

1. 서론
2. 디지털맵 시계열 변화분석 프레임워크
3. 기술개발 데이터셋 구축
3.1 데이터 취득 및 생성
3.2 데이터 전처리
4. 프레임워크 적용기술
4.1 지형분류 기술개발
4.2 분석범위 일치화 기술개발
5. 프레임워크 성능검증
5.1 성능검증 평가지표
5.2 지형분류 기술 성능검증
5.3 분석범위 일치화 기술 성능검증 결과
6. 결론
1. 서론
최근 건설산업은 생산성 향상을 목표로 AI, BIM, 로보틱스, 3D 프린팅 등을 도입함으로써 건설자동화 관련 기술개발에 힘쓰고 있다(Pan et al., 2018). 하지만 다양한 노력에도 불구하고 건설산업은 제조 및 정보통신 분야와 비교하여 디지털화를 적용함에 따른 생산성의 향상 정도가 여전히 낮은 수준인 것으로 분석되고 있다(Barbosa et al., 2017). 특히, 최근 국내 건설산업의 고령화에 의해 생산성 저하 문제를 직면하고 있어 더욱 높은 수준의 디지털화 기술 도입에 따른 생산성 증대가 절실하다(Park and Kim, 2019).
이에 최근 생산성 증대에 효과적인 드론 및 3차원 스캐닝 기술 등과 같은 스마트 건설기술은 실제 현장을 간편한 방법으로 디지털화 할 수 있다는 측면에서 빠른 기술발전을 이루고 있다(kim et al., 2017). 또한 3차원 포인트 클라우드 데이터 생성기술 중 하나라고 할 수 있는 리얼리티 캡처 기술의 발전으로 인해 경제적으로 높은 정확성의 스캔 데이터 계측이 가능하다(Wang and Kim, 2019). 특히, 디지털맵은 토공 중장비 및 현장 관제 등에 활용될 수 있는 건설 자동화에 대한 기초자료로 널리 사용될 수 있어, 타 건설산업의 첨단기술과의 연계 측면에서 더욱 효과적이라고 할 수 있다.
디지털맵은 계측 및 도화작업을 통해 생성될 수 있으며, 이후 용도에 맞게 여러 전처리 과정을 거쳐 디지털맵이 가공된다. 또한, 포인트 클라우드는 X, Y, Z 좌표로 구성되어 있으며 객체표면의 위치관계 및 메타데이터 정보 등을 포함하고 있어 디지털 정보로써 높은 활용성을 지니고 있다(Kim and Park, 2015).
일반적으로 대규모 토공현장의 디지털맵을 생성할 경우에는 노이즈 제거, 정합, 병합 등의 디지털맵 생성을 위한 기초적인 전처리 과정을 수행하게 된다(Park et al., 2021). 노이즈 제거의 경우 대표적으로 스캐너의 성능 및 현장의 환경적 요인에 의해 발생 가능한 지형 스캔데이터의 노이즈를 제거하는데 사용되며(Park and Kim, 2020) 정합 및 병합은 서로 다른 건설현장 구역에서 중첩되게 취득한 포인트 클라우드를 한 개의 디지털맵으로 생성하기 위해 사용된다(Park and Kim, 2021).
나아가, 다양한 전처리 과정을 거쳐 생성된 하나의 토공현장 디지털맵은 토공현장에 대한 다양한 정보로 활용할 수 있다. 특히, 토공현장의 경우 공사의 진행 상황을 파악할 수 있는 관제의 기초자료로 활용이 가능하며 나아가 시계열 디지털맵을 활용한 토공현장의 토공량 산정으로 이루어질 수 있다(Kim et al., 2022).
하지만 생성된 시계열 데이터간 디지털맵 분석 시에는 공사가 진행됨에 따른 초목과 같은 비지형에 의한 변화가 불가피하여, 이에 따른 변화정보의 오차가 발생하게 된다. 또한 공정에 따라 취득되는 디지털맵의 취득범위가 달라져 범위가 상이함에 의한 오차 또한 발생하게 된다.
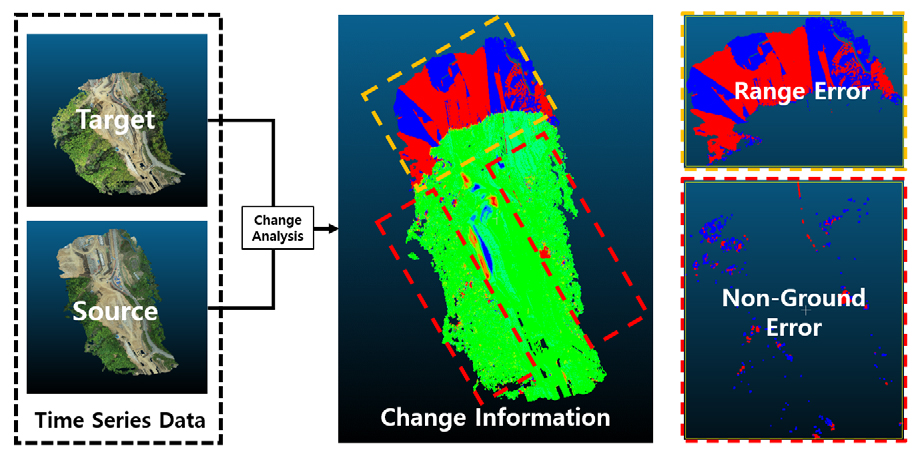
Figure 1에서는 디지털맵 분석시 발생 가능한 비지형 및 분석범위에 의한 오차의 실제 형태에 대해 나타내고 있다. 비지형 및 분석범위에 의한 오차는 토공량 산정 및 변화탐지 분석의 정확도에 매우 큰 영향을 미칠 수 있으며, 분석을 위한 연산속도를 저하시킬 수 있다.
이에 본 연구에서는 비지형 및 분석범위 불일치에 따른 오차를 최소화하여 분석의 정확도 및 속도 증진을 위하여 지형분류 및 분석범위 일치화 알고리즘을 개발함으로써 최종적으로 시계열 디지털맵 변화분석 성능을 향상시키고자 하였다.
2. 디지털맵 시계열 변화분석 프레임워크
본 연구에서는 토공현장 디지털맵의 시계열 변화분석 프레임워크에 대해 제시하고 있다. 프레임워크의 구성은 (1) 지형분류, (2) 범위 일치화, (3) 변화분석으로 Figure 2에서 3단계로 나누어 제시하였다. 이러한 이유는 시계열 데이터가 생성되었을 경우 (1) 지형분류는 각각의 데이터에 알고리즘을 따로 적용할 수 있어, 흐름상 가장 우선하여 수행하도록 구성하였고 (2) 범위 일치화의 경우 반드시 (3) 변화분석을 수행하고자 하는 두 개의 데이터를 활용하여 전처리 개념으로 범위 일치화를 수행하기 때문에 다음과 같은 순서로 구성하였다.
