

1. 서 론
1.1 연구의 배경 및 목적
1.2 연구의 범위 및 방법
2. 문헌조사
3. 구성 가능한 점군 처리 파이프라인 디자인
3.1 아키텍처 디자인
3.2 핵심 처리 단계 및 알고리즘 정의
4. 구현 및 실험
4.1 시스템 구현 환경
4.2 실험 환경 및 데이터
4.3 실험 결과
5. 토 론
6. 결 론
1. 서 론
1.1 연구의 배경 및 목적
디지털 트윈(Digital Twin) 기술이 건설, 도시 계획, 도로 인프라, 시설물 유지관리 등 다양한 산업 분야의 핵심 기술로 부상하면서 현실 세계를 정밀하게 표현하는 3차원 디지털 모델의 수요가 급증하고 있다(Kang and Mo, 2024). Scan-to-BIM은 라이다(LiDAR)나 사진측량 기술로 취득한 점군(Point Cloud) 데이터에서 정보가 포함된 BIM(Building Information Modeling) 객체로 변환하는 기술로, 기존 건축물이나 복잡한 현장을 효율적으로 디지털화하는 가장 현실적인 방법이다.
그러나 Scan-to-BIM 프로세스는 취득된 원시 점군 데이터의 방대한 용량과 복잡성으로 인해 여러 기술적 한계를 내포한다. 수억 개에 달하는 점들의 집합인 점군 데이터에서 도시 및 건물 모델링의 기본 단위가 되는 지형, 건물, 수목, 도로 시설물 등 개별 객체를 분할(Segmentation)하고 식별(Classification)하는 과정은 전체 작업 효율을 결정짓는 핵심 단계이다. 현재 많은 경우, 이 분할 과정은 상용 소프트웨어에 의존하더라도 작업자의 수동 편집과 보정에 크게 의존하고 있어 상당한 시간과 비용이 소요된다(Yin et al., 2021).
이러한 수작업 의존도를 낮추고 분할 프로세스를 자동화하기 위해 다양한 알고리즘 기반 연구가 수행되어 왔다. 하지만 현장의 스캔 환경, 객체의 형태와 밀도, 스캔 장비의 특성에 따라 최적의 알고리즘과 파라미터가 달라지기 때문에 단일 알고리즘으로는 모든 상황에 효과적으로 대응하기 어렵다. 예를 들어, 항공스캔된 도시의 점군에는 지형과 더불어 수목들도 포함되어 있기 때문에, 이들에 가려진 건축물만 추출하는 것은 쉬운 일은 아니다. 또한, 도심지의 평탄한 지형 필터링에 적합한 파라미터는 식생이 우거진 산악 지형에서는 지면을 식생으로 오인하는 결과를 낳을 수 있다. 이런 모든 목적에 맞는 만능 데이터처리 프로그램을 개발한다는 것은 쉽지 않다.
이러한 문제를 고려해, 본 연구는 고정된 워크플로우가 아닌, 레고블럭처럼 사용자가 데이터의 특성과 작업 목적에 맞게 처리 단계를 조합하고 각 단계의 세부 파라미터를 손쉽게 조정할 수 있는 '구성 가능한(Configurable) 점군 처리 파이프라인'을 제안한다. 파이프라인의 유연성과 재사용성을 통해 Scan-to-BIM의 전처리 과정, 특히, 3차원 모델과 통계 계산까지를 효율화하는 Scan to Model Pipeline (SMP) 방법을 설계, 제안 및 성능을 분석하는 것이 본 연구의 주된 목적이다.
이를 위해, 인프라 관리 시 기본이 되는 지형, 건물, 수목 객체 분할을 중심으로 3차원 점군 데이터 처리를 위한 파라메터 구성 가능한 파이프라인 구조를 설계, 개발한다. 설계된 파이프라인 아키텍처를 사용해, 어떻게 점군 데이터 처리의 반복 작업을 줄이고 다양한 시나리오에 대한 대응력을 높이는지 확인한다. 또한, SMP 변환 효율화에 기여할 수 있는 실질적인 가능성을 논의하고자 한다.
