

1. 서 론
1.1 연구의 배경 및 목적
1.2 연구의 범위 및 방법
2. 선행연구 분석
2.1 표준 속성 정의 및 데이터 모델 제시 연구
2.2 객체-내역(BOQ)매핑 및 규칙 연구
3. 실행내역 산출을 위한 객체 정보 요구사항 정립
3.1 공동주택 실행내역 산출을 위한 객체 데이터 모델링
3.2 공간 위계 기반의 속성 상속 모델
3.3 속성 입력 시스템
4. 객체-내역 연계형 데이터베이스 스키마 매핑 알고리즘
4.1 내역 연계를 위한 RDB스키마 설계
4.2 속성 기반의 조건부 매핑 메커니즘
4.3 수식기반의 동적 물량 산출 엔진
5. 시스템 구현 및 사례 검증
5.1 공동주택 프로젝트 적용 사례 분석
5.2 LH라이브러리 활용 프로젝트 적용 사례 분석
5.3 이종 BIM플랫폼에 대한 내역 연계 적용성 검증
6. 결 론
6.1 연구의 요약 및 시사점
6.2 향후 연구과제
1. 서 론
1.1 연구의 배경 및 목적
건설 프로젝트에서 정확한 원가 산정은 비용관리와 의사결정의 핵심 요소이며, BIM (Building Information Modeling) 기반 물량산출(QTO) 및 5D 비용 연계는 수량·비용 정보의 일관성과 추적성을 향상시켜 비용관리 성과를 개선할 수 있는 것으로 보고되어 왔다(Azhar, 2011). 이에 따라 BIM 객체 정보를 활용한 자동 물량산출 및 비용 산정 방법론의 연구가 시행되었다(Taghaddos et al., 2016; Valinejadshoubi et al., 2024). 그러나 기존 연구의 상당수는 특정 공종의 QTO 또는 개략 견적 수준의 비용 연계에 머무른다(Akanbi & Zhang, 2023).
또한 학계에서 논의되는 BOQ(Bill of Quantities)는 발주처에 제출하기 위한 도급내역을 의미하는 경우가 많다. 도급내역은 표준품셈이나 적산 기준에 따라 작성되므로 상대적으로 정형화되어 있으며, BIM 기반 자동화 연구도 주로 이 영역에 집중되어 왔다. 반면, 본 연구가 대상으로 하는 실행내역은 시공사가 실제 공사를 수행하기 위해 작성하는 예산서로서, 동일한 BIM 객체라도 타설 계획, 구역 분할, 옵션 적용 여부 등에 따라 내역 항목이 분해되거나 통합될 수 있어 객체–내역 간 관계가 1:1로 고정되지 않는 경우가 빈번하다(Kim et al., 2021).
따라서 실제 실행내역 작성에 필요한 표준 속성 정의 및 내역 연계형 DB 스키마를 운영 관점에서 통합적으로 제시한 사례는 제한적이다. 특히 마감공사는 다른 공종에 비해 요구되는 객체 종류가 많고, 내역서를 생성하기 위해 요구되는 속성(명명, 규격, 단위 등)의 요구사항이 복잡하여 실행내역 수준의 데이터 모델이 필수적이다. 그러나 마감공사는 골조공사 대비 실무 적용 수준의 연구 축적이 상대적으로 부족하다(Jeong et al., 2024). 또한 실행내역 자동화는 알고리즘 자체보다 분류체계와 산출규칙, 속성 표준의 부재 및 변경 대응성 부족에 의해 실무 적용이 제약되는 경우가 많다(Olsen & Taylor, 2017).
따라서 본 연구는 대규모 공동주택 프로젝트를 대상으로, BIM 기반 실행내역 산출에 필요한 표준 속성 체계를 정의하고, 비용 항목과 객체 정보를 유연하게 연계할 수 있는 내역 연계형 데이터베이스(DB) 스키마 및 매핑 방안을 제시하는 것을 목적으로 한다.
1.2 연구의 범위 및 방법
본 연구는 실무에서 운영 중인 BIM 기반 실행물량 산출 시스템(BaroBIM)을 통해 축적된 경험을 바탕으로, 대규모 공동주택의 실행내역 산출에 필요한 데이터 구조를 재현 가능한 형태로 정리하고자 한다. 여기서 BaroBIM은 본 연구에서 구축한 통합 시스템을 지칭하는 용어이다. 해당 시스템은 크게 두 가지 모듈로 구성되는데, Revit 애드인(Add-in)과 윈도우 애플리케이션을 통해 표준 라이브러리를 공유 및 관리하는 ‘BIM-L’과, 애드인에서 서버로 전송된 데이터를 바탕으로 웹 환경에서 실행내역 산출을 수행하는 ‘BIM-Q’로 이루어져 있다.
연구 범위는 BIM 소프트웨어 Revit 2023 기반 모델을 대상으로, 실행내역 산출을 위해 요구되는 표준 속성 체계와 객체–내역 연계형 관계형 데이터베이스(RDB) 스키마, 그리고 매핑 규칙 구조를 제시하는 것으로 한정한다.
연구 방법은 다음과 같다.
첫째, 공동주택 실행내역 산출 업무를 분석하여 표준 정보 요구사항을 도출하고, 이를 객체 속성, 공간 속성, 공간 기반 속성, 관계 기반 속성으로 분류한 표준 속성 체계를 제안한다.
둘째, 객체 정보와 내역 항목을 유연하게 연결할 수 있도록 객체–내역 연계형 RDB 스키마를 설계한다.
셋째, 제안된 속성 체계와 스키마를 기반으로 매핑 메커니즘을 구현하고, 실제 공동주택 프로젝트에 적용하여 매핑 범위 및 내역 생성 정합성 등을 지표로 결과를 분석한다.
넷째, LH 공동주택 라이브러리와 이종 BIM 플랫폼 기반 원천데이터를 대상으로 공통 스키마 적용 가능성을 검증하고, 추가 규칙 및 매핑 테이블 확장만으로 시스템의 적용이 가능한지를 평가함으로써 시스템의 확장성을 검증한다.
2. 선행연구 분석
BIM 기반 견적 및 물량산출(QTO) 연구는 건축·토목·플랜트 등 다양한 분야에서 시스템, 워크플로, 표준화 방법론을 중심으로 축적되었다. 그러나 실행내역 단계의 자동화는 단순 물량 산출을 넘어, 표준 속성 체계의 정의, 객체와 내역 매핑 규칙을 분리하여 관리하고, 내역 연계형 DB 스키마의 구조화가 동시에 충족되어야 실무 적용이 가능하다. 특히 실무에서는 CBS 변경, 프로젝트별 예외사항, 옵션 및 공법의 변경이 빈번하므로, BIM기반 실행내역 물량산출의 성능과 지속가능성은 데이터 구조의 설계 완성도와 변경 대응성에 의해 크게 좌우된다.
이에 본 절에서는 선행연구를 실행내역 관점의 데이터 구조화 수준을 기준으로 정리하였다. 구체적으로, 연구별로 표준 속성 정의 범위, 매핑 규칙 표현 방식, DB/지식모델 스키마 제시 여부 및 실증 적용 수준을 비교하여, 실행내역 단계에서 남아있는 연구 공백을 도출한다.