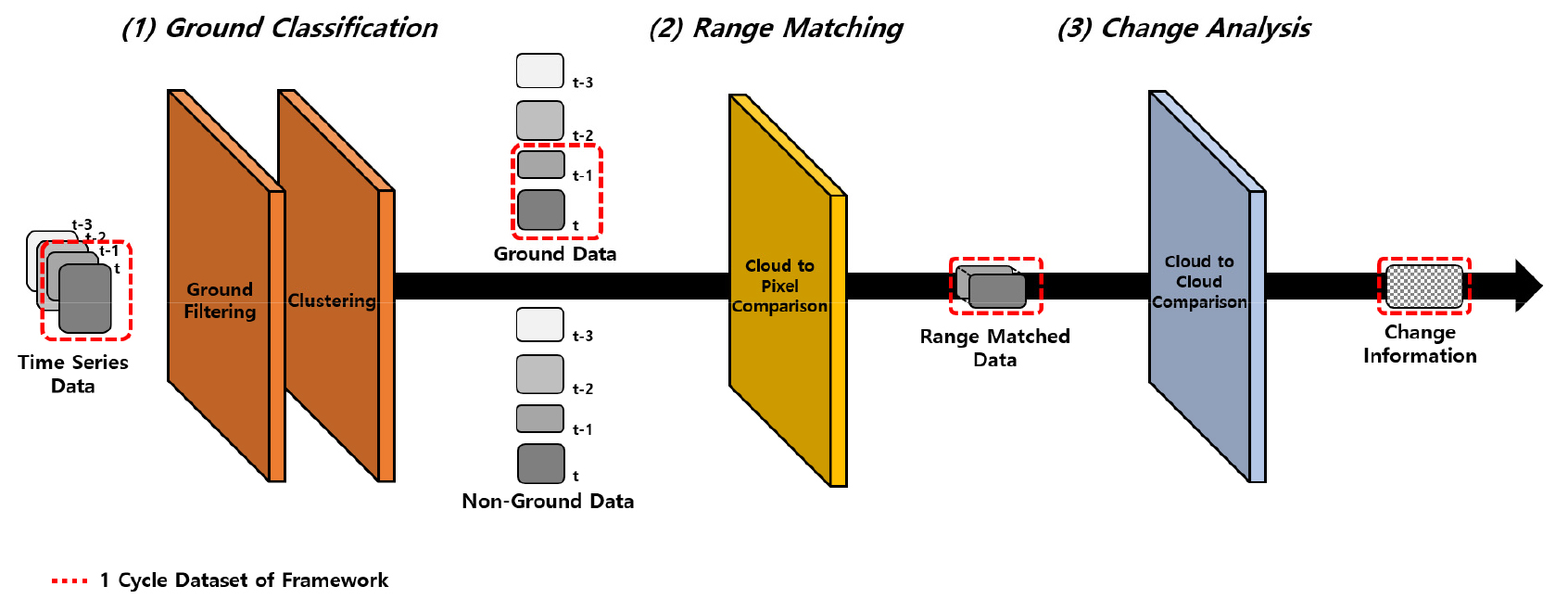
(1) 지형분류 단계는 토공현장 스캔데이터간 변화탐지시 오차의 주된 요인에 해당하는 비지형 데이터를 지형 데이터와 분류하기 위한 첫 번째 과정이다. 토공현장 디지털맵의 경우 토공의 해당하는 지형뿐 아니라 초목과 같은 비지형 데이터가 포함되어 있어, 비지형에 따른 토공 변화량의 오차가 발생하게 된다. 이에 디지털맵 분석 오차의 주된 원인에 해당하는 비지형 데이터를 지형 데이터와 분류하기 위해 지형학적 필터링 및 클러스터링 알고리즘을 활용하여 해결하고자 하였다.
(2) 분석범위 일치화 단계는 (1) 지형분류를 통해 생성된 시계열 디지털맵에 대해 변화탐지를 수행할 때 발생할 수 있는 분석범위 불일치 문제를 해결하기 위한 두 번째 과정이다. 이때 활용되는 데이터의 경우 1단계 프로세스를 통해 분류한 시계열 지형 데이터를 활용하여 변화탐지를 수행한다. 대부분 토공현장에서 얻어지는 디지털맵에 대한 크기 및 생성 범위는 공사가 진행됨에 따라 달라질 수 있어, 시계열 디지털맵을 그대로 변화탐지를 하게 된다면 범위가 서로 상이한 부분에 대해 오차가 발생할 수 있다. 이러한 오차를 해결하기 위해 본 프로세스에서는 픽셀기반 점군 비교 알고리즘(Cloud to Pixel Comparison, C2P)을 활용 및 변형하여 분석범위를 일치화를 수행하고자 하였다.
(3) 변화분석 단계의 경우 (1) 지형분류 및 (2) 범위 일치화된 디지털맵간의 변화탐지를 수행하는 마지막 과정이다. 변화탐지 방법으로는 시계열 데이터간 변화된 지형에 대해 Euclidean Distance를 기반으로 한 변화정보를 생성하고자 하였다. 나아가 변화정보를 통해 본 연구에서 제안하고 있는 변화분석 프레임워크의 성능검증 또한 수행하여 프레임워크의 우수성을 검증하고자 하였다.
3. 기술개발 데이터셋 구축
3.1 데이터 취득 및 생성
본 연구에서는 디지털맵 시계열 변화분석 프레임워크의 기술개발 및 성능검증 데이터를 구축하였다. 데이터 취득에는 DJI사의 Phantom 4 RTK 드론과 D-RTK 2 Mobile Station GNSS 장비를 활용하였으며, 데이터 취득장소로는 경기도 광주시에 위치한 도로 건설 현장을 대상으로 수행하였다. 나아가 시계열 데이터 취득을 일주일 단위로 4회 촬영하여 4가지 시점의 시계열 데이터셋을 취득하고자 하였다
Figure 3에서는 4가지 시점의 원시 시계열 데이터셋에 대한 실제 형태를 나타내고 있다. 또한 시계열 데이터의 바운딩 박스의 크기를 [X, Y, Z]의 형태로 나타내어, 공사가 진행됨에 따라 디지털맵의 취득범위가 서로 달라지는 것을 수치상 확인할 수 있다.

3.2 데이터 전처리
본 연구에서는 3.1절에서 취득한 원시 시계열 데이터를 활용하여 성능검증 데이터 구축을 위한 전처리 작업을 수행하였다. 이는 원시 데이터에서 발생할 수 있는 밀도 불균일 및 노이즈 문제를 사전에 방지하기 위해 밀도 균일화를 수행하였다. 또한 건설자재 및 건설중장비에 해당하는 객체를 수작업으로 삭제함으로써 디지털맵 내에 순수지형과 초목을 분류하는 것을 목적으로 하여 전처리를 수행하였다.