1.2 연구의 범위 및 방법
본 연구의 공간적 범위는 지형, 건물, 수목이 혼재된 실외 환경을 대상으로 한다. 점군으로부터 모델처리까지 응용 범위는 지형, 건물, 그리고 비건물 객체의 대표 격인 수목으로 한정한다. 연구 방법은 다음과 같다.
첫째, Scan-to-BIM과 점군 객체 분할에 관한 기존 문헌을 고찰하여 관련 기술의 현황과 한계를 파악한다.
둘째, 프로세스 각 단계별 가변성을 지원하는 설정가능한 파이프라인을 디자인하고, 전체 아키텍처, 단계별 처리 알고리즘, 그리고 파라미터 구성 방식을 정의한다. 특히, 지형 분리, 비지형 객체 군집화, 건물 및 수목 분류에 사용된 핵심 알고리즘을 식별하고 그 역할을 분석한다. 셋째, 분석된 내용을 바탕으로 구성 가능한 파이프라인 프로토타입을 개발하고, 테스트한다.
마지막으로, 분석 결과를 종합하여 제안된 파이프라인 방식의 성능과 기술적 한계를 논하고 향후 연구 방향을 제시한다.
Figure 1는 본 연구 방법을 정의한 흐름도이다.
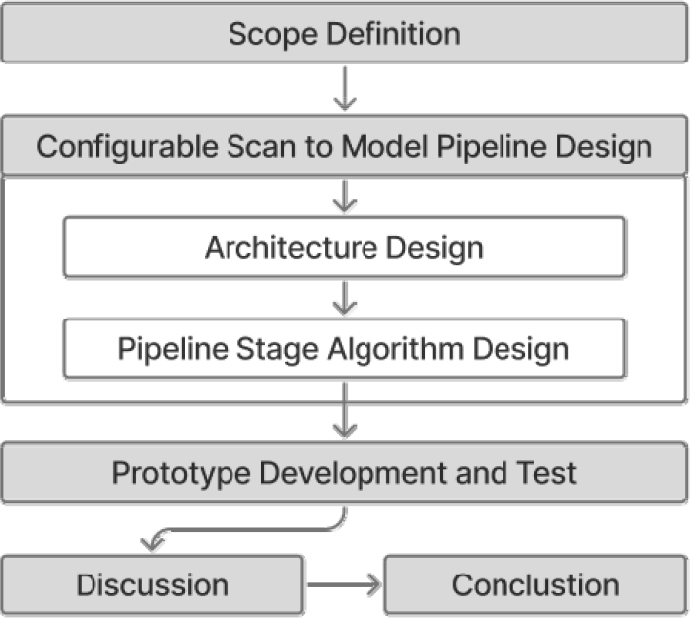
2. 문헌조사
Scan-to-BIM은 다음과 같은 프로세스로 진행된다(Mirzaei et al., 2022).
첫번째, 데이터 취득(Data Acquisition).
두 번째, 데이터 처리 및 정합(Registration).
세 번째, 분할(Segmentation) 및 모델링(Modeling).
이 중 객체 분할은 방대한 비정형 데이터인 점군을 의미 있는 단위로 나누는 과정으로, 후속 모델링 작업의 정확성과 효율성에 결정적인 영향을 미친다.
점군 데이터는 XYZ 좌표와 함께 강도(Intensity), RGB 색상 등의 정보를 포함하는 점들의 집합이다. 그러나 점들 간의 위상 관계(Topological relationship)나 의미 정보가 부재하여, 기계가 이를 직접 이해하고 구조화하기는 매우 어렵다. 따라서 점군을 지형, 건물 벽, 창문, 기둥 등의 객체로 분할하는 기술이 필수적이다.