2.1 표준 속성 정의 및 데이터 모델 제시 연구
Table 1은 BIM 기반 견적·물량산출 연구 중 실행내역(BOQ) 단계에서 요구되는 표준 속성 체계와 데이터 스키마의 명시성, 그리고 매핑 규칙·운영 거버넌스의 제시 수준을 기준으로 대표 연구를 비교·정리한 결과이다.
Table 1
Data structuring and schema approaches for BOQ
| Researcher | Analysis method | Contents |
| Monteiro & Martins (2013) |
Modeling guidelines and information input/output analysis for QTO |
Provides guidelines on how BIM models should be authored to support accurate QTO |
| Lee et al. (2014) |
BIM + Ontology based Inference |
Structures object information into an ontology and infers corresponding work items |
| Choi et al. (2015) |
Open BIM-based QTO process/prototype for early design stages |
Proposes an IFC/Open BIM–oriented QTO process and prototype, primarily for schematic/early-stage estimation. |
| Le et al. (2021) |
BIM to relational database(RDB) Integration |
Presents a BIM–DB integrated system architecture where BIM-derived data are stored and updated in an RDB and then used for cost reporting |
| Liu et al (2022a) |
BIM + SMM (standard measurement Method)+ Semantic Modeling |
Formalizes information requirements, entities/relationships, and SMM logic into a knowledge model to support automated QTO, often coupled with model auditing. |
| Ruano-Ruiz et al. (2022) |
Parametric coding In IFC +1:1 mapping budget item |
Proposes a workflow close to BOQ generation, where IFC/model information is coded to correspond to BOQ (budget) line items in a one-to-one manner. |
Monteiro & Martins (2013)는 QTO 정확도 확보를 위해 BIM 모델이 충족해야 할 모델링 가이드라인과 정보 입력·출력 관점의 요구사항을 제시하고, 이를 통해 QTO 지원이 가능한 모델 작성 원칙을 정리하였다. 다만 해당 연구는 실행내역 단계의 운영을 전제로 한 관계형 DB 수준의 스키마 설계, 속성 표준의 정의·변경관리, 객체와 내역 규칙의 관리 구조를 구체적으로 제안하는 데까지는 확장되지 않았다.
Lee et al. (2014)는 온톨로지 기반 추론을 통해 객체 정보를 구조화하고 작업 항목과의 연계를 시도함으로써, 객체–작업 항목 간 의미론적 매핑 가능성을 제시하였다. 다만 실행내역 생성의 실무 적용을 위해 필요한 관계형 DB 수준의 스키마 설계, 규칙의 표현·버전관리, 데이터 갱신 및 이력관리 체계는 구체적으로 제시되지 않았다.
Choi et al (2015)는 IFC/Open BIM을 기반으로 초기 단계에서의 QTO 프로세스 및 프로토타입을 제안하여 개방형 모델을 활용한 산출 자동화의 가능성을 보여주었다. 그러나 초기 단계 중심의 적용 범위로 인해, 실행내역 단계에서 요구되는 세부 내역 항목 분해, 조직별 CBS와의 정합, 속성 표준의 운영·관리까지 포함하는 운영형 스키마 제시는 제한적이었다.
Le et al. (2021)는 BIM 데이터를 관계형 DB (RDB)에 적재·갱신하고 비용 산출 및 리포팅과 연계하는 DB 통합 시스템 아키텍처를 제시하여 운영 관점의 데이터 연계를 다루었다. 반면, 실행내역 산출을 위해 필요한 속성 분류체계(필수/선택/파생) 및 객체와 내역 매핑 규칙의 명시적 표현 방식, 규칙·코드 관리 구조는 제한적으로 논의되었다.
Liu et al. (2022a)는 SMM 기반 정보요구사항과 측정 규칙을 지식모델로 구축하여 자동 물량산출과 모델의 결합 가능성을 제시하였다. 다만 실무에서 빈번히 발생하는 프로젝트별 예외 처리, CBS 변경, 옵션/공법 조건 변경을 포괄하는 운영형 스키마 및 규칙 거버넌스로의 확장에는 추가 연구가 요구된다.
마지막으로 Ruano-Ruiz et al. (2022)는 IFC 속성에 코드를 부여하여 내역 항목과 1:1 매핑하는 방법론을 제안함으로써 실행내역 자동화에 근접한 접근을 제시하였다. 그러나 조직별 내역체계 변화에 대응하기 위한 표준 속성 거버넌스(정의·승인·변경관리) 및 스키마 재사용성 관점의 논의는 상대적으로 제한적이다.
2.2 객체-내역(BOQ)매핑 및 규칙 연구
Table 2는 BIM 기반 실행내역(BOQ) 산출에서 핵심이 되는 객체–내역 매핑 규칙의 구현 메커니즘을 비교·정리한 결과이다.
Table 2
Research on object to BOQ mapping mechanism
| Researcher | Analysis method | Contents |
| Monteiro & Martins (2013) |
Modeling guidelines |
Mapping is largely implicit—if models follow certain guidelines, QTO can be derived reliably. |
| Lee et al. (2015) |
Ontology-based inference rules for work-item identification |
Represents mapping as semantic inference rules over concepts/relationships. Strong in formal reasoning and traceability of “why an item was mapped.” |
| Taghaddos et al. (2016) |
Automated extraction workflow |
Focuses on automating the extraction process by directly linking BIM parameters to estimation templates, reducing manual intervention and improving accuracy. |
| Ruano-Ruiz et al. (2022) |
Code-based mapping via IFC properties + filtering logic |
Encodes BOQ/budget line identifiers into model/IFC properties, enabling direct mapping by code matching and rule-based filtering |
| Liu et al. (2022b) |
SMM-driven rule mapping + semantic constraints |
Mapping logic follows standard measurement methods (SMM), typically implemented as rule constraints |
Taghaddos et al. (2016)은 BIM 모델의 매개변수(Parameter)를 물량 산출 템플릿과 직접 연동하는 자동화 워크플로우를 구현함으로써, 수작업 개입에 따른 오류를 최소화하고 데이터 추출의 정확도와 효율성을 높일 수 있는 직관적인 매핑 방식을 강조하였다.
Ruano-Ruiz et al. (2022)은 IFC 속성에 실행내역 아이템 식별자를 부여하고, 코드 기반 매핑 및 룰 기반 필터링을 결합하여 객체 정보와 내역 항목 간의 1:1 매핑을 가능하게 하는 접근을 제시하였다.
Liu et al. (2022b)는 표준 물량산출 규정과 객체와 내역간의 제약조건을 결합한 규정 기반 매핑을 통해 포함·제외 조건과 측정 규칙을 체계적으로 반영할 수 있음을 보였다.
그러나 Table 2의 연구들은 매핑 구현 방식에서 차별성을 보임에도, 실행내역 단계의 실무 적용에 필수적인 CBS 교체 및 내역체계 변동에 대한 대응성, 프로젝트별 예외 처리 및 옵션/공법 조건의 관리, 규칙의 버전관리와 감사추적을 통합적으로 지원하는 운영형 매핑 거버넌스까지는 충분히 제시하지 못했다. 이에 본 연구는 객체 속성의 표준화에 기반하여, 규칙 테이블 기반의 조건부 매핑 메커니즘과 내역 연계형 DB 스키마를 함께 설계함으로써, 변경 대응성과 재사용성을 확보하는 방향으로 접근한다.