전처리 수행 방법으로는 첫 번째로 밀도 균일화를 위한 대표적인 다운샘플링 알고리즘인 복셀 그리드 필터를 활용하여 수행하였다(Kim et al., 2022). 다음 두 번째로 균일화된 데이터에 대해 CloudCompare 소프트웨어를 이용하여 건설중장비 및 건설자재에 대해 수작업으로 삭제함으로써 전처리 데이터를 구축하였다. 세 번째로 기술개발의 성능을 검증할 때의 기준 데이터라고 할 수 있는 검증 데이터 구축을 수행하였다. 구축에는 지형과 비지형을 CloudCompare 소프트웨어의 Crop 및 Merge 기능을 활용하여 수작업으로 정확히 분류함으로써 데이터 구축을 수행하였다. Table 1에서는 원시 데이터와 전처리 데이터의 포인트 개수(지형 및 비지형 데이터 포함)를 각각 나타내고 있다.
Table 1.
Number of points in raw and preprocessed data
4. 프레임워크 적용기술
4.1 지형분류 기술개발
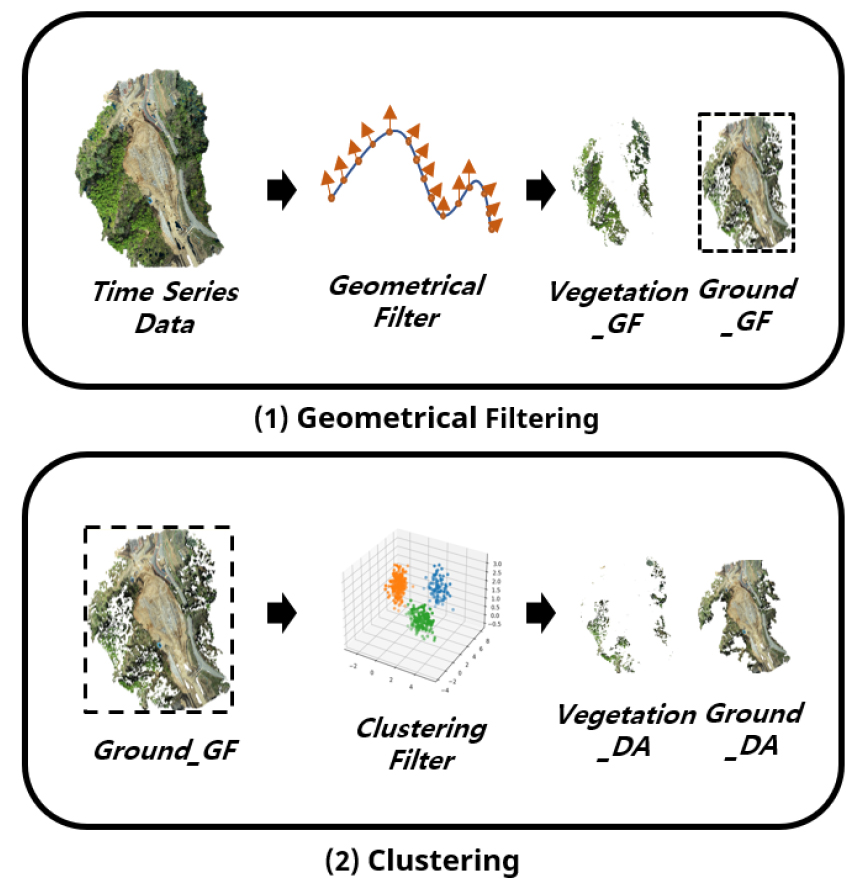
본 연구에서는 시계열 디지털맵 분석시 발생하는 비지형에 의한 오차를 최소화하기 위해 디지털맵의 지형 및 비지형을 분류하는 프로세스를 제시하고 있다. 프로세스의 구성은 (1) 지형학적 필터링, (2) 클러스터링으로 Figure 4에서 2단계로 나누어 제시하고 있다.
첫 번째 프로세스는 지형을 선제적으로 분류하는 방법으로 지형학적 필터링을 활용하여 지형 데이터와 비지형 데이터를 분류하는 프로세스이다. 이와 관련하여 4.1.1에서 대표적인 알고리즘을 선정하였고, 5.2.1에서 각 알고리즘간의 성능분석을 통해 최적의 알고리즘 도출을 수행하였다.
두 번째 프로세스는 지형학적 필터링을 통해 분류된 지형 데이터에 대한 분류성능을 향상시키기 위해 다시 한번 필터링을 수행하는 과정이다. 특히 이때 비지형으로 분류되지 않고 지형으로 분류된 점의 특성을 반영하여 밀도 기반 클러스터링 알고리즘을 적용함으로써 고밀도에 해당하는 점군을 지형으로 판단하고 저밀도에 해당하는 점군은 비지형으로 판단하여 지형과 비지형의 분류를 다시 한번 수행하도록 하였다. 이와 관련하여 4.1.2에서 최적의 클러스터링 알고리즘을 시각적 분석을 통해 도출하고 5.2.2에서는 도출된 DBSCAN 알고리즘에 따른 지형분류의 개선정도를 나타내었다.
4.1.1 지형학적 필터링
지형학적 필터링 기술은 포인트 클라우드 데이터의 지형학적 정보를 활용하여 지형과 비지형을 분류하는 기술로, 지난 30년 동안 수많은 종류의 기술이 개발되어왔다(Chen et al., 2017). 특히, 디지털맵에 적용할 수 있는 대표적인 필터링 기술로 Morphological Filtering과 Surface Based Filtering이 존재한다(Stroner et al., 2021). 본 연구에서는 성능검증 알고리즘으로 Surface Based Filtering의 Cloth Simulation Filtering(CSF)과 Morphological Filtering의 Progressive Morphological Filter(PMF), Simple Morphological Filter(SMRF)을 활용하여 성능검증을 수행하였다.
CSF 알고리즘은 3D 컴퓨터 그래픽 분야에서 사용되는 Cloth Simulation 기술을 스캔 데이터의 지면 분리에 적용할 수 있도록 고안된 방법이다(Zhang et al., 2016). 즉, 천 조각을 지형 위에 놓았을 때 강성에 따라 달라지는 천 조각의 최종모양을 활용하여 지형의 디지털 표면 모델(Digital Surface Model) 및 디지털 지형 모델(Digital Terrain Model)을 생성한다. 이처럼 두 가지 지형 및 표면 모델을 생성할 수 있는 특성을 활용하여 지형과 비지형을 분류하는 알고리즘이라고 할 수 있다.
Morphological Filtering은 동영상이나 이미지를 형태학적 관점에서 접근하는 기법(Anglin et al., 1993)으로 영상 내의 픽셀값 데이터를 주로 사용한다. 이에 PMF와 SMRF는 기존 2차원 데이터에 적용하였던 방법론을 3차원 데이터로 확장함으로써 3차원 데이터에 대해 형태학적 연산인 팽창과 침식을 기반으로 수행되는 알고리즘이다(Zhang et al., 2003). 각 셀에서 고도가 최소인 점을 선택하여 포인트에서 초기 고도 그리드를 생성하고, 미리 설정해둔 매개변수를 기반으로 형태학적 연산을 수행하여, 지형과 비지형을 분류하는 원리의 알고리즘이다(Wei et al., 2017). 특히 SMRF는 초기 고도 그리드에서 빈 셀을 보간화하기 위해 '페인팅 기술'을 사용한다는 점에서 PMF와 차이가 있다(Pingel et al., 2013).