점군 객체 분할 연구는 크게 세 가지 범주로 나눌 수 있다.
첫째, 형상 기반(Region-based) 분할이다. 이는 점들의 기하학적 특징(법선 벡터, 곡률 등)의 유사성을 기반으로 영역을 성장시켜 나가는 방식이다. RANSAC (Random Sample Consensus)은 평면, 원통 등 특정 기하 모델에 부합하는 점들의 집합(Inliers)을 반복적으로 찾아내는 대표적인 알고리즘으로, 건물 벽이나 바닥, 기둥과 같은 정형적 요소를 추출하는 데 널리 사용된다(Schnabel et al., 2007).
둘째, 군집화 기반(Clustering-based) 분할이다. 이는 점들 간의 거리나 밀도를 기반으로 그룹을 형성하는 방식이다. DBSCAN (Density-Based Spatial Clustering of Applications with Noise)은 밀도가 높은 지역을 중심으로 군집을 확장하며, 복잡한 형태의 객체나 식생을 분리하는 데 효과적이다(Ester et al., 1996).
셋째, 딥러닝 기반(Deep Learning-based) 분할이다. PointNet, PointNet++과 같은 선구적인 모델을 시작으로, 점군 데이터 자체를 학습하여 각 점에 대한 의미론적 레이블(Semantic Label)을 부여하는 연구가 활발히 진행 중이다. 높은 정확도를 보이지만, 방대한 양의 레이블링된 학습 데이터가 필요하고, 수백만 개 이상의 대용량 점군 데이터 처리에 한계가 있으며, 특정 도메인에 과적합될 수 있다는 단점이 있다(Qi et al., 2017a).
앞서 언급한 알고리즘들은 각기 다른 장단점을 가지며, 대상 데이터의 특성에 따라 성능이 크게 좌우된다. 예를 들어, CSF (Cloth Simulation Filter) 알고리즘은 복잡한 지형 필터링에 강점을 보이지만, 파라미터 설정에 민감하다(Zhang et al., 2016). RANSAC은 평면 검출에 강력하지만, 비정형 객체에는 적용하기 어렵다.
점군 처리를 위한 도구로 PCL (Point Cloud Library)과 PDAL (Point Data Abstraction Library)이 개발되었다. PCL은 C++기반 알고리즘 라이브러리이나, 복잡한 파이프라인 구성 시 C++ 코딩 및 컴파일이 필수적이다. 이런 한계를 보완하는 PDAL은 JSON 기반의 선언형 파이프라인을 지원하는 프레임워크이다. 이는 filters.smrf와 같은 저수준(low-level) 알고리즘 모듈의 유연한 조합을 가능하게 한다. 그러나 PDAL은 범용 프레임워크로서, Scan to BIM과 같이 여러 알고리즘이 순차적으로 결합되어야 하는 고수준의 워크플로우를 구현하기 위해서는, 사용자가 여전히 개별 알고리즘의 파라미터와 조합 순서에 대한 깊은 이해를 가져야 한다.
PDAL은 다단계 처리 과정에서 발생하는 다수의 중간 산출물을 체계적으로 명명(Naming)하거나 프로젝트 단위로 관리하는 기능이 부족하다. 또한, 객체 기반 통계 리포트 생성이나 딥러닝 모델 적용과 같은 고급 분석 기능이 내장되어 있지 않아, python 모듈을 통한 복잡한 개발이 요구된다(Table 1).
이러한, 기존 범용 프레임워크는 유연성이 높은 반면, 특정 도메인에 반복적으로 요구되는 고수준의 워크플로우를 자동화하고 관리하는 데에는 한계가 있다.
따라서 본 연구는 이러한 문제를 개선하기 위해, 구성 가능한 고수준 파이프라인 구조를 연구한다. 이는 새로운 알고리즘을 교체 가능한 모듈로써 쉽게 통합할 수 있게 하고, 표준화된 처리 과정을 통해 비전문가도 점군 작업을 재현성 있게 처리 가능하다.
