

1. 서론
1.1 연구의 배경 및 목적
1.2. 연구의 필요성
2. 선행연구 검토
3. 연구 방법
3.1 연구의 범위
3.2 데이터 수집
3.3 영상 인식 및 분석 알고리즘
4. 기계학습을 통한 인식모델 구축
5. 결론
6. 활용 방안에 대한 제안
6.1 건물내 재실자 빅데이터 구축 및 활용 방안에 대한 연구
6.2 건축, 도시 스케일의 차세대 시각화 방안 연구
1. 서론
1.1 연구의 배경 및 목적
현대 사회에서는 공간이 대형화되고, 현대인의 삶도 실내 공간에서 많이 이루어지고 있다. 이러한 추세로 인해, 실내 공간에 남아 있는 재실자들은 재난 및 범죄 위험에 노출되고 있다. 또한 대형 건물과 세분화된 공간적 특성 때문에 화재나 범죄에서 실내 재실자를 구하기 위한 소방 및 경찰 인력들은 실내 공간의 정보 부재로 대피 및 구조에 많은 시간을 낭비하고 있다. 이는 적절한 실내 공간 내 재실자 수 파악 및 층별 재실자 수 등 실내 환경 분석의 중요성을 높이고 있다.
많은 연구에서는 CO2 센서, 초음파 센서 등 다양한 센싱 정보를 이용하여 재실 여부를 파악하고(Rathore et al., 2016) 있다. 그러나 이러한 센서를 이용한 재실자 분석은 실내 환경의 변화에 따라 다른 결과값이 도출되거나, 기반 시설을 구축해야 하기 때문에 한계가 있다. 따라서 건물설계 혹은 실내 공간 계획을 하는데 있어서 공간를 이용하는 사람들의 행위 정보를 수집 및 분석하고 이를 이해하며 적절한 계획을 세우기 위해서는 이러한 비물리적 정보의 올바른 해석(WILSON, Thomas D. 2000)과 그것을 건축 설계 및 도시 계획 관계자들이게 효과적으로 전달하는 필수적(Scholten and Stillwell, 2013)이다.
본 연구는 이러한 필요성을 바탕으로 건물 출입하는 재실자와 유동인구에 대한 인식된 정보를 효과적으로 분석하여 건물 내 실제 재실자에 대한 인식 기술 및 카운팅 기술을 연구하는 것을 목적으로 한다. 재실자를 효과적으로 인식하기 위한 방법과 이를 효과적으로 전달하기 위한 시각화 모델을 개발하는 일련의 과정을 수행하였다. 이를 통해, 건물 내 재실자 수 파악 및 데이터 시각화를 통한 적절한 건물 설계 및 도시 계획 수립에 기여하는 것을 목표로 한다.
1.2. 연구의 필요성
1.2.1 영상정보를 기반으로 한 데이터 분석환경 구축
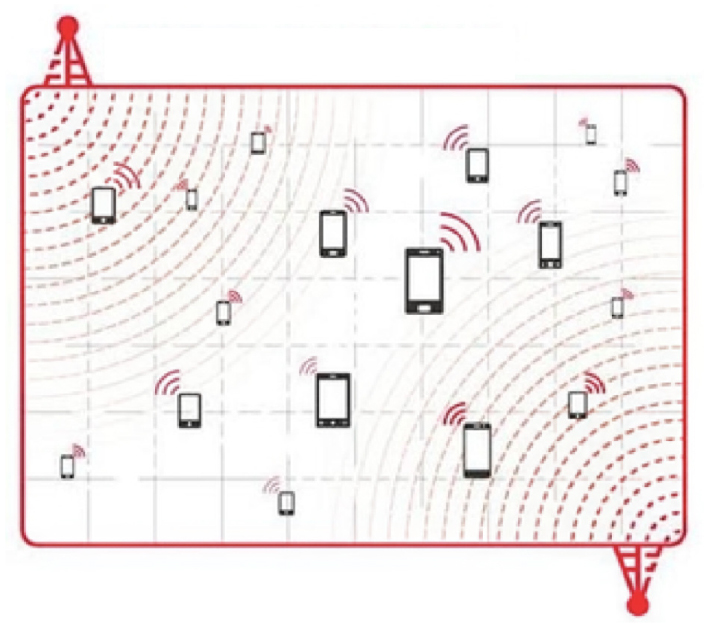
현재 빅데이터 분석을 위한 공공데이터의 지역 단위의 최소 단위는 읍,면,동 단위로 제공되고 있다. 또한 건축 및 도시 분석에서 가장 많이 사용되고 있는 통신사의 유동인구 데이터셋의 경우 Figure 1과 같이 50m x 50m 격자형 데이터로로 수집되는 pCell 형태가 대표적으로 활용되고 있다(Jung and Nam, 2018). 하지만 이러한 통신사 정보 및 센싱 데이터 형태의 경우 실제 건물을 사용한 유저의 행태를 포함한 위험, 재난, 특이사항을 검출하기엔 어려움이 있다.