4.1.2 클러스터링
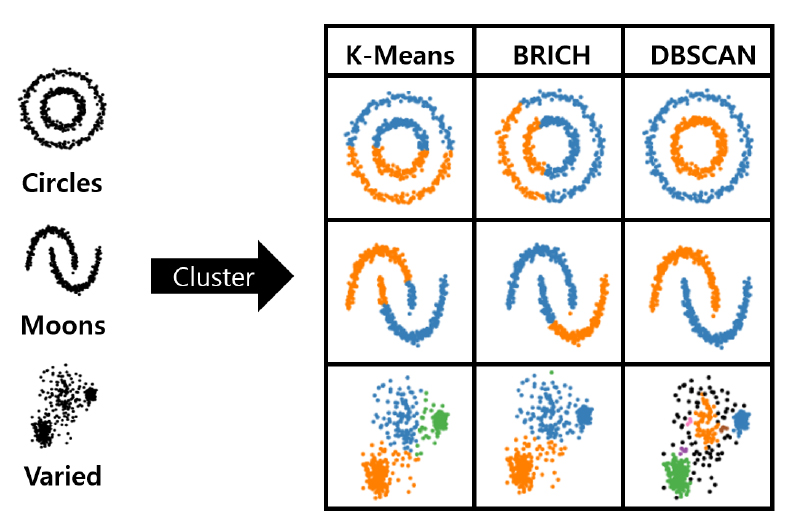
클러스터링이란 주어진 데이터 집합에 대하여 유사성을 가지는 클러스터로 분할을 수행하는 과정으로, 하나의 클러스터에 속하는 점들 사이에는 서로 다른 클러스터 내의 점들과는 구분되는 특징을 갖는다(Ruspini, 1969). 본 연구에서는 주로 점군을 대상으로 클러스터링을 수행하는 대표적인 알고리즘인 K-Means, BIRCH, DBSCAN을 선정하여 각각의 클러스터링 알고리즘 특성에 대한 시각적 분석을 수행하고자 하였다.
분석에 활용된 툴로는 세 가지 클러스터링 알고리즘 모두에 대한 시각적 분석을 수행할 수 있는 Scikit Learn을 활용하여 수행하였다. 분석에는 각각의 클러스터링의 특성을 효과적으로 보여줄 수 있는 Scikit Learn에서 제공하고 있는 인공 데이터인 Circles, Moons, Varied, Aniso를 활용하였다(Kramer, 2016).
이에 Figure 5에서는 Scikit Learn을 활용하여 시각적 분석 결과에 대해 나타내고 있다. K-Means와 BIRCH의 경우 Circles 및 Moons 데이터에 대해 올바른 클러스터링이 이루어지지 않은 것으로 나타났으며, DBSCAN의 경우 클러스터링이 올바르게 이루어진 것으로 나타났다. Varied 데이터의 경우 K-Means는 대체적으로 클러스터링이 잘 이루어진 것으로 나타났으나 노이즈에 해당하는 포인트 또한 클러스터로 포함하기 때문에 알고리즘이 노이즈에 민감할 것으로 예상할 수 있다.
BIRCH의 경우 녹색 포인트에 대한 클러스터가 제대로 이루어지지 않았으며 BIRCH 또한 노이즈에 민감하여 클러스터가 제대로 이루어지지 않은 것으로 판단된다. 이에 반해 DBSCAN의 경우 높은 수준의 클러스터 성능과 더불어 노이즈 제거 또한 가능하여, 노이즈 제거와 클러스터링을 동시에 수행하여 지형분류의 성능을 더욱 높여주기 위한 최적의 클러스터링 알고리즘으로 판단된다. 이에 본 연구의 최적의 클러스터링 알고리즘으로 DBSCAN을 선정하여 연구를 수행하였다.
4.2 분석범위 일치화 기술개발
본 연구에서는 시계열 디지털맵간의 변화탐지를 수행할 때 발생할 수 있는 분석범위 불일치 문제를 해결하기 위한 프로세스를 제시하고 있다. 나아가 분석범위가 일치화된 디지털맵간의 변화탐지를 자동으로 수행하기 위한 알고리즘을 제시하고 있다. 프로세스는 (1) 분석범위 일치화 (2) 변화탐지로 구성되어 있으며, Figure 6에서 2단계로 나누어 제시하였다.
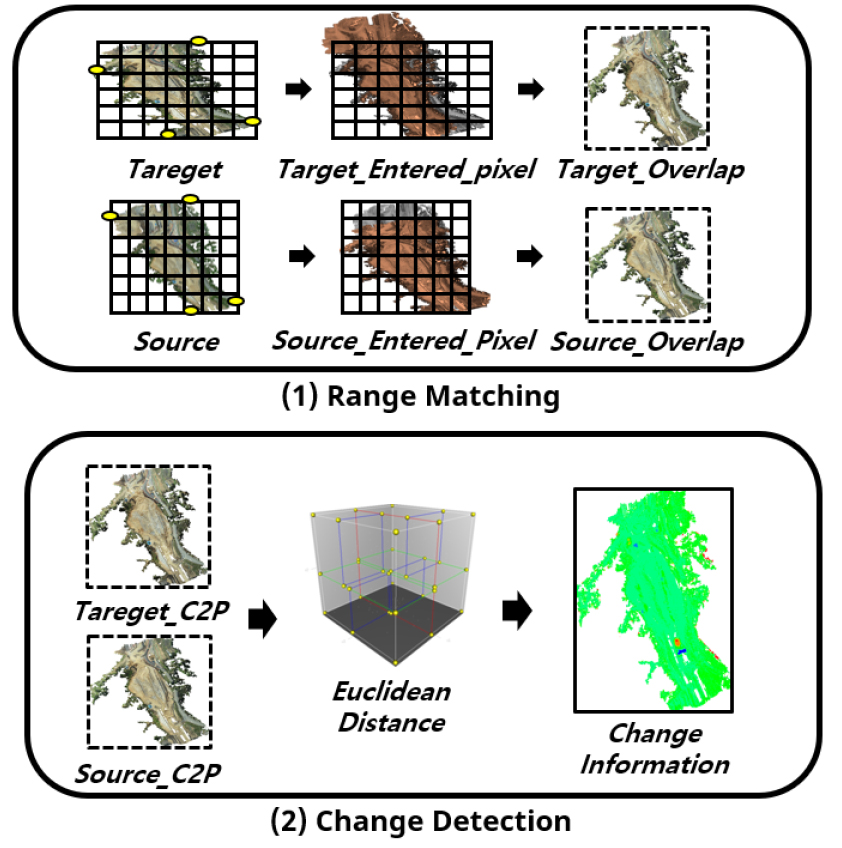
첫 번째 프로세스는 변화분석의 비교기준 데이터인 Target 데이터와 비교를 수행할 Source 데이터간의 중첩 부분을 분류하여 분석범위를 일치화를 수행하는 프로세스이다. 이에 픽셀기반 점군비교 알고리즘을 활용하여 Target 기준의 중첩 부분(Target_Overlap)과 Source 기준의 중첩 부분(Source_Overlap)을 각각 생성하여 분석범위 일치화 데이터를 생성한다. 적용된 알고리즘과 관련하여 4.2.1에서 자세히 설명하고 있다.