본 연구의 범위는 개별 분할 알고리즘의 성능 개선이 아닌, 점군 처리 파이프라인의 구성가능성과 재사용성을 지원하는 구조 연구에 초점을 맞춘다. 제안하는 SMP 구조는 항공스캔 점군 처리에 필수적인 지형, 건물, 수목 객체 분할을 중심으로 모델처리 및 데이터 통계 단계까지 재활용성과 정확도 확인 후 결과를 토론한다.
단, 본 연구 목적과 범위는 점군 세그먼테이션 모델 성능을 개선하는 것이 아닌, 점군 처리 파이프라인 재활용과 구성가능성을 지원하는 구조 설계 연구에 초점이 있음을 밝힌다.
Table 1.
PCD data processing library comparison
3. 구성 가능한 점군 처리 파이프라인 디자인
본 장에서는 파이프라인 구조와 핵심 로직을 분석하여, 구성 가능한 파이프라인이 어떻게 설계되고 작동하는지를 정의한다. 분석은 SMP 전체 아키텍처, 핵심 처리 단계 별 알고리즘, 그리고 유스케이스 가변성을 지원하는 단계별 파라메터를 도출한다.
3.1 아키텍처 디자인
분석 대상 파이프라인은 점군 표준 파일(.las, .laz, .pcd 등)를 입력받아 지형, 건물, 수목으로 세그먼테이션하는 것을 목표로 한다. 이를 통해, 각 개별 객체를 모델화할 수 있다.
이런 목표를 달성하기 위해, 파이프라인은 일련의 모듈화된 처리 단계를 순차적으로 거치도록 설계한다. 각 모듈은 특정 유형의 객체를 분할하거나 데이터를 정제하는 역할을 수행하며, 사용자는 이 모듈들을 자유롭게 조합하고 각 모듈에 대한 파라미터를 조정하여 데이터의 특성과 작업 목적에 최적화된 워크플로우를 구성할 수 있다.
예를 들어, 초기 단계에서는 지형 필터링을 통해 지면과 비지면 객체를 분리하는 것이 가능하다. 이어서 군집화 알고리즘을 적용하여 비지면 객체들을 개별적인 군집으로 나누는 과정이 진행된다. 마지막으로, 각 군집의 특성을 분석하여 건물 또는 수목으로 분류하는 과정을 거치게 된다.
이러한 가변성을 가지는 구성 가능한 아키텍처는 특정 데이터 특징과 유스케이스로 고정된 알고리즘 한계를 보완, 다양한 현장 조건에 유연하게 대응함으로써 Scan-to-BIM 전처리 과정 효율성을 향상시킬 수 있다.
전체 아키텍처는 Figure 2와 같이 순차적인 모듈의 조합으로 구성된다.