본 연구를 통해 건축물 내 실제 사용자의 수, 이용행태 등의 데이터를 영상 정보를 통해 추출하여 수치화 진행하고 이를 바탕으로 건축 및 도시 분야에서 활용될 수 있는 건물 내 재실자 수 파악에 대한 가능성을 연구하고자 한다.
2. 선행연구 검토
본 연구에서는 기계학습을 활용하여 비디오 판독 및 재실자 파악을 수행하고자 함에 따라, 관련된 선행 연구들을 참고하여 본 연구의 방법론을 개발하고 구체화할 계획이다.
첫 번째 선행 연구로, Alahi et al.(2016)은 LSTM(Long Short-Term Memory) 기반의 딥러닝 모델을 사용하여 다중 행인의 움직임을 예측하고 추적하는 방법을 제안하였다. 이 연구는 공공 장소에서 재실자를 파악하는 데 활용될 수 있는 방법론을 제공하며, 본 연구에서도 이와 유사한 접근 방식을 사용하여 재실자 파악을 수행하였다. 특히, LSTM 기반의 딥러닝 모델을 활용하여 각각의 행인을 추적하고 분석함으로써 재실자의 수를 정확하게 파악할 수 있다. 두 번째로, Zou and Ye(2019)는 이미지 레벨의 감독을 통해 객체 계수와 인스턴스 세분화를 동시에 수행하는 기계 학습 기반 방법을 제안하였는데, 이 방법은 다양한 객체 유형에 대해 재실자 및 객체 계수를 추정하는 데 사용될 수 있으며, 본 연구에서도 객체 인식과 재실자 수 추정을 위해 참고할 방법론으로 사용하였다. 이를 통해 복잡한 환경에서도 정확한 재실자 수와 객체 계수를 도출할 수 있다. 마지막으로, Chen et al.(2018)은 여러 비디오 시퀀스에서 크라우드 카운팅 및 프로파일링을 수행하는 방법을 제안하였는데, 이 연구는 재실자 수 추정 및 행동 프로파일링에 사용될 수 있는 기법을 개발하였으며, 본 연구에서도 이와 같은 목표를 달성하기 위해 이 연구의 방법론을 참고할 계획이다. 따라서, 비디오 시퀀스에서 추출된 데이터를 바탕으로 재실자의 행동 패턴을 분석하여 다양한 환경에 적용할 수 있는 프로파일링 기법을 활용하였다.
종합적으로, 이러한 선행 연구들은 기계학습을 사용하여 비디오 판독 및 재실자 파악에 관한 다양한 방법론을 제시하고 있다. 본 연구에서는 이러한 선행 연구들의 방법론을 참고하여, LSTM 기반의 딥러닝 모델, 이미지 레벨의 감독을 통한 객체 계수와 인스턴스 세분화, 그리고 비디오 시퀀스에서 크라우드 카운팅 및 프로파일링을 수행하는 방법을 활용하여 종합적으로 구축하였다. 이를 통해 다양한 환경에서 정확한 재실자 수 및 행동 패턴을 분석하고 예측하는 데 활용할수 있는 모델로 기대한다.
