACC는 0.95로 도출되었다. 즉, 앙상블 모델을 통한 분류 성능은 단순 이미지만으로 학습한 경우보다 +0.02(=0.95-0.93), 관계정보 및 기하 속성정보를 학습에 활용한 경우보다 +0.03(=0.95-0.92) 향상되었다(Table 14 참고).
세부적으로, 앙상블 모델의 부재별 ACC는 기타문(door etc.)을 제외한 9개 부재에서 성능 향상이 관측되었다. 특히 천장(covering)의 경우 MVCNN 대비 +0.16(=0.87-0.71)으로 성능 향상 수준이 높은 것으로 확인되었다. 즉, 기하 형상적 유사성으로 인해 MVCNN에서 적절히 분류하지 못하였던 천장과 바닥(slab) 부재를 앙상블 모델에서는 기하 속성정보와 관계정보가 학습된 MLP 모델을 활용하여 적절히 분류한 것으로 해석할 수 있다.
그러나 오히려 기타문 부재 분류에서는 MVCNN 대비 –0.14(=0.81-0.95)의 성능 하락이 나타난 것으로 확인되었다. 이러한 ACC 하락은 앙상블을 구성하고 있는 MLP_2 모델의 결과가 최종 분류 결과에 반영된 것으로 판단된다. MLP_2 모델은 기타문 부재를 주로 벽체(wall) 부재로 오분류 하였으며, 이는 기하 속성정보와 관계정보만으로는 이들 부재 간의 차이를 구분하기 어렵기 때문이다. 즉, MLP_2는 기하 속성정보와 관계정보가 유사한 부재들(기타문, 이중문, 창문, 벽체 등)을 분류하는데 어려움이 존재하여 앙상블 모델의 분류 성능 하락의 요인으로 작용하였다.
따라서, 앙상블 모델에서 개별 부재의 기하 형상 이미지를 학습하는 MVCNN은 문(door)의 세부 유형(기타문, 이중문, 단일문)과 같이 형상이 다양한 분류에 우수하고, MLP_2는 개별 부재의 관계정보 기반으로 기하 속성정보가 다른 이종 부재 분류에 유리하다.
Table 14.
Variation of models ACC
| Classes | MLP_2 | MVCNN | Ensemble | Variation* |
| Beam | 0.93 | 0.93 | 0.97 | ▲0.04 |
| Column | 0.88 | 0.85 | 0.89 | ▲0.04 |
| Covering | 0.79 | 0.71 | 0.87 | ▲0.16 |
| Door etc. | 0.53 | 0.95 | 0.81 | ▼0.14 |
| Double door | 0.66 | 0.81 | 0.88 | ▲0.07 |
| Railing | 0.67 | 0.00 | 0.33 | ▲0.33 |
| Single door | 0.88 | 0.98 | 0.99 | ▲0.01 |
| Slab | 0.92 | 0.97 | 0.99 | ▲0.02 |
| Wall | 0.94 | 0.94 | 0.95 | ▲0.01 |
| Window | 0.58 | 0.97 | 1.00 | ▲0.03 |
| Average | 0.92 | 0.93 | 0.95 | ▲0.02 |
8. 결론
본 연구는 부재의 기하 형상에만 집중하여 학습하는 기존 딥러닝 모델의 분류 한계점 개선을 위해 이종 데이터를 각각 딥러닝 알고리즘에 학습시킨 뒤 병합하는 앙상블 기반 접근법을 제시하였다.
우선적으로 부재 간 관계정보가 분류 성능 향상에 기여한다는 것과 이를 위한 학습 과정에 TF-IDF 표현법이 적합하다는 것을 검증하였다. 이후 해당 관계정보와 기하 속성정보를 학습한 MLP 모델과 기하 이미지 정보를 학습한 MVCNN 모델 간 앙상블 병합을 실시하였으며, 그 결과로 부재의 기하 형상 이미지에만 집중하는 MVCNN 모델 대비 분류 성능이 향상되는 것을 검증하였다. 기존 MVCNN 모델의 분류 성능이 준수하여 전체적인 성능 향상 정도는 미미하였지만, 기하 이미지 정보만으로는 분류오류가 나타나는 특정 부재의 분류 성능이 향상된 것을 확인하였다.
앙상블의 성능 향상을 이끌어내기 위해서는 앙상블을 구성하고 있는 MVCNN과 MLP_2 모델의 정확도 향상이 필수적이다. 이를 위해서 MLP_2 학습에 특성변수를 추가하는 방법이나 단일 모델들의 분류 레이블별 가중치를 주는 부스팅 기법을 적용하여 분류 성능을 향상시킬 수 있을 것으로 사료된다.
본 연구는 단순 기하 형상 이미지를 학습하는 모델의 성능 향상 방안을 검증했다는 측면에서 의의가 있다. 그러나 학습 과정에 개별 부재 간 물리적으로 인접한 관계정보를 활용하기 때문에 적용 범위가 단일 건축 BIM 모델에 제한되며, 이는 데이터 불균형 문제와 확장성에서 한계점으로 작용한다. 향후 이러한 한계점을 데이터 증강을 통해 해결하고, 이와 관련된 연구를 지속적으로 수행할 계획이다.