3. 실행내역 산출을 위한 객체 정보 요구사항 정립
3.1 공동주택 실행내역 산출을 위한 객체 데이터 모델링
아래 Figure 1은 공동주택 실행내역 산출을 위한 데이터 모델링 가이드 개념도이다. 실행내역 산출을 위한 BIM 객체의 속성정보는 크게 네 가지로 구분된다.
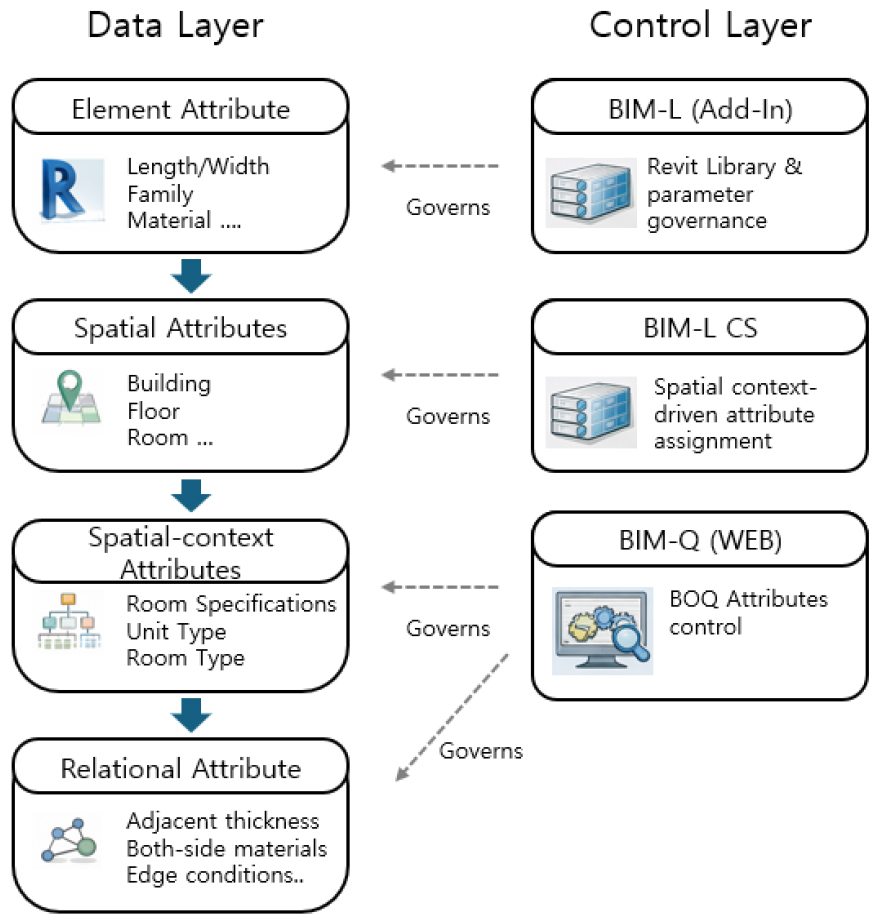
첫째, 객체 기본 속성(Element Attributes)은 객체가 저작도구에서 기본적으로 보유하는 정보로서 길이·면적·부피 등 기하 정보와 패밀리(Family), 타입(Type), 재질(Material) 등의 식별 정보를 포함한다. 본 연구에서는 자체 실행내역 분류체계와 BIM 객체를 안정적으로 연계하기 위해, Table 3과 같이 객체 식별 코드를 3단계 체계로 구성하였다. 1단계는 Revit 카테고리 기반의 객체 구분, 2단계는 공종 관점의 구분, 3단계는 내역 기준의 세부 객체 코드로 구성된다. 이와 같은 계층형 식별자는 동일 카테고리 객체라도 공종 및 세부 기준에 따라 서로 다른 내역항목으로 연결될 수 있도록 하며, 라이브러리 단위의 표준화 및 변경 관리에도 활용된다.
Table 3
Example of hierarchical identifiers for object code
또한 본 연구는 Revit 애드인 기반 라이브러리 관리 시스템(BIM-L)을 통해 사전에 정의된 표준 라이브러리를 모델링 단계에서 배포 및 관리하여 객체 속성 및 파라미터의 일관성을 확보할 수 있도록 하였다.
둘째, 공간 속성(Spatial attributes)은 객체의 공간적 위치를 나타내는 정보로 건물 분류, 건물 코드, 층, 실(Room) 등의 식별 정보를 포함한다. 모델링 단계에서 공간 정보를 필수로 입력하도록 관리한다. 건물 유형에 따라 1차 분류 후 건물별 코드를 부여하고 최하위 수준에서 실 정보를 입력하도록 구현하였다. 예를 들어 아파트는 A, 부속동은 B, 주차장은 C, 단위세대는 T 코드로 구분하며, 각 객체는 해당 코드 체계와 실 정보를 통해 공간적으로 식별된다. 이와 같은 공간 속성 또한 BIM-L을 통해 모델링 단계에서 표준화된 형태로 입력·관리된다.
셋째, 공간 기반 속성(Spatial-context Attributes)은 객체가 위치한 건물·층·실의 맥락에 따라 부여되는 속성이다. 즉, 동일한 객체라도 어떤 건물의 어떤 실에 위치하는지에 따라 내역상 요구되는 속성이 달라진다. 즉, 객체가 위치한 공간 속성을 감지하여, 실행내역 산출에 필요한 내역속성을 자동으로 부여하도록 시스템을 구성하였다.
넷째, 관계 기반 속성(Relational Attributes)은 인접 벽체의 두께, 양측 마감 재질, 모서리 조건 등의 주변 객체와의 관계를 통해 정의되는 내역 속성이다. 객체가 가지는 관계를 통해 결정되는 속성으로 실행내역 산출에 활용하도록 구성하였다.
본 연구에서는 실행내역 산출에 필수적인 ‘공간 기반 속성’과 ‘관계 기반 속성’을 웹 시스템(BIM-Q)을 통해 통합적으로 정의 및 관리한다. 구체적으로, 웹 환경에서 객체가 갖추어야 할 내역 속성과 그에 대응하는 매핑 규칙을 표준화함으로써, BIM 모델의 공간정보를 바탕으로 각 객체에 적합한 내역 속성이 규칙에 따라 체계적으로 부여되도록 구성하였다.
3.2 공간 위계 기반의 속성 상속 모델
데이터 표준화를 위해 공동주택에서 발생할 수 있는 공간 유형을 내역서 구성 방식에 따라 아파트, 부속동, 지하주차장, 단위세대로 구분하고 각 유형에 식별 코드를 부여하였다. 또한 도면 작성 방식에 따라 표현이 상이한 부속동 건물 유형을 주민공동시설, 관리사무소, 경비실, 근린생활시설, 유치원, 어린이집의 6개로 표준 분류하여 유형별 코드를 정의하였다.
건물 하위 단계인 실(Room) 정보는 도면에 표기된 명칭을 그대로 입력할 수 있도록 허용하였다. 이는 실행내역이 실무에서 활용되기 위해서는 내역이 도면 근거성을 가져야 하며, 실명·공간명과 같은 공간 정보는 현장 및 견적 실무에서 도면 표기와의 일치가 특히 중요하기 때문이다.