3. 연구 방법
3.1 연구의 범위
건물 출입을 위한 사람들의 행위가 기록되는 영상 데이터가 갖는 특징을 살펴보면, 기본적으로 이동에 따른 “방향성”과 “위치 및 시간을 기반으로 하는 정보”와, “건물에 진출입을 통한 실시간으로 변화하는 재실자의 수의 업데이트” 등의 실시간으로 영상 정보의 분석과 업데이트가 이루어지는 복합적 데이터 처리가 필요한 특징을 가지고 있다. 또한 영상 분석(방향성 인식)과 예측 불가적인 요인이 발생하여 단일 영상분석으로 특정 공간, 특정 층수의 정확한 재실자 관련 정보 파악에 어려움이 있다.
본 연구에서는 이러한 인간의 방향성과 변동성을 인식하고 높은 정확성으로 실제적으로 건물에 들어온 사람을 인식하고 이를 시각화 할 수 있는 프로토타입 모델 구축을 목표로 하고 있다.
3.2 데이터 수집
분석으로 사용된 영상은 고정 설치된 CCTV 카메라의 AVI 동영상 클립을 형식을 사용하였다. 영상의 크기는 640 x 480으로 각각 10분씩의 길이를 바탕으로 재실자의 방향과 특정 위치를 지나면 카운팅이 되는 방식으로 측정하였다. 또한 단순 객체 인식과 방향성을 타나내는 방식, 방향성을 바탕으로 특정 위치를 지나면 카운팅 하는 방식으로 구분하여 비교 분석하였다.
촬영 공간의 경우 주차장에서 진입하는 영상과 오르막 거리에서 올라오는 골목길 영상으로 건물의 진출입과 거리의 이동성 분석을 통해 건축과 도시 분야에서 사용 될 수 있도록 시도해 보았다.
3.3 영상 인식 및 분석 알고리즘
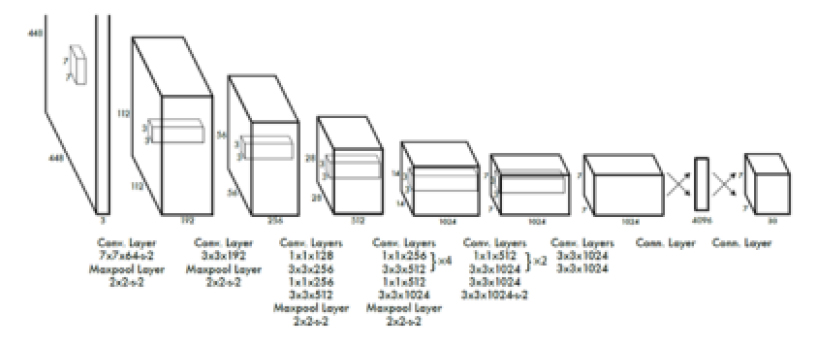
이미지 혹은 프레임에서 물체를 감지 알고리즘에는 대표적으로 Figure 2의 CNN algorithm 을 비롯하여 Haar cascades, HOG + Linear SVM, Faster R-CNN, YOLO 및 Single Shot Detectors(SSD)의 딥러닝 기반 물체 검출 알고리즘을 비교 분석하였고, 본 분석에 사용된 모델은 MobileNet 네트워크로 SSD(Single Shot Detectors) 방식을 사용하여 객체 검출을 하였다.

Figure 3과 같이 객체 검출을 하는데 있어 이 모델은 20개의 클래스를 지원하며, MS COCO데이터셋에 의해 사전 훈련된 Caffe모델을 바탕으로 실제 데이터를 분석 및 예측하는 방법으로 진행되었다.
알고리즘의 구성은 사전 훈련된 모델을 바탕으로 출입구에 고정된 카메라에 방향을 인식하여 진입 혹은 출입하는 재실자를 인식하고 분석하여 재실자의 수를 결과로 출력하도록 하였다.