두 번째 프로세스는 중첩부분 분류가 완료된 Target_Overlap 및 Source_Overlap 데이터간의 변화탐지를 수행하는 프로세스이다. 이에 활용된 변화탐지 알고리즘은 유클리디안 방법론을 기반으로 KD-Tree를 활용하여 거리 연산을 수행하도록 하여 알고리즘을 개발하였다. 또한 연산을 통해 도출한 변화값을 활용하여 Source_Overlap 데이터에 색상을 매칭시켜 변화정보를 생성하도록 하였다. 이와 관련하여 본 연구에서는 4.2.2에서 자세히 설명하였다.
4.2.1 분석범위 일치화 알고리즘
분석범위 일치화 기술에 활용된 알고리즘으로는 정합시 발생하는 밀도 불균일 문제를 해결하기 위해 개발한 픽셀기반 점군비교 알고리즘을 활용하였다. 이러한 이유는 픽셀기반 점군비교 알고리즘의 경우 데이터간 중첩 및 비중첩 데이터에 대한 분류성능이 약 99%의 성능으로 분류할 수 있는(Kim et al., 2022) 장점이 있으며, 또한 이러한 장점은 본 연구의 데이터간 분석범위를 일치화 시키는 프로세스가 곧 중첩부분을 분류하는 알고리즘이라고 할 수 있기에 픽셀기반 점군비교 알고리즘이 분석범위 일치화 알고리즘에 적절할 것으로 판단하였다.
4.2.2 변화탐지 알고리즘
스캔데이터간 변화탐지를 수행하기 위해 활용되고 있는 대표적인 방법론은 Height Differencing, Euclidean Distance, Projection Based differences로 분류할 수 있다(Qin et al., 2016). 본 연구에서는 이론적 검토를 통해 Euclidean Distance 방법론을 채택하여 알고리즘 개발을 수행하였다. 이러한 이유는 Height Differencing의 경우 2.5 차원의 데이터의 변화탐지에만 적용이 가능하며, Projection Based Difference의 경우 균일한 밀도의 데이터에 대해 변화탐지가 누락 될 가능성이 있어 변화탐지를 위한 방법론에서 제외하였다.
포인트 클라우드는 비정형적이며 독립적으로 인접 포인트간의 거리가 고정되어 있지 않다(Bello et al., 2020). 이러한 점은 C2C 알고리즘을 활용한 변화탐지를 수행할 때 역시 적용되어 공간상 구조화를 수행할 필요가 있다(Shen et al., 2011). 본 연구에서는 변화탐지를 위한 구조화에 널리 활용되고 있는 KD-Tree기법을 활용하여 변화탐지 알고리즘을 개발하였다.
변화탐지 알고리즘의 프로세스는 입력데이터인 타겟 데이터와 소스 데이터에 대해 각각 KD-Tree 기법을 활용하여 공간상 구조화를 시킨 후 Euclidean Distance 기반의 C2C 알고리즘을 활용하여 변화된 거리를 계산하게 된다. 이후 계산된 값에 대하여 RGB Color에 대한 매칭을 수행하여 변화된 거리를 시각적으로 나타냄으로써 변화정보를 생성한다.
5. 프레임워크 성능검증
5.1 성능검증 평가지표
본 연구에서는 지형분류와 분석범위 일치화 기술의 성능을 검증하기 위한 평가지표 선정하고자 하였다. 지형분류 기술의 경우 비지형과 지형 데이터를 얼마만큼 정확히 분류되었는지 나타낼 수 있는 평가지표를 선정하고자 하였고, 분석범위 일치화 기술의 경우 변화분석의 결과값에 얼마만큼 오차 포인트가 생성되는지를 나타낼 수 있는 평가지표를 선정하고자 하였다.
5.1.1 지형분류 성능검증 평가지표
본 연구에서는 지형분류의 성능검증 방법으로 자카드 지수(Jaccard Index)를 지형분류의 성능검증 평가지표로 사용하였다. 자카드 지수는 두 데이터 집합 사이의 유사도를 정량화하는 데 사용되며, 0과 1 사이의 값을 가진다. 만약 두 집합이 동일할 경우 1의 값을 나타내며, 공통의 원소가 없을 경우 0을 나타내게 된다(Jaccard, 1912). 자카드 지수는 아래 식으로 정의된다.
자카드 지수는 불연속 집합을 갖는 특성의 데이터에 대한 유사도를 측정하는 지표로 널리 사용된다(Tanimoto, 1958). 이러한 불연속 집합에 대한 특징은 불연속한 점들의 집합으로 구성되어 있다고 할 수 있는 포인트 클라우드 데이터의 유사도 평가에 활용할 수 있는 평가지표로 판단되어 사용하였다.
특히 3.2절에서 지형 및 비지형 데이터로 정확히 분류된 검증 데이터의 점 개수를 기준으로 본 연구에서 개발한 지형분류 기술로 분류된 데이터의 점 개수와 유사도 검증을 통해 지형분류의 성능검증을 수행하고자 하였다.
5.1.2 분석범위 일치화 성능검증 평가지표
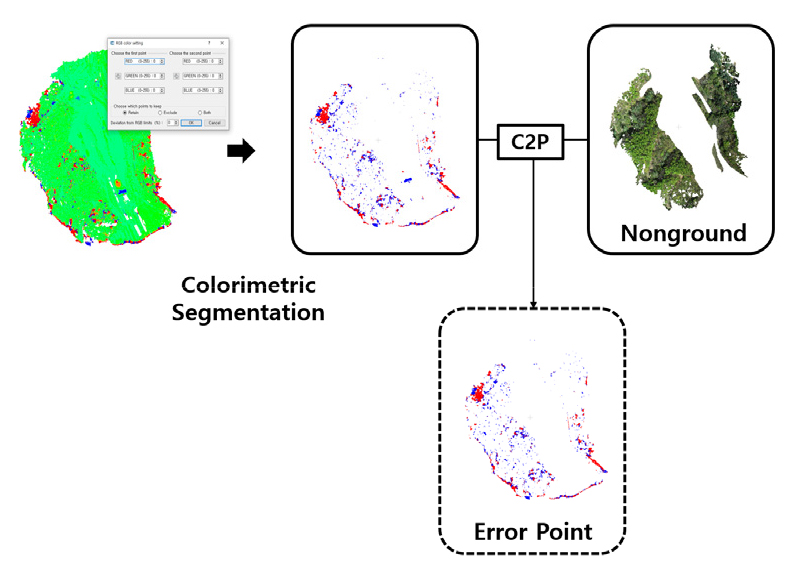
본 연구의 분석범위 일치화 프로세스의 성능검증은 변화탐지의 결과값을 활용해 Colorimetric Segmentation 분석을 수행하였다. 이는 변화탐지의 절토량을 나타내는 빨간색 RGB(255, 0, 0) 색상과 성토량을 나타내는 파란색 RGB(0, 0, 255 색) 색상의 포인트를 분류한 이후, 검증 데이터와 C2P 알고리즘을 수행하고 중첩부분을 추출하여 오차 포인트로 정의함으로써 성능검증에 활용하였다. 이러한 이유는 성토 및 절토를 나타내는 데이터는 지형 부분에 한정지어 나타나는 것이 올바른 변화탐지 형태이며, 비지형 부분에 나타나는 성토 및 절토 포인트는 오차로 판단하기 때문에 비지형의 절토 및 성토에 해당하는 포인트를 추출하고자 하였다. Figure 7에서는 변화탐지 결과값을 활용하여 오차 포인트를 도출하는 프로세스를 도식화하여 나타내고 있다.