본 연구에서 제안하는 공간 위계 기반의 속성 상속 모델은 프로젝트–공종–건물–실까지 공간 정보가 입력된 객체에 대해, 해당 공간 맥락을 상속받아 내역산출에 필요한 속성을 부여하는 방식으로 구성된다. 이를 통해 반복 입력을 최소화하면서도 프로젝트 간 데이터 구조의 일관성을 유지할 수 있으며, 공간 기반 규칙을 통해 객체의 내역속성을 결정할 수 있다.
Table 4는 공간 위계 정보(프로젝트–공종–건물–실)와 객체 분류 정보가 결합될 때, BIM-Q에서 정의된 규칙에 따라 객체의 내역속성이 결정되는 과정을 예시로 나타낸 것이다. 특히 실 명칭을 도면 표기 그대로 유지함으로써 생성된 실행내역의 도면 근거성과 실무 활용성을 확보하였다. 또한 공간 코드 체계를 통해 입력을 최소화하면서도 표준화된 구조로 속성을 상속·부여할 수 있음을 보여준다.
Table 4
Example of hierarchical identifiers for spatial attribute
3.3 속성 입력 시스템
Figure 2는 Revit Add-In으로 실행내역 산출을 위해 객체 속성정보를 입력·관리하는 화면 예시이다. Revit 기반 기본 파라미터(기하, 재질, 패밀리 등)와 공간 식별정보(건물,층,실)는 모델링 단계에서 입력되며, 실행내역 산출에 필요한 내역속성은 사전에 정의된 규칙에 따라 공간 맥락 기반으로 부여된다.
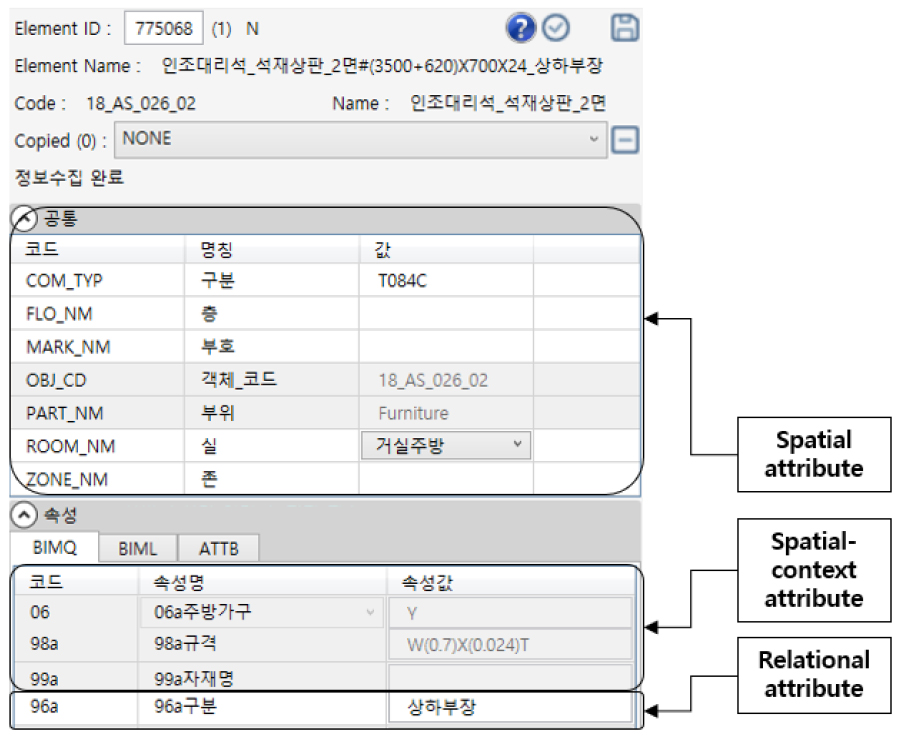
Monteiro & Martins (2013)는 QTO 지향 BIM 설계를 위해서는 물량산출 목적에 적합한 객체 단위의 정보요구사항과 속성 표준화가 선행되어야 함을 제시하였다. 이를 바탕으로 본 연구에서는 객체가 가지는 공간정보에 따라 내역속성 정보가 정의 될 수 있도록 시스템을 구축하였다. 예를 들어 Figure 2의 인조대리석 석재상판 객체는 ROOM_NM이 ‘거실주방’으로 정의된 경우, 공간정보에 따라 내역산출에 필요한 속성인 ‘06a주방가구’가 자동으로 Y로 활성화된다. 이와 같이 동일한 객체라도 공간 맥락에 따라 서로 다른 내역속성이 결정된다. 또한 공간 정보 또는 Revit 파라미터 값을 참조하여 입력되는 속성은 회색으로 표기하여 모델링 단계에서 편집을 제한함으로써, 데이터 일관성과 입력 오류를 방지하였다.
반면 ‘96a구분’과 같이 객체의 관계성을 통해 세부 유형을 구분해야 하는 속성은 모델과 도면을 확인한 후 판단이 필요한 항목이므로, 모델링 단계에서 사용자가 직접 입력할 수 있도록 편집을 허용하였다.
4. 객체-내역 연계형 데이터베이스 스키마 매핑 알고리즘
4.1 내역 연계를 위한 RDB스키마 설계
아래 Table 5와 Figure 3은 공동주택 BIM 기반 실행내역 산출을 위해 설계된 관계형 데이터베이스(RDB) 스키마의 개념적 구조 및 개체-관계 모델(ERD)을 나타낸다. 본 스키마는 BIM 모델로부터 추출되는 객체 데이터와 내역 항목을 직접 결합하는 방식이 아니라, 중간에 표준화된 “속성–규칙–매핑” 레이어를 두어 프로젝트별 변화와 CBS 교체에 유연하게 대응하도록 구성하였다.