4. 기계학습을 통한 인식모델 구축
본 연구에서 재실자의 방향에 따라 그룹을 두 가지로 구분하고 각 UP과 DOWN의 방향 별 사람이 인식된 수를 파악하고 수치화 하였다. Figure 4는 사전 훈련된 모델로 실시간 사람을 인지하는 것을 보여주는 것으로 움직임과 크기 속도에 따라 정확도는 지속적으로 변화였지만 대부분의 상황에서 올바르게 추적, 인지하였다.

또한 객체 인식에 대한 범주를 차량, 오토바이, 자전거 등으로 확대 할 경우 각 범주마다의 인식률과 교통량 등을 그룹화하고 범주에 따른 각각의 값을 도출 하는 것이 가능하였으나 본 연구에는 보행자에 한해서 연구를 진행하였다.

비디오의 후속프레임과 전 프레임에서의 이동을 측정하기 위해 옵티컬 플로우(OpticalFlow)를 사용하여 방향에 대한 정의도(Lee, 2018) 가능하다는 것을 확인하였다(Figure 5).
인식의 최종 결정단계에 Opencv와 dlib를 사용하여 객체에 대한 인식과 추적을 동시에 진행하여 해당 객체가 지정되어 있는 선을 넘어갈 경우 카운팅을 하는 알고리즘으로 카운팅 시스템이 구동 될 수 있도록 하였다.
방향이 바뀜에 따라 카운팅이 각기 항목에서 이루어 질 수 있으며, 이를 통해 건물의 IN과 OUT을 나누어 카운팅 할 수 있다. Figure 6, 7, 8은 가상의 구분경계를 설정하여 객체의 이동 방향을 인식하는 것으로 인식된 물체의 방향을 인지하도록 하였다.



고정된 카메라가 계단실, 출입구, 엘리베이터 등에 설치 된다면 해당 층의 재실자와 특정 건물안에 전체 재실자 수의 분포에 대해 정보 수집이 가능하며 이 수치에 근거해 건물 내 분포를 시각화 할 수 있을 것으로 보인다. 전제적인 의사결정과정은 아래의 Table 1에 정리하였다.
Table 1.
Overall Decision-making Process for Data Processing using Machine Learning-based Recognition Model
5. 결론
비디오 영상 정보를 바탕으로 기계학습을 이용하여 재실자의 진출입에 대한 상태를 감지하고 파악하였다.
대부분의 경우 대상 추적, 지정된 선을 넘어갈 경우 카운팅 등의 세 가지 부분에서 높은 정확도를 보였으나, 여러 한계점과 문제점이 도출되었다. 먼저, 움직이는 객체가 지나치게 빠른 경우 인식률이 낮아지고, 다양한 행동이나 어두운 옷 착용 시 정확도가 떨어진다. 이는 카메라 해상도와 조명 등 외부 환경 조건이 인식에 영향을 주기 때문이다. 이를 개선하기 위해서는 카메라 성능 향상, 조명 조건 최적화 및 영상 전처리 기술 개발이 필요할 것으로 보인다. 그리고, 기계 학습 및 딥러닝 알고리즘의 정확도 문제가 있다. 완벽한 정확도를 가진 시스템 구축은 어려워 일정 수준의 오차가 존재한다. 이를 보완하기 위해 알고리즘 개선과 지속적인 데이터 수집 및 학습이 필요하다. 마지막으로 개인정보 보호와 관련된 문제가 있다. 연구에 사용된 CCTV 영상은 개인 식별이 불가능한 낮은 해상도를 가지나, 기계학습을 활용한 분석 결과는 정상적인 운영이 가능하다고 보여진다. 그러나 데이터 처리 시 개인정보 침해를 방지하기 위해 비식별화 및 보안 관리가 필요하다.
Table 3은 정확도에 영향을 미치는 요소를 분석하여 문제해결을 위한 방향을 정리 하였다. 후속 연구에서는 원본 동영상의 보정 및 전처리, 카메라 조정, 카메라 보정 등을 통해 정확도에 영향을 주는 요인을 개선하고, 오차를 줄일 수 있는 방안에 대한 연구가 필요하다. 이와 같은 연구를 통해 더욱 발전된 시스템을 구축하고, 다양한 환경에서의 인식 성능 개선을 위해, 기계학습 모델의 훈련 데이터를 다양한 조명, 배경 및 움직임 조건을 포함하도록 확장해야 할 것으로 판단된다. 더욱 정교한 모델 구조를 도입하거나, 기존 모델을 미세 조정(fine-tuning)하여 인식률을 향상시킬 수 있으며, 다양한 카메라 각도 및 설치 위치에 대응하기 위해, 카메라 보정 및 투영 변환과 같은 기술을 활용하여 인식 과정을 개선할 수 있을 것으로 보인다.