5.2 지형분류 기술 성능검증
본 연구에서는 지형분류의 성능검증을 수행하였다. 먼저 지형분류 성능검증 프로세스는 테스트 데이터, 지형분류 데이터, 검증 데이터로 구성하였으며, 테스트 데이터는 3장에서 구축한 시계열 전처리 데이터를 활용하였다. Figure 8에서는 지형분류 성능검증의 프로세스를 도식화하여 나타내고 있다.
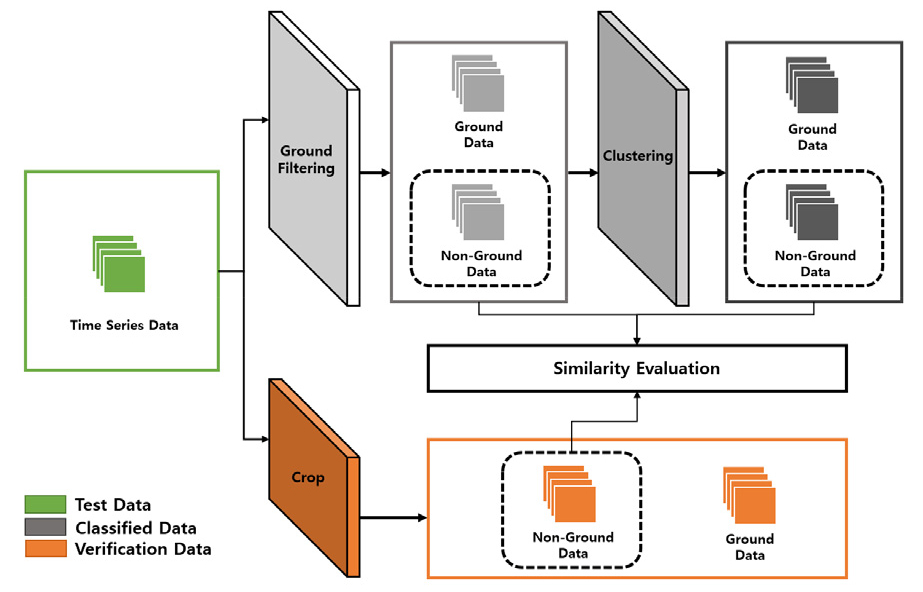
분류된 데이터는 지형분류를 통해 지형 및 비지형 데이터를 분류하여 생성된 데이터이다. 이때 본 연구에서는 각각 알고리즘에 의해 분류된 데이터 중 비지형 데이터를 활용하여 검증 데이터의 비지형 데이터와 유사도 평가를 수행하였다. 이러한 이유는 본 연구에서의 지형분류의 성능은 얼마만큼의 비지형 데이터가 올바르게 분류되었는지를 분석함으로써 지형분류의 성능검증 및 기술개발을 수행하고자 하였기 때문이다.
성능검증의 목적은 지형학적 필터링 및 클러스터링 알고리즘을 실제 현장 데이터에 적용하여 최적의 알고리즘 및 프로세스를 도출하고자 하였다. 지형학적 필터링에 대한 성능검증의 경우, 4.1.1에서 선정한 CSF, SMRF, PMF 알고리즘의 지형 및 비지형 분류성능을 분석하여 최적의 알고리즘을 선정하는 것에 중점을 두었다. 다음으로는 클러스터링에 대한 성능검증을 수행하였다. 이는 지형학적 필터링 이후 분류된 지형 데이터에 4.1.2절에서 선정한 DBSCAN 알고리즘을 적용함으로써 지형 및 비지형 분류의 성능의 개선 정도를 파악하는 것에 중점을 두어 성능검증을 수행하였다.
5.2.1 지형학적 필터링 알고리즘 성능검증 결과
본 연구는 4.2절에서 선정한 세 가지 지형학적 필터링 알고리즘의 지형 및 비지형 분류성능을 비교하여 최적의 알고리즘을 도출하고자 하였다. 형태학적 및 표면 기반 알고리즘은 데이터의 특성 및 환경에 따라 지형분류의 성능차이가 발생하여 우선적으로 최적의 파라미터를 도출해야 한다(Wei et al., 2017). 이에 본 연구에서 테스트 데이터에 대한 최적의 파라미터 값을 시행착오 기법을 활용하여 도출함으로써 연구를 수행하였다.
최적의 알고리즘을 도출하기 위한 기준은 각각의 알고리즘 파라미터를 초기 설정값을 기준으로 조정하였으며, 이때 최적의 분류성능에 대한 기준은 알고리즘을 적용하였을 때 비지형 포인트를 최대로 분류하고 잘못 분류된 점을 최소로 하였을 경우의 파라미터로 정하여 도출하였다. Table 2에서는 각 알고리즘에 대한 최적의 파라미터와 파라미터를 도출하기 위해 시행착오를 수행한 파라미터 값 및 최적의 파라미터 값에 대하여 나타내고 있다.
Table 2.
Optimal value of topographic algorithms
Table 3에서는 세 가지 알고리즘의 자카드 지수를 활용하여 백분율로 환산한 비지형 분류율을 나타내고 있다. 가장 높은 분류율을 보인 알고리즘은 SMRF로 약 50~70%의 분류율을 보였다. 가장 적은 분류율을 보인 알고리즘은 20~30%의 분류율을 나타낸 PMF 알고리즘이다. 데이터셋 마다 지형 및 비지형의 분포 및 형태가 상이하여 데이터셋 마다 분류성능의 편차가 다소 존재하지만, 본 연구에서는 세 가지 알고리즘 간 비교에서 모두 우위에 있는 SMRF 알고리즘이 형태학적 알고리즘에서의 최적의 알고리즘으로 선정하였다.
Table 3.
Classification rate by topographic algorithms
| Method | Test Data | |||
| Week 1 | Week 2 | Week 3 | Week 4 | |
| SMRF | 73.07% | 66.86% | 49.20% | 48.02% |
| CSF | 58.78% | 49.10% | 38.63% | 39.11% |
| PMF | 36.20% | 31.18% | 22.61% | 22.18% |
Figure 9에서는 분류된 비지형 데이터에 실제 형태에 대해 나타내고 있다. 붉은색 포인트의 경우 실제 지형 데이터를 비지형 데이터로 잘못 분류한 포인트에 대해 나타내고 있으며, 잘못 분류된 포인트가 가장 많은 알고리즘은 CSF 알고리즘으로 분석되었다. 이는 잘못 분류된 포인트가 적으면서 분류율 또한 가장 높은 SMRF가 최적의 알고리즘이라고 할 수 있다.