Table 5
BOQ-Linked relational schema components
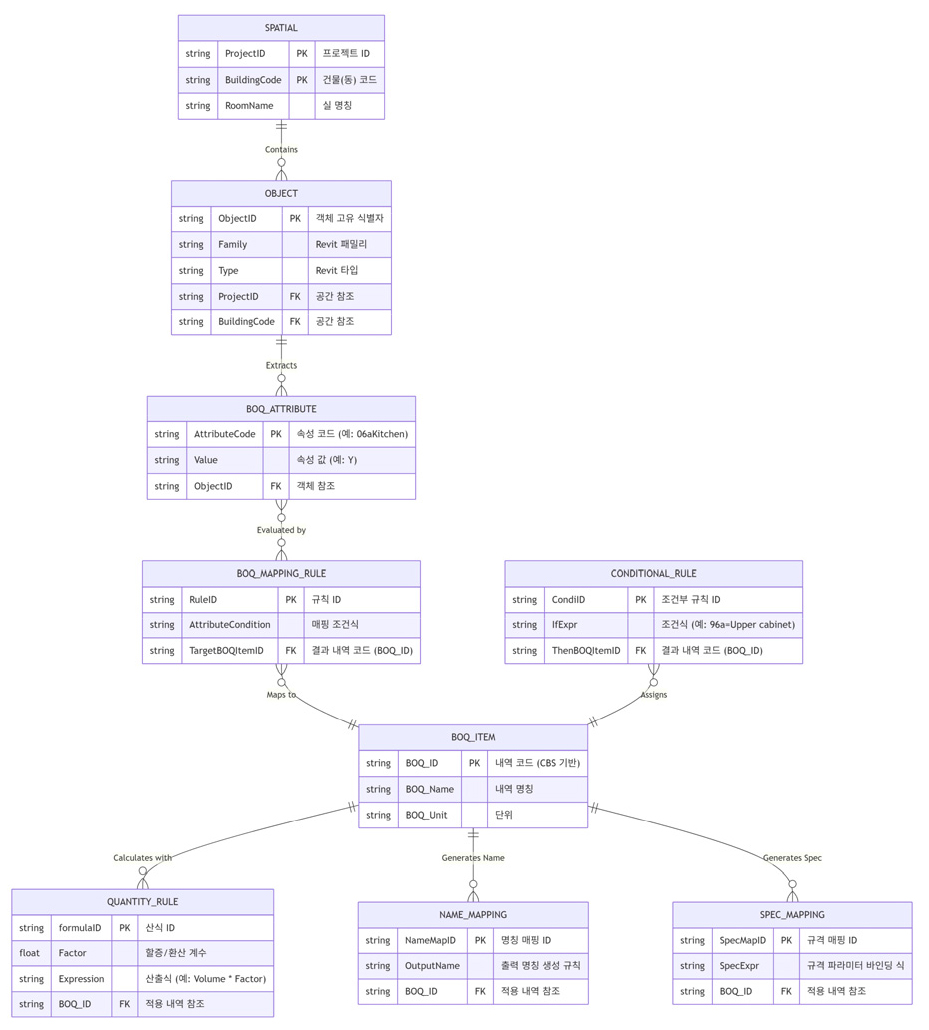
데이터베이스 스키마의 핵심 엔터티는 데이터의 흐름과 목적에 따라 크게 4가지 논리적 계층으로 구성된다.
첫째, 공간 및 객체 계층(Spatial & Object Layer)의 객체속성은 모델 고유 식별자와 Revit 파라미터를 포함한다. 공간속성은 프로젝트–공종–건물–층–실로 구성되는 공간 위계를 저장하며, BIM-L/BIM-L CS에서 관리되는 공간 식별 정보(건물코드, 층, 실명 등)를 참조하여 위치 기반의 내역 산출 기반을 마련한다.
둘째, 내역 연계 계층(BOQ Link Layer)의 내역속성은 실행내역 산출을 위한 공간 기반 속성과 관계 기반의 속성으로 내역코드와 연결되는 역할을 하며, 내역코드는 CBS 기반의 내역 항목인 코드, 명칭, 단위 등을 관리하는 속성정보이다.
셋째, 산출 계층(Calculation Layer)의 매핑규칙은 객체와 내역 연계를 결정하는 규칙 집합을 조건과 결과 형태로 저장한다. 객체가 특정 조건식을 만족할 때 사전 정의된 규칙에 따라 적합한 내역 코드와 연결되어 물량을 연산한다.
넷째, 출력 매핑 계층(Output Mapping Layer)은 실무 맞춤형 결과물을 생성한다. 실무에서 사용되는 실행내역은 자재의 규격 및 해당 내역의 공간적 위치 정보에 대한 명기를 필수적으로 요구한다. 본 연구에서는 명칭 매핑(Name mapping) 및 규격 매핑(Spec mapping) 기능을 통해 이러한 실무적 요구사항을 충족하도록 시스템을 구현하였다.
본 데이터 모델의 핵심 의의는 객체 데이터의 원형을 유지한 상태에서, 실행내역 산출에 필요한 속성과 규칙을 별도의 데이터베이스(DB) 레이어로 분리하여 관리함으로써 데이터의 독립성과 유연성을 확보했다는 점이다.
4.2 속성 기반의 조건부 매핑 메커니즘
Figure 4은 공동주택 실행내역 산출에서 객체가 실행내역 항목으로 연결되는 속성 기반 조건부 매핑 메커니즘을 나타낸다. 본 연구의 매핑은 객체와 내역코드가 1:1 연결을 전제하지 않으며, 객체가 가진 내역 속성을 통해 1:N의 관계성을 가질 수 있도록 구축하였다.

이러한 1:N 독립 매핑 구조로 인해, 본 시스템에서는 단일 객체에 여러 규칙이 부합하더라도 이들이 상호 배타적으로 경합하는 규칙 충돌이 발생하지 않는다. 매핑 규칙은 각 규칙 조건의 만족 여부(Y/N)를 개별적으로 평가하며, 복수의 규칙 조건을 만족할 경우 다수의 내역 항목이 생성되고, 조건을 만족하지 않으면 내역이 생성되지 않는 확정적 산출 방식을 취하기 때문이다.
웹 시스템을 통해 매핑 규칙은 저장되며, 각 규칙은 AND/OR 조합의 조건식과 내역코드로 구성된다. 예를 들어 동일한 Dry_wall 객체라도 실의 명칭이 복도인지 세대 내부인지에 따라 내역 속성이 달라지고, 달라진 내역속성에 의해 내역코드가 달라질 수 있다. 또한 인접 벽체의 재질, 양측 마감의 조합, 모서리 및 단부 조건 등의 ‘관계 기반 속성’을 내역 세분화되어 내역속성을 부여하여, 복합적인 시공 조건에 따라 내역 항목이 유동적으로 결정될 수 있는 확장형 구조를 채택하였다.
이러한 조건부 매핑의 장점은 프로젝트별 CBS 변경이나 공법 혹은 옵션의 변경이 발생하더라도, 규칙 테이블을 수정·추가하는 방식으로 대응이 가능하다는 점이다.
4.3 수식기반의 동적 물량 산출 엔진
객체가 내역코드로 연결된 이후에도, 실행내역 수준의 산출을 위해서는 면적·부피·길이의 합산만으로는 충분하지 않다. 마감공사는 단위 체계와 산출 기준이 복잡하며, 코킹·부자재·부속철물 등은 프로파일 길이와 같은 파생값을 요구하고, 동일 객체라도 조건에 따라 산출식이 달라질 수 있다. 본 연구는 이러한 요구를 반영하기 위해 내역코드 단위로 산출식을 관리하고, 객체 속성에 따라 수량을 동적으로 계산하는 수식 기반 엔진을 제안한다.
산출 엔진은 기본 변수와 파생 변수와 계수,손율,중복 제외 등의 규칙을 조합하여 최종 수량을 계산한다. 각 내역코드에는 조건수식과 산식이 연결된다. 추가로 산출식은 객체 속성을 활용하여 실행내역을 구성하는 규격/명칭 매핑을 동적으로 생성한다. 또한 프로젝트별 기준 변경에 대응하기 위해 수식을 객체에 고정하지 않고 웹 DB를 통해 관리하며, 버전 단위로 기록하여 재현성과 감사추적성을 확보한다.
이와 같은 동적 산출 구조는 객체–내역 매핑 규칙과 결합될 때 실행내역 수준을 자동화할 수 있게 하며, 특히 규칙·단위·예외가 많은 마감공사에서 실무 적용성을 향상시킨다.