Table 2.
Results of object-specific identification based on detection






Table 3.
Issues and improvement measures
어두운 옷을 입은 사람이나 복잡한 배경에서의 인식률을 높이기 위해서는, 모델 훈련 시 색상, 명암 및 텍스처와 같은 다양한 시각적 특성을 고려하는 것이 중요하다. 이를 위해, 훈련 데이터에 색상 변형, 명암 변환 및 노이즈 추가 등의 데이터 증강 기법을 적용할 수 있을 것으로 보인다.
빠르게 움직이는 객체의 인식 성능을 개선하기 위해서는, 영상 프레임 사이의 움직임을 더 정확하게 추적할 수 있는 기술을 사용해야 한다. 이를 위해, 고속 옵티컬 플로우 기법이나 적응적 프레임 간격을 도입하여 객체의 움직임을 더욱 정확하게 추적할 수 있도록 하는 것이 도움이 될 것으로 보인다.
또한, 높은 해상도 CCTV 영상의 활용 제약을 극복하기 위해, 초해상도 기술(Super-Resolution)을 도입하여 낮은 해상도 영상을 개선하는 방법을 고려할 수 있다. 이를 통해 개인정보 보호와 인식 성능 간의 균형을 유지하면서 보다 정확한 인식 및 분석이 가능해질 것으로 보여 후속연구를 계획하는데 도움이 될 것으로 판단된다.
6. 활용 방안에 대한 제안
6.1 건물내 재실자 빅데이터 구축 및 활용 방안에 대한 연구
거리에서 도시적 스케일에 있어 길에 대한 구체적인 보행자, 차량, 자전거 등 다양한 카테고리에 대한 통행량 및 방향성에 대한 유동인구 분석과 실시간에 가까운 도시 내 유동성에 대한 측정과 분석이 가능하며 지속적인 운영으로 인식의 정확성 을 높일 수 있다(Figure 9, Figure 10).
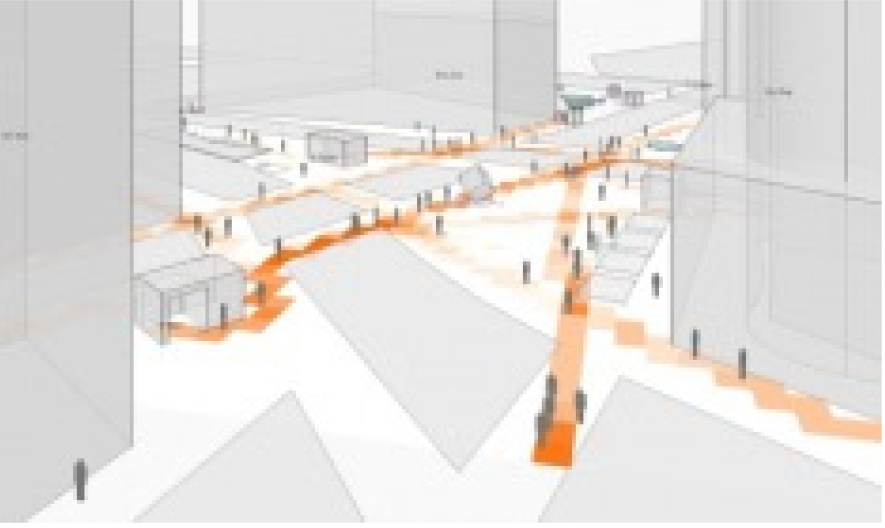
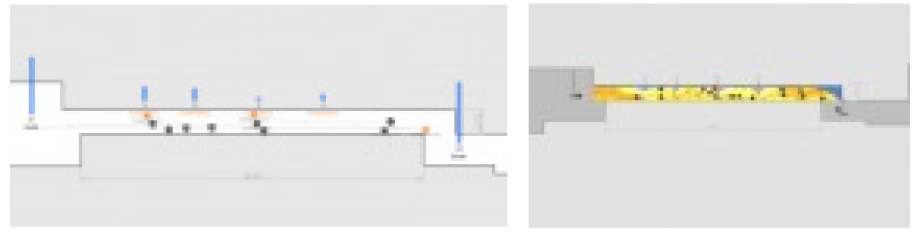
Figure 10.