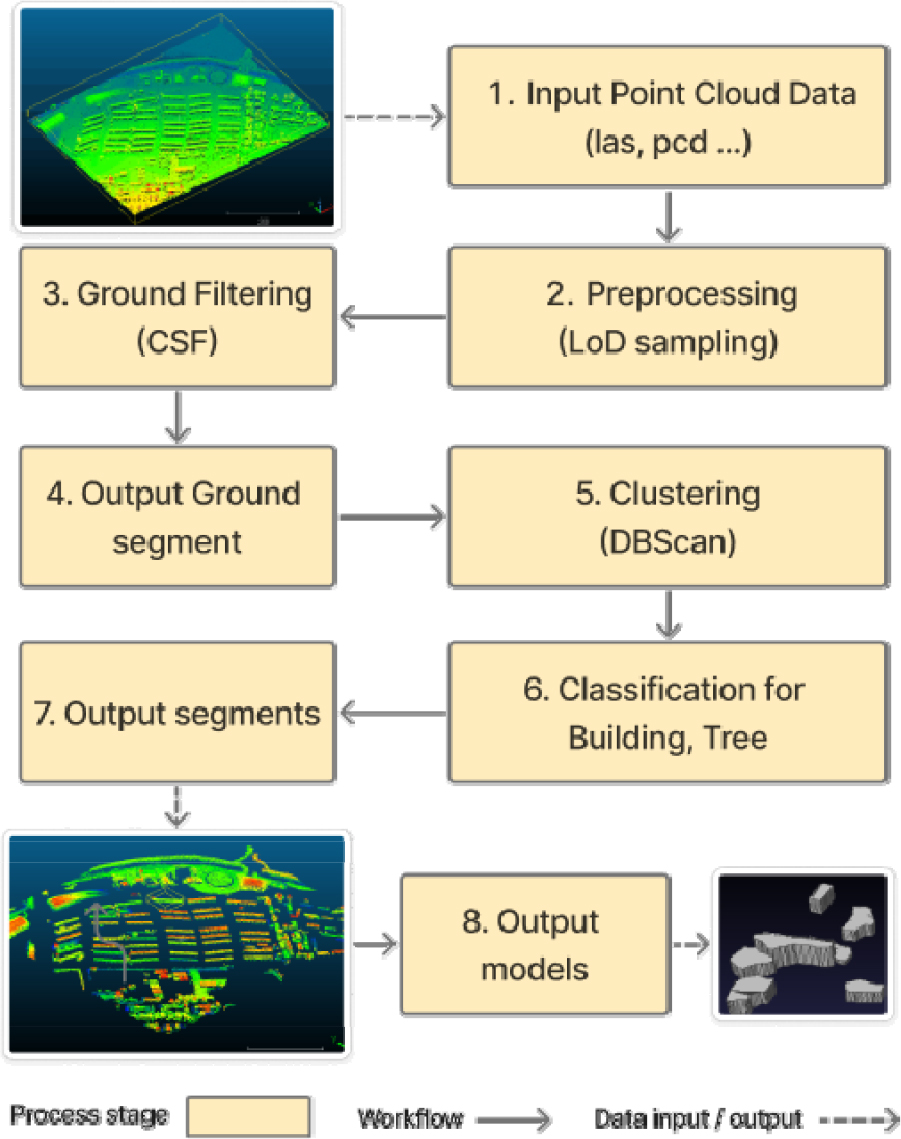
파이프라인의 각 단계는 독립적인 모듈로 기능하며, 이전 단계의 출력이 입력으로 받아 처리하고 결과를 다음 단계로 전달한다. 이 모든 과정은 하나의 설정 가능한 마스터 스크립트(Configurable Master Script)에 의해 제어되며, 각 모듈의 활성화 여부와 세부 동작을 결정하게 할 수 있다.
Table 2은 SMP의 고수준 함수 설계를 위해 각 단계의 입출력 형식, 기능 및 역할을 조사한 것이다. 각 단계 출력시 생성된 파일들은 분류된 객체명이 포함된 이름으로 포맷팅된다. 이는 다음 단계에서 특정 세그먼트된 점군만 필터링 후 처리하거나 특정 모델이 생성된 과정을 추적할 수 있게 한다.
Table 2 각 단계별 핵심 알고리즘은 다음과 같다.
Table 2.
Process stage of scan to model
3.2 핵심 처리 단계 및 알고리즘 정의
3.2.1 전처리 (Preprocessing)
전처리 단계는 요구사항 관점에서 원시 점군의 밀도를 균일하게 만들고 계산 부하를 줄여 후속 처리의 효율성을 높인다.
․알고리즘: 복셀그리드 다운샘플링(Voxel Grid Downsampling)을 사용한다. 이는 3차원 공간을 정육면체 복셀(Voxel)로 분할하고, 각 복셀 내의 모든 점들을 해당 복셀의 중심점(Centroid) 하나로 대체한다.