5. 시스템 구현 및 사례 검증
5.1 공동주택 프로젝트 적용 사례 분석
본 연구는 2023–2025년 기간 동안 제안 시스템을 활용하여 공동주택 실행내역을 수행한 프로젝트의 수행 이력 데이터를 수집하고, 그중 마감공사 가실행 단계의 적용 결과를 분석하였다. 분석 지표는 프로젝트별 연면적, 타입 수, 산출 내역 수, 프로젝트 수행 과정에서 신규로 정립된 산출 기준 수, 시스템 오류 건수이며, 이를 Table 6에 정리하였다.
Table 6
Summary of project and BOQ generation outcomes
Table 6에 따르면 프로젝트별 규모(연면적)와 구성(타입 수)에 따라 산출 내역 수는 차이를 보인다. 이러한 Table 6의 원시 데이터를 바탕으로 시스템의 누적 적용에 따른 정량적 성능 개선도를 분석한 결과가 Table 7이다. 본 분석에서는 시스템의 성숙도를 객관적으로 평가하기 위해 세 가지 지표를 정의하고 산식을 적용하였다.
Table 7
Quantitative analysis of system stabilization and performance improvement
첫째, ‘신규 규칙 생성 비율(New Rule Ratio)’은 전체 산출 내역 수 대비 신규로 정립된 산출 기준 수의 비율(신규 산출 기준 수 / 전체 산출 내역 수 × 100)로 계산하여 규칙의 추가 소요를 확인하였다.
둘째, ‘오류 감소율(Error Reduction Rate)’은 초기 적용 단계인 Project A의 오류 건수(10건)를 기준점(Baseline)으로 삼아, 후속 프로젝트에서 오류가 얼마나 감소했는지를 백분율((10 - 발생 오류 건수) / 10 × 100)로 산정하였다.
셋째, ‘안정화 지수(Stabilization Index)’는 기존 규칙의 재사용률을 직관적으로 나타내는 지표로서, 전체(100%)에서 앞서 구한 신규 규칙 생성 비율을 차감한 값(100% - 신규 규칙 생성 비율)으로 정의하였다.
이러한 지표를 바탕으로 프로젝트 수행 단계를 살펴보면, 초기 적용 단계(Project A)에서는 마감공사의 복합 조건과 예외 상황이 다수 존재하여 신규 규칙의 생성이 빈번하게 발생하였다. Table 7에서 나타나듯, Project A의 신규 규칙 생성 비율은 13.63%에 달했으며 시스템 오류도 10건 발생했다. 그러나 이후 규칙 데이터베이스가 축적되면서 동일·유사 조건에 대한 재사용이 가능해져 신규 규칙 생성은 점진적으로 감소하는 추세를 보였다. 이는 반복 수행 과정에서 표준 속성 정의, 매핑 규칙, 산출식 및 DB 스키마가 단계적으로 보강되면서, 후속 프로젝트에서 요구되는 추가 정비 범위가 축소된 결과로 해석할 수 있다.
특히 Project D와 E에 이르러서는 신규 규칙 생성이 0~1%대로 급감하는 구간이 관찰되었는데, 이는 표준 속성 체계와 매핑 규칙이 일정 수준 이상 누적되면서 시스템이 안정화 단계로 진입했음을 의미한다. 매핑 조건의 고도화로 시스템 산출 오류 역시 Project D와 E에서 0건으로 수렴하였다. 또한, 기존 규칙의 재사용만으로 내역 산출에 성공한 비율을 의미하는 안정화 지수는 초기 86.37%에서 최종 99.47%까지 지속적으로 상승하였다. 종합하면, 적용 경험이 누적될수록 표준 속성 체계 및 매핑 규칙의 성숙도가 고도화되며, 운영 관점에서 높은 수준의 성숙도에 도달하는 방향으로 수렴하는 경향을 정량적으로 확인할 수 있었다.
다만 실행내역 산출 기준은 발주·설계·시공 조건 및 내부 기준 개정 등 시점 요인에 따라 변동될 수 있으므로, 운영 단계에서는 기준 변경을 반영하기 위한 규칙과 매핑 테이블 업데이트가 지속해서 병행되어야 한다.
5.2 LH라이브러리 활용 프로젝트 적용 사례 분석
본 절에서는 제안 시스템의 확장성 검증을 위해, LH에서 BIM설계를 목적으로 구축하고 공유한 Revit 기반의 84타입을 분석하였다(Korea Land & Housing Corporation, 2025). 구체적으로, LH 공유 라이브러리를 기반으로 모델을 재구축한 후, 본 연구에서 제안한 표준 속성 체계 및 객체–내역 매핑 규칙을 동일하게 적용하여 실행내역 산출 가능 범위와 적용 한계를 비교·정리하였다.
분석 결과는 Table 8과 같다. 본 연구에서 수행한 프로젝트의 기준(Project E)을 적용했을 때는 229개의 객체에서 총 419개의 내역코드가 산출되었으나, LH 라이브러리(LH)를 적용한 프로젝트의 경우 객체 수가 127개로 감소함에 따라 산출 내역 또한 176개에 그쳤다. 이는 기존 대비 약 42% 수준의 산출률로, 외부 라이브러리를 수정없이 사용할 경우 일부 내역이 누락됨을 보여준다. 누락 및 불일치의 원인을 세부적으로 살펴보면, 내역 기준 차이가 125건으로 가장 큰 비중을 차지했으며, 복합 객체 문제 77건, 파라미터 불일치 34건, 카테고리 차이 7건 순으로 나타났다.
Table 8
BOQ Line analysis (Project E vs. LH)
이러한 정량적 차이가 발생한 구체적인 원인과 제약 사항은 다음과 같다.
첫째, 내역 산출의 기준 차이로 인해 가장 많은 항목의 내역 산출이 제한되었다. 본 연구에 사용된 시스템은 자체 실행내역 기준에 맞춰 산출 대상 항목이 모델에 표현되도록 라이브러리를 구성하고 있으나, LH 라이브러리는 상이한 내역 체계로 특정 항목을 비모델링 대상으로 간주하거나 다른 방식으로 표현하는 경우가 있었다. 그 결과, 자체 기준에서 산출이 요구되는 일부 항목이 LH 라이브러리 기반 모델에 객체가 부재하여 직접 산출이 불가하였다.