Flow rate and directionality of corridors, etc. in individual buildings Leverage visualization for space design(https://www.buymeacoffee.com/)
거리에서 건물 내로 유입되는 유동인구를 진 출입구에 고정된 CCTV영상을 바탕으로 추적, 카운팅을 통해 복도와 같은 실내공간에 대한 유동성과 방향성을 측정 할 수 있다. 이는 인간 행태에 대한 정보로써 상업공간의 설계와 공간의 배치, 실 배치에 사용 될 수 있다.

또한 구현된 Deep Learning 알고리즘을 확대하여 건물 내 CCTV로 취합된 각 출입구, 엘레베이터, 복도 별 영상 정보를 기준으로 연령, 성별, 특이사항(휠체어) 등의 재실자의 정보를 일정 정확도 이상의 객체를 탐지, 추적, 수치화 진행하고 이를 데이터베이스에 전송, 탐지된 재실자의 수를 저장하는 환경 구축에 활용이 가능하다.

또한 Figure 12와 같이 수집된 재실자 데이터에서 연령별, 성별, 특이사항 별로 재분류를 통해 고위험군과 상대적 저위험군으로 각각 클러스터링을 하여 시각화를 바탕으로 CCTV의 영상정보를 건물 전체의 상대적 고위험군과 상대적 저위험군의 수치정보로 변환하여 재난시 구조 우선순위를 정하는 환경 구축 등 다양한 활용이 다양할 것으로 기대한다.

여기에 더하여 사람으로 인식된 정보를 층별로 재분류를 진행한다. 해당 알고리즘의 경우 추적된 객체가 화면 내에 지정된 선을 넘어 갈 시 아이디를 부여하고 이를 따로 카운팅 할 수 있다. 이를 바탕으로 계단의 아래와 위를 분리하고 각각 층을 이동 할 때마다 변동하는 층별 재실자의 수를 인공지능 알고리즘이 자동으로 파악하여 수치화 한다.
Figure 13의 경우 계단, 엘리베이터 등 중심 코어의 단순 진출입의 경우를 카운팅 할 때 사용되며 Figure 14, 15의 경우 사무실, 상가, 다가구, 다세대 주택, 초등학교의 각반, 병원의 병실 등 한 층내에서 세분화 되어 각각의 공간, 실로 쪼개어진 성격을 가진 시설에 사용되어 각 방마다의 재실자 수를 재 카운팅 하는 환경을 가시화한 이미지이다.


이를 통해 CCTV영상을 통합적으로 취득하여. Figure 11의 예시처럼 건물 전체의 재실자 수를 파악하고. Figure 12에서 각 층마다의 정보를 재취합하여 상대적 고위험군을 분류하고, Figure 14에서 각 실마다의 재실자를 한번 더 파악하는 등 3단계의 걸친 재실자 수 파악 알고리즘을 통해 정확한 재실자 검출을 진행할 수 있다(Moon et al., 2009). 또한 건물 내의 상주하는 사람에 대한 간단한 정보, 요약, 위험도 등의 정보를 비식별화(각기 인원에 대한 얼굴 등의 정보는 삭제) 처리되어진 수치 정보로 치환하여 데이터베이스를 구축할 수 있다.