․파라메터 설정: 파이프라인 단계의 설정부에 복셀 크기 파라미터를 정의한다. 이를 통해, 복셀의 크기를 조절할 수 있다. 복셀 크기를 크게 설정하면 데이터가 더 많이 축소되어 처리 속도는 빨라지지만 세부 형상 정보가 손실될 수 있다. 반대로 작게 설정하면 원본에 가까운 정밀도를 유지하지만 계산 시간이 늘어난다.
3.2.2 지형 필터링 (Ground Filtering)
이 단계에서는 전체 점군에서 지형과 비지형 객체(건물, 수목 등)를 분리한다.
․알고리즘: CSF 알고리즘을 사용해 지형을 분리한다. 이 알고리즘은 점군 데이터를 뒤집고 그 위에 가상의 천(Cloth)을 떨어뜨리는 물리 시뮬레이션을 기반으로 한다. 천은 중력에 의해 아래로 떨어지다가 지형 점들에 의해 지지되고, 최종적으로 천의 형태를 구성하는 점들이 지형으로 분류된다.
․파라메터 설정: 이 단계에서는 다음과 같은 다양한 변수를 제어한다.
-cloth_resolution: 천의 해상도. 값이 작을수록 더 촘촘한 천을 사용해 미세한 지형 변화를 감지한다.
-rigidness: 천의 강성. 1(완전 유연)부터 3(견고)까지 설정하며, 지형의 굴곡에 따라 조절한다.
-class_threshold: 천과 점 사이의 거리 임계값. 이 값보다 가까운 점들이 지형으로 분류된다.
3.2.3 비지형 객체 군집화(Clustering)
지형이 제거된 비지형 점군들을 개별 객체 단위로 그룹화한다. 이 단계는 세그먼테이션으로 알려져 있다.
․알고리즘: DBSCAN을 사용한다. DBSCAN은 특정 반경(eps) 내에 최소 개수(min_points) 이상의 점을 포함하는 핵심점을 찾아 연결, 군집 확장하는 밀도 기반 클러스터링 방법이다.
․파라메터 설정: 이 단계에서 다음 변수를 설정한다.
-eps: 두 점을 같은 군집으로 간주할 최대 거리. 객체 간 이격 거리나 점군 밀도에 따라 조절한다.
-min_points: 하나의 군집을 형성하기 위한 최소 점의 개수. 이 값은 노이즈나 작은 객체 필터링 가능하다.
3.2.4 세그먼테이션
지면이 제거된 비지면(non-ground) 점군을 의미론적으로 세그먼트하여 개별 객체들을 식별한다.
․알고리즘: 본 연구는 규칙 기반의 색상 범위 필터(Color Range Filter)와 딥러닝 기반의 SAM(Segment Anything Model)을 상호 보완적으로 활용한다. 일반적인 SAM이 점(point), 박스(box)와 같은 프롬프트를 사용하는 것과 달리, 본 연구의 자동화 파이프라인에서는 포인트 클라우드를 특정 시점(Viewpoint)에서 2D 래스터 이미지로 투영(Projection)하는 방식을 채택한다. 생성된 2D 이미지를 SAM 기반 모델의 입력으로 사용하여 프롬프트 없이 자동화된 객체 세그먼테이션을 수행한다. 색상 범위 필터는 SAM의 성능을 보완하는 수단이 아니라, 명확한 색상 정보를 가진 객체(예. 식생)를 사전에 효율적으로 분리하거나, SAM으로 분할된 군집을 추가로 정제 및 세분화하여 파이프라인의 효율성과 정확도를 높이는 데 활용된다.
․파라메터 설정: 이 단계에서 다음의 주요 변수를 설정한다.
-model: 사용될 SAM 사전 학습 모델 파일(.pth)의 경로를 지정한다.
-view: 3D 포인트 클라우드를 2D 이미지로 투영할 시점('top', 'side', 'front' 등)을 지정하며, 이는 세그먼테이션의 기준이 되는 파라미터이다.