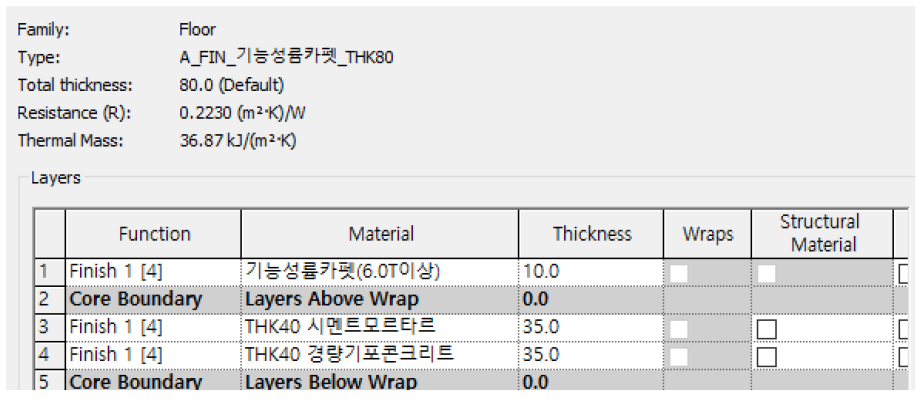
둘째, 복합 객체의 사용 방식 차이가 인식 및 산출 제약으로 이어졌다. 제안된 시스템은 객체–내역 매핑의 안정성과 규칙 적용성을 확보하기 위해 가능한 단일 객체 모델링을 지향하는 반면, LH 라이브러리에는 복합 객체 형태로 구성된 사례를 확인할 수 있었다. 시스템이 객체를 정상적으로 인식하지 못하는 문제가 발생하였다. 예를 들어, 자체 기준에서는 강마루 10T, 시멘트몰탈 70T, 바닥충격음저감재 40T가 각각 분리된 객체로 작성되어야 한다. 반면 LH 라이브러리에서는 Figure 5와 같이 동일 바닥 구성이 기능성 룸카펫 + 시멘트몰탈 40T + 경량기포콘크리트 40T와 같이 복수 재료와 층 구조를 하나의 객체로 통합하여 작성된 사례가 확인되었다. 이러한 차이는 구성별 산출 항목이 서로 다른 내역 체계로 연결되어야 하는 실행내역 단계에서, 구성요소 별 매핑·산출을 어렵게 하며 추가적인 객체 분해 규칙 또는 보강 로직이 필요함을 시사한다.
셋째, 카테고리 분류 체계의 불일치로 인해 동일 성격의 객체임에도 시스템 인식 실패가 발생하였다. 본 연구의 시스템은 특정 객체를 Revit의 General Model 기반으로 분류하여 모델링하는 반면, LH 라이브러리는 동일 객체를 Ceiling 등 다른 카테고리로 정의한 사례가 확인되었다. 이러한 카테고리 불일치는 객체 유형 판별 로직의 전제와 상이하여, 규칙 테이블이 적용되지 않거나 산출 대상에서 제외되는 결과를 초래하였다.
넷째, 창호 등과 같이 파라미터 다양성이 높은 라이브러리에서는 속성 표준화 및 매핑 난이도가 증가하였다. 창호는 규격, 개폐 방식, 유리 사양 등 설계 성능 파라미터가 포함되며, 외부 라이브러리에서는 파라미터 구성과 명명 규칙이 자체 기준에 맞춰 정의되어있다. 이 경우 제안 시스템의 표준 속성 정의 및 매핑 규칙을 그대로 적용하기 어려운 항목이 발생하였고, 결과적으로 일부 창호 객체는 추가적인 정규화가 요구되었다.
종합하면, LH 라이브러리 적용 사례는 외부 라이브러리도 일정 범위에서는 활용 가능함을 확인하는 동시에, 실행내역 자동화를 위한 실무 적용성은 라이브러리의 존재 여부보다 내역 기준 정합성, 모델링 목적과 작성 수준, 객체 단위(복합/단일), 카테고리·분류 체계, 파라미터 표준화 수준에 의해 결정됨을 보여준다. 따라서 외부 라이브러리를 본 연구 시스템에 확장 적용하기 위해서는, 공통 스키마로의 정규화뿐 아니라 카테고리, 파라미터, 복합객체 처리에 대한 변환 규칙을 추가적으로 정의하는 절차가 필요하다.
특히 복합객체 문제의 경우, 데이터 스키마 내에 객체 분해 전처리 기능을 도입함으로써 구조적인 해결이 가능하다. 단일 BIM 객체에 다중 재질 정보가 포함된 경우, 매핑 엔진으로 데이터를 넘기기 이전 단계에서 Revit API(예: HostObjectUtils)를 활용해 각 구성 재료의 두께, 면적, 체적을 추출할 수 있다. 이렇게 추출된 하위 요소들을 독립된 가상 객체 단위로 분해하여 정규화하면, 본 연구에서 제안한 단일 객체 기준의 ‘속성-규칙-매핑’ 알고리즘을 직접적인 객체의 수정 없이 그대로 재사용하여 정확한 내역 산출을 수행할 수 있다.
5.3 이종 BIM플랫폼에 대한 내역 연계 적용성 검증
본 절에서는 제안 시스템이 특정 플랫폼에 종속되지 않고 범용적으로 적용 가능한지 검증하였다. 이를 위해 Revit이 아닌 이종 플랫폼(BuilderHub)에서 생성된 골조 공사 데이터를 대상으로, 앞서 제안한 내역 연계 메커니즘이 동일하게 작동하는지 평가하였다. 검증 과정에서는 BuilderHub 데이터의 필드 구조가 Revit과 상이하다는 점을 고려하여, 원천 데이터를 본 연구의 공통 스키마로 정규화한 후 시스템에 적용하였다.
구체적인 정규화 방식은 다음과 같다. 우선 객체 식별자와 분류 정보는 각각 1:1로 변환하였고, 층·구역·동과 같은 위치 필드는 공간 속성에 매핑하였다. 또한, 내역 산출의 핵심인 내역속성은 Revit 적용 사례와 동일하게 사전 정의된 규칙에 따라 자동으로 부여되도록 구성하였다.
Table 9는 이러한 원천 필드와 공통 스키마 간의 대응 관계를 보여준다. 대부분의 항목은 1:1로 직접 매핑되나, ‘02a플레이싱붐타설’이나 ‘05a저소음알폼’과 같이 다수의 원천 속성 정보가 조합되어야 하나의 내역속성으로 결정되는 N:1 매핑 사례도 존재한다. 시스템은 이러한 비정형 대응 관계를 AND/OR 조합의 조건식으로 해석하여, 최종적으로 정확한 BOQ 항목을 산출하도록 처리하였다.
Table 9
Cross-platform field normalization from BuilderHub data to the proposed BOQ-linked schema
| BuilderHub properties | Cardinality | BOQ schema |
| ELEMENT_ID | 1:1 | ELMT_ID |
| OBJECT | OBJ_CD | |
| ConcreteType | 2:1 |
02cConcretePlacing -boom |
| FLOOR | ||
| Floor | 3:1 |
05aLow -noiseFormwork |
| BuildingName | ||
| FormType |
또한, 골조공사 실행내역을 산출할 때는 객체의 직접 물량(길이·면적·부피·개수) 외에도, 건물·층·구역 등 공간적 범위에 따라 별도로 집계해야 하는 간접산출 항목이 존재한다. 그러나 원천 데이터가 이러한 간접산출에 필요한 범위 정보나 파생 필드를 일관된 형식으로 제공하지 못하는 경우가 빈번하다. 이를 해결하기 위해 본 연구에서는 공통 스키마로 데이터를 1차 정규화한 후, 부족한 정보를 채워주는 Python 기반 보강 모듈을 추가로 개발하여 적용하였다.
이 보강 모듈은 사용자가 지정한 범위(건물·층)나 프로젝트 규칙에 따라 집계 키(Aggregation Key), 적용 플래그(Apply Flag), 파생 변수 등을 생성하여 스키마의 확장 필드로 저장한다. 이를 통해 별도의 예외 로직 없이도 간접산출 항목을 기존의 규칙 테이블 및 산출식 프레임워크 내에서 일관되게 처리할 수 있게 되었다.