5.2.2 클러스터링 알고리즘 성능검증 결과
본 연구에서는 4.1.2에서 시각적 분석을 통해 선정한 클러스터링 알고리즘인 DBSCAN 알고리즘의 성능을 분석하고자 하였다. 성능분석에는 SMRF를 통해 분류된 지형 데이터에 대해 클러스터링을 수행하여 지형분류의 성능검증을 수행하였다.
Table 4에서는 SMRF의 분류율과 SMRF로 분류된 지형 데이터에 DBSCAN을 추가로 적용한 데이터의 분류율에 대해 나타내고 있다. SMRF 알고리즘만으로 분류할 경우, 분류율은 약 50~70%로 나타났지만, 만약 SMRF와 DBSCAN을 적용하였을 때, 약 70~80%의 분류율로 평균 약 20%의 지형분류의 성능이 개선된 것으로 나타났다. 또한 SMRF만 적용했을때에는 지형분류 성능간의 표준편차가 약 12.5%로 다소 큰 것으로 나타났지만 DBSCAN을 추가로 적용함에 따라 표준편차가 3.8%로 상당수 감소하여 지형분류 성능의 일관성을 유지할 수 있다는 장점이 있는 것으로 나타났다.
Table 4.
Classification rate by SMRF and DBSCAN
| Method | Test Data | |||
| Week 1 | Week 2 | Week 3 | Week 4 | |
| SMRF | 73.07% | 66.86% | 49.20% | 48.02% |
| SMRF+DBSCAN | 82.54% | 76.31% | 77.33% | 73.31% |
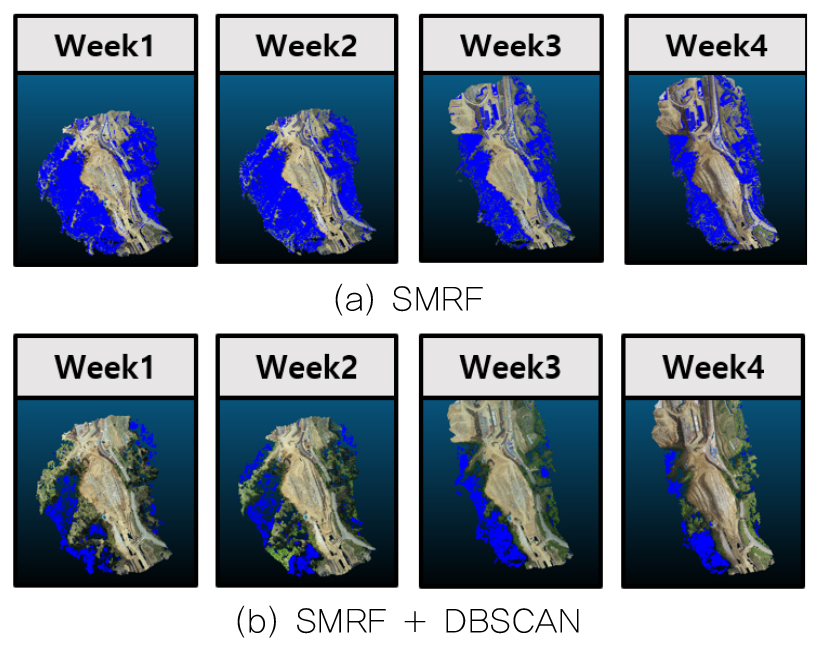
Figure 10에서는 SMRF와 DBSCAN을 통해 분류된 데이터의 실제 형태에 대해 나타내고 있으며, DBSCAN을 적용함에 따른 기존 대비 개선된 비지형 분류 데이터에 대해 파란색으로 나타내어 육안으로 개선정도를 확인이 가능하다.
5.3 분석범위 일치화 기술 성능검증 결과
본 연구에서는 분석범위 일치화 알고리즘의 성능검증을 수행하였으며, 더 나아가 본 연구에서 개발한 프레임워크 적용 전/후 성능을 검증하였다. 성능검증의 방법은 앞서 선정된 각 기술에 대한 최적의 조합을 선정하고자 하였다. 성능검증에 활용된 데이터는 변화탐지 알고리즘의 결과값의 실제 형태와 오차 포인트 개수를 분석하여 성능검증을 수행하였다.
먼저 분석범위 일치화 및 시계열 변화분석 프레임워크의 성능검증 프로세스는 테스트 데이터, 변화 데이터로 구성되어 있다. 테스트 데이터로 3장에서 생성한 전처리 데이터를 활용하였다. 이러한 이유는 본 연구의 성능검증은 총 4가지 경우의 수로 (1) 기술을 적용하지 않았을 때 (2) 지형분류 기술만을 적용하였을 때 (3) 분석범위 일치화 기술만을 적용하였을 때 (4) 지형분류 기술과 분석범위 일치화 기술 모두를 적용하였을 때에 대하여 모두 검증하고자 하기 위해서는 프레임워크를 적용하지 않았을 시점의 데이터를 활용하는 것이 적절하기 때문이라고 판단하였다.
테스트 데이터를 활용한 변화탐지를 수행하기 위해서는 시계열 데이터간의 비교 시나리오에 대한 정의가 필요하다. 본 성능검증에서는 실제 현장에서 취득된 데이터의 시간 순서대로 타겟과 소스 데이터를 각각 Case1(t-3, t-2), Case2(t-2, t-1), Case3(t-1, t) 데이터를 정의하여 성능검증을 수행하였다. Figure 11에서는 분석범위 일치화 및 시계열 변화분석 프레임워크 성능검증 프로세스에 대해 나타내고 있다.