계단실, 엘리베이터, 복도의 CCTV 영상을 바탕으로 실과 방 별 재실자 수 파악이 가능하며 이를 통해 층마다 해당 정보를 시각화 할 수 있다. 이는 각 개별 건물에 대한 재실자 정보를 모두 내포 할 수 있으며, 실별 분포, 층별 분포 등으로 공간 설계에 사용 될 수 있다. 또한 기존 건물에 대한 재실자 분포와 프로그램을 서로 비교 분석하여 이를 새로운 프로그램 설정에 대한 의사결정에 도움이 될 수 있을 것으로 기대한다.
6.2 건축, 도시 스케일의 차세대 시각화 방안 연구
이러한 연구를 바탕으로 단순한 CCTV설치만으로 도시의 블록별, 건물의 층별, 더 나아가 실별 재실자 수를 수치화 된 정보를 수집하고 데이터베이스를 구축하여 확보된 건축, 도시 빅데이터를 AR(증강현실) 환경을 활용하여 건축, 도시 빅데이터에 대한 새로운 데이터 시각화방안이 제시 된다면 더욱 효율적인 의사 결정이 가능할 것이라고 판단된다(Rathore et al., 2016).
또한 구축된 데이터베이스를 GIS시스템과 결합해 소방관의 AR 디스플레이, 휴대폰 어플리케이션 등 까지 지원한다면 화재, 안전 및 인명 구조, 대피에 있어서 효과적일 것으로 보인다.

기계학습을 통해 영상정보에서 수치정보로 전환된 재실자의 수치 데이터를 바탕으로 건물 내에 상주하고 있는 재실자 수에 대한 빅데이터 환경을 구축하여 거리에서부터 건물, 도시의 스케일까지의 연속된 재실자 분석과 이를 시각화하여 재난에 따른 대피와 구조 등 인명 구조에 사용 할 수 있다 (Figure 20).

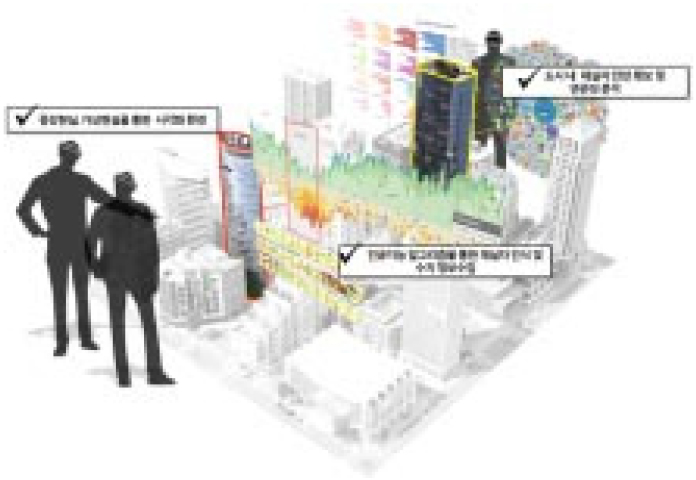
구조대는 AR(augmented reality)을 통해 각 실별, 각 층별 정보를 소방관 HUD(Head Up Display)의 부착하여 마지막으로 수집된 정보를 바탕으로 빠른 구조 작업을 펼칠 수 있도록 구출, 구조 계획을 수립 할 수 있다. 이를 화재현장에서 진압작전을 펼치는 대원에게 정보의 제공, 최신 현황 정보의 제공을 통해 효율적인 인명구조 계획 등 다양한 의사결정에 도움을 줄 수 있을 것이다.
또한 날씨, 카드 사용량 등 다양한 변수를 합쳐 재난, 위험 등을 예측 할 수 있으며, 기존 건물에 대한 재실자 분포와 기존 프로그램을 서로 비교 분석하여 이를 새로운 건물 설계 시 프로그램 설정에 대한 의사결정에 도움이 될 수 있을 것으로 기대한다.
앞선 인공지능을 바탕으로 한 빅데이터 수집 능력과 AR(증강현실)환경에서 시각화를 구현하여 건물을 설계함에 있어서 4차 산업혁명에 부합되는 건축, 주택, 단지 등의 활용 될 수 있다. 이를 활용하여 ‘안전’을 중심으로 한 고부가 가치산업과 연계 할 수 있을 것으로 기대한다.