검증 결과, BuilderHub 데이터 역시 정규화와 보강 과정을 거친 후에는 기존 시스템의 규칙과 산출식을 그대로 재사용하여 내역코드와 연계가 가능함을 확인하였다. 이는 내역 연계의 핵심 성공 요인이 특정 저작도구의 파라미터 구조에 있는 것이 아니라, 표준화된 데이터 스키마와 플랫폼 중립적인 산출 엔진의 결합에 있음을 시사한다. 물론 초기 도입 단계에서는 플랫폼 간 속성 명칭이나 분류 체계의 차이로 인해 정규화 매핑 테이블 구축에 일부 수동 작업이 요구될 수 있다. 하지만 한 번 확정된 매핑 데이터는 표준화된 형태로 시스템에 축적되므로, 후속 프로젝트에서는 이를 재사용하여 설정 부담을 점진적으로 줄여나가는 효율적인 운영 구조를 제공한다.
6. 결 론
6.1 연구의 요약 및 시사점
본 연구는 공동주택 마감공사를 중심으로 BIM 기반 실행내역 산출을 위한 표준 속성 체계와 내역 연계형 데이터 모델을 제안하였다. 제안 모델은 BIM 객체 데이터와 내역코드를 1:1로 고정 결합하지 않고, 그 사이에 ‘속성-규칙-매핑’ 레이어를 두어 유연성을 확보하였다.
특히, 표준화 관점에서 본 연구의 가장 중요한 요점은 BIM 객체 데이터와 내역 항목 간의 구조적 분리를 구현했다는 점이다. 기존의 1:1 정적 매핑 방식과 달리, 중간에 표준 속성 기반의 룰 매핑 레이어를 둠으로써 모델 객체의 직접적인 수정 없이도 CBS나 공법 변경에 유연하게 대응할 수 있는 상호운용성을 확보한 것이 핵심이다.
즉, 실행내역 물량산출 자동화의 성능은 단순 알고리즘보다 데이터 구조(속성·규칙·스키마)의 설계 완성도와 변경 대응성에 의해 좌우된다는 관점에서, 내역 연계 로직을 객체와 분리하여 지속 운영할 수 있는 형태로 구현한 점에 본 연구의 의의가 있다.
또한 내역코드 단위로 산출식을 관리하여, 객체의 기하 정보뿐만 아니라 공간·공간 맥락·관계 기반 속성에 따라 물량이 동적으로 평가되는 산출 엔진을 구성하였다. 이는 규격, 예외 조건, 단위 환산이 복잡한 마감공사에서 단순 물량 산출(QTO)을 넘어, 실행내역 수준의 정밀한 운영형 산출을 가능하게 한다.
실증 분석에서는 2023–2025년 다수의 공동주택 프로젝트에 시스템을 적용하여 그 효과를 검증하였다. 분석 결과, 시스템 적용 경험이 누적될수록 신규 기준 정립 소요와 시스템 오류 건수가 감소하는 경향이 뚜렷하게 나타났다. 이는 표준 속성 정의, 룰, 산출식, DB 스키마가 반복 수행을 통해 규칙화되어 점진적으로 고도화되는 운영 구조가 유효함을 시사한다. 물론 실행내역 기준은 시점과 현장 여건에 따라 변동되나, 본 시스템은 운영 단계에서의 룰/테이블 업데이트 체계를 통해 이러한 변화에 능동적으로 대응할 수 있음을 확인하였다.
특히 확장성 관점에서는 외부 기관인 LH 라이브러리를 대상으로 본 시스템의 적용 가능성을 타진하였다. 분석 결과, 내역 기준과 모델링 작성 방식(복합 객체 등)의 차이로 인해 초기 산출에는 일부 조정이 필요하였으나, 이는 역설적으로 본 연구가 제안한 ‘규칙 기반 매핑 구조’의 효용성을 입증하는 계기가 되었다. LH 라이브러리에서 나타난 복합 객체나 상이한 파라미터 체계는 시스템의 코어 수정 없이, 해당 기준에 맞는 변환 규칙과 매핑 테이블을 추가 정의하는 것만으로도 충분히 수용 가능함을 확인하였기 때문이다. 이는 본 연구의 모델이 특정 건설사의 내부 기준에만 국한되지 않고, LH와 같은 공공 표준이나 다양한 외부 라이브러리 환경으로도 손쉽게 확장·적용될 수 있는 범용적 플랫폼으로서의 잠재력을 갖추었음을 시사한다.
나아가 Revit이 아닌 이종 플랫폼인 빌더허브의 골조 데이터 또한 본 연구의 공통 스키마로 정규화하는 과정을 거쳐 기존의 산출 규칙과 수식을 그대로 재사용할 수 있음을 검증하였다. 이는 본 연구의 모델이 특정 저작 도구에 종속되지 않고, 데이터 표준화와 플랫폼 중립적인 산출 엔진을 통해 다양한 BIM 환경으로 손쉽게 확장될 수 있는 범용적 플랫폼으로서의 잠재력을 갖추었음을 강력하게 시사한다.
6.2 향후 연구과제
본 연구를 통해 구축된 BIM 기반 실행내역 산출 체계는 실무 적용성을 입증하였으나, 건설 산업의 데이터 고도화와 지능형 견적 자동화를 위해서는 다음과 같은 후속 연구가 지속적으로 수행되어야 한다.
첫째, 데이터 표준화를 기반으로 한 온톨로지 지식 모델로의 확장이 필요하다. 본 연구에서 정의한 표준 속성 체계와 객체-내역 매핑 규칙은 BIM 데이터의 의미론적 연결을 가능하게 하는 기초 자산이다. 향후 연구에서는 이를 기계가 스스로 이해하고 추론할 수 있는 온톨로지 형태로 발전시켜, 단순한 규칙 매핑을 넘어 공법 변경이나 설계 의도에 따라 최적의 내역 아이템을 자동으로 추천하고 검증하는 지능형 시스템으로 고도화해야 한다.
둘째, 축적된 상세 견적 데이터를 활용하여 개략 견적 자동화 모델을 구축해야 한다. 본 시스템을 통해 수집되는 프로젝트별 실행내역 데이터는 높은 신뢰도를 가진 고품질의 실적 데이터이다. 이러한 상세 견적 DB를 체계적으로 축적하고 분석하여 건물 유형, 규모, 마감 수준에 따른 공사비 영향 요인을 도출한다면, 설계 초기 단계에서도 적은 정보만으로 높은 정확도의 공사비를 예측할 수 있는 데이터 기반 개략 견적 모델을 완성할 수 있을 것이다.
셋째, 모듈 단위로 축적되는 대용량 데이터의 고속 연산을 위한 시스템 아키텍처 연구가 요구된다. BIM 모델의 객체 수와 내역 정보량이 증가함에 따라, 모듈별로 생성되는 방대한 데이터를 실시간으로 처리하고 집계하는 연산 성능 확보가 필수적이다. 따라서 향후에는 클라우드 기반의 분산 처리 기술이나 인메모리 컴퓨팅 등 대규모 BIM-내역 데이터를 지연 없이 산출하고 시뮬레이션할 수 있는 고성능 연산 시스템 및 최적화 알고리즘에 관한 연구가 병행되어야 한다.