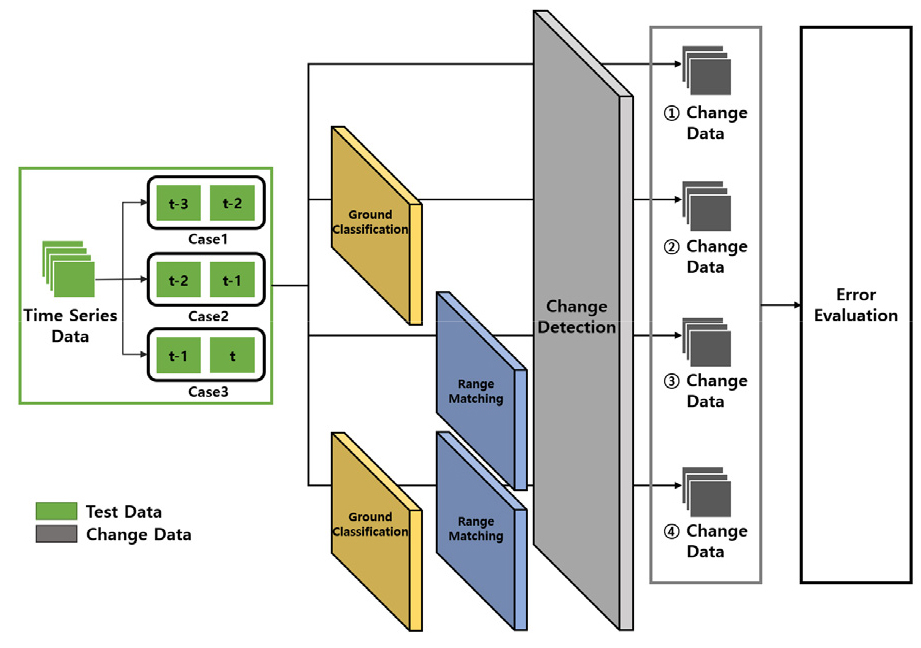
Figure 12와 Table 5에서는 변화탐지 알고리즘을 통해 도출한 결과값의 실제 형태 및 오차 포인트의 개수에 대해 나타내고 있다. 지형분류 및 분석범위 일치화 기술을 활용하지 않고 변화탐지를 수행한 결과값인 Figure 12(a)에서는, Case1과 Case3의 경우 Case2 보다 적은 오차를 나타내는 것을 육안으로 확인할 수 있다. 이러한 이유는 Week2와 Week3간의 공사진행 정도가 타 시점보다 많은 공사가 진행되었기 때문에 분석범위 불일치에 따른 오차가 비교적 크게 나타난 것으로 분석할 수 있다. 이에 Table 5에 따르면 Case1의 오차 포인트가 160,363이며 Case3의 오차 포인트가 75,652로 Case2의 669,378에 비해 다소 적은 오차 포인트를 나타내는 것을 수치상으로 확인할 수 있다.
Figure 12(b)에서는 지형분류 기술만을 적용한 데이터를 활용하여 변화탐지를 수행한 결과값에 대해 나타내고 있다. 이 역시, Figure 12(a)와 유사하게 Case2의 오차가 가장 높은 것으로 나타났다. 다만 Case1과 Case3의 오차 포인트가 지형분류 및 분석범위 일치화를 적용하지 않고 변화탐지를 했을 때보다 비슷하거나 높은 오차를 보이는 것으로 나타났다. 특히, 높은 오차를 보이는 이유는 지형분류의 성능이 약 70~80%로 완전한 지형분류를 수행하지 못한 데이터간의 변화탐지를 수행하면서, 기존에 발생하지 않았던 분석범위 불일치 오차가 추가로 발생하여 기술개발을 적용하지 않았을 때보다 더욱 많은 오차 포인트가 생성된 것으로 판단된다.
Figure 12(c)에서는 분석범위 일치화만을 적용한 데이터를 활용하여 변화탐지를 수행한 결과값에 대해 나타내고 있다. 이는 앞서 두 가지 경우와 비교해, 더욱 적은 오차 포인트가 포함된 것을 육안으로 확인할 수 있다. 이러한 이유는 분석범위 오차가 비지형 오차보다 더 큰 오차 포인트를 생성하기 때문에, 분석범위 오차를 해결한 세 번째 경우가 보다 적은 오차 포인트를 생성한 것으로 판단된다. 또한 Table 5에 따르면 오차 포인트가 Case1이 108,184개, Case2가 51,810개, Case3가 65,814개로 Case1이 가장 적은 오차 포인트를 포함하고 있는 것으로 나타났다. 이러한 이유는 Week1과 Week2의 디지털맵의 경우 타 시점의 디지털맵 보다 비지형이 포함된 비율이 높기 때문에 비지형에 의한 오차 포인트가 보다 많이 생성된 것으로 판단된다.
Figure 12(d)에서는 지형분류와 분석범위 일치화를 차례로 적용한 경우로, 본 연구에서 제시하고 있는 프레임워크의 최종결과에 해당하는 데이터라고 할 수 있다. 앞의 세 가지 경우와 비교하면, 비지형에 의한 오차와 분석범위에 의한 오차가 최소화 되어 있는 것을 시각적으로 확인할 수 있다. 또한, Table 5에 따르면 오차 포인트가 Case1이 25,621개, Case2가 10,425개, Case3는 3,566개로 다른 Case보다 현저히 적은 오차 포인트가 생성된 것을 수치상 확인이 가능하다.

6. 결론
본 연구에서는 토공현장 디지털맵 분석시 발생할 수 있는 비지형 오차, 분석범위 불일치 오차 문제를 해결하기 위한 기술개발을 수행하였다. 나아가 개발 기술을 통해 새로운 토공현장 디지털맵 시계열 분석 프레임워크를 제시함으로써 시계열 디지털맵 분석성능을 향상시키고자 하였다.
지형분류 기술은 디지털맵 분석시 발생하는 비지형에 의한 오차를 해결하는 기술로, 지형과 비지형을 분류하기 위해 두 단계로 지형학적 필터링 및 클러스터링 알고리즘을 활용하여 개발된 기술이다. 본 연구에서는 세 가지 지형학적 필터링 알고리즘의 성능검증을 통해 최적의 알고리즘으로 SMRF를 선정하였으며, SMRF는 약 50~70%의 지형분류성능을 나타냈다. 나아가 지형학적 필터링을 통해 분류가 완료된 지형 데이터의 특성을 반영하여 최적의 클러스터링 알고리즘으로 DBSCAN을 선정하여 다시 한번 지형분류를 수행하여, 최종적으로 약 70~80%의 지형분류 성능을 나타내 비지형에 의한 오차에 대해 상당한 수준의 개선이 이루어진 것으로 판단된다.
분석범위 일치화 기술은 시계열 디지털맵 분석시 발생할 수 있는 분석범위 불일치에 의한 오차를 해결하는 기술이다. 분석범위 일치화 기술은 C2P 알고리즘을 활용 및 변형하여 개발된 기술로, 본 연구에서는 분석범위 일치화의 성능검증과 더불어 본 연구에서 제안하고 있는 디지털맵 분석성능 향상 프레임워크 적용 전/후의 성능평가를 위해 4가지 경우의 수로 성능검증을 수행하였다. 성능검증 결과, 프레임워크 적용 전 평균 301,797개의 오차 포인트가 생성되는 것으로 분석되었지만 프레임워크 적용 후 13,204개로 분석되어 기존 대비 약 95%의 오차 포인트가 삭제되어 성능향상을 보인 것으로 나타났다.
결론적으로 본 연구에서는 실제 토공현장 포인트 클라우드 데이터를 활용해 디지털맵 분석성능 향상을 위 기술개발을 수행함으로써 토공현장 디지털맵 분석 데이터의 품질향상에 기여할 것으로 보인다. 나아가 대부분의 디지털맵 분석 소프트웨어는 인력의 개입을 통한 분석이 불가피하지만, 본 연구의 프레임워크의 경우 대부분의 알고리즘이 인력의 개입 없이 자동으로 분석을 수행할 수 있어 건설자동화에 기여할 것으로 기대된다.