3.2.5 모델 출력
세그먼테이션된 모델을 출력한다. 건물의 경우, 건물 바닥(footprint)를 추출하기 위해, 추출된 건물 점군을 X-Y평면에 투영(projection)하고, 폴리곤을 추출한다. 그리고, 해당 점군의 최대 높이를 이용해 LoD 1 수준 모델을 생성한다. 군집화된 각 객체가 건물, 수목인지를 분류한다.
․알고리즘: 세그먼테이션된 모델을 출력하는 과정에서, 특히 건물 바닥 추출을 위해 알파 셰이프(Alpha Shape) 알고리즘과 함께 다음과 같은 파라미터들을 설정하게 된다. 알파 셰이프 알고리즘은 주어진 점들의 집합으로부터 볼록 껍질(convex hull)을 생성하는 방법이다. 이는 점들의 분포에 따라, 비볼록(non-convex) 형태도 추출할 수 있어 건물의 복잡한 외곽선 추출에 활용된다.
․파라메터 설정: 이 단계에서는 다음 변수를 제어한다.
-alpha_shape_factor: 알파 셰이프를 생성할 때 사용되는 값이다. 이 값은 점군으로부터 다각형을 생성하는 데 영향을 미치며, 건물의 외곽선을 얼마나 상세하게 표현할지 조절한다. 값이 작을수록 더 상세한 형태를 추출할 수 있으며, 노이즈에 민감해질 수 있다. 반대로 값이 크면 더 부드럽거나 단순한 형태를 얻게 된다.
-simplify_tolerance: 추출된 폴리곤을 단순화할 때 사용되는 허용 오차이다. Douglas-Peucker 알고리즘과 같은 폴리곤 단순화 알고리즘에서 사용될 수 있으며, 이 값을 통해 폴리곤의 정점 개수를 줄여 데이터 복잡도를 낮추게 된다. 값이 클수록 폴리곤이 더 많이 단순화되어 데이터 크기가 줄어들지만, 정밀도가 떨어질 수 있다.
4. 구현 및 실험
4.1 시스템 구현 환경
본 장에서는 앞서 3장에서 분석한 구성 가능한 파이프라인의 재활용성과 자동화 성능을 검증하고자 한다. 이를 위해, 가상의 실험 시나리오들을 설정하고 파이프라인 설정을 JSON형식으로 표현해 수행한다.
4.2 실험 환경 및 데이터
본 가상 실험을 위해 설정된 환경과 데이터는 다음과 같다. 입력 데이터는 도심 외곽 지역에서 취득한 점군 데이터(.las)로, 완만한 경사를 가진 지형과 여러개의 중소형 건물, 그리고 다수의 수목이 혼재된 복합적인 환경을 가정하였다. 소프트웨어는 Python으로 개발되었으며, 하드웨어는 Intel i9 2.9GHz (16GB RAM), NVIDIA RTX 3080 환경에서 터미널 명령어를 통해 파이프라인이 실행된다. 평가 방법은 각 시나리오별 JSON 설정에 따른 분할 결과의 변화를 정성적으로 예측하고 기술하는 방식을 취한다. 최종 결과물은 지표면(ground)와, 비지표면(non- ground) 및 세그먼테이션된 점군 파일들이다.
4.2.1 시나리오 A: 라이다 점군의 지표면과 건물군 분할
시나리오 A는 색상값 없는 항공라이다로 스캔된 점군(Figure 3)에 대한 지표면과 비지표면에 대한 클러스터링이다. 이 점군은 477,824개 포인트로 구성되어 있고, 크기는 13,067kb이다. 이 결과로 지표면에서 분리된 점군들은 DBScan을 통해 개별적으로 그룹화될 수 있다. 이 프로세는 두 단계로 구분된다.
Step 1는 획득된 3차원 점군 데이터로부터 지면을 효과적으로 분리하고, 건물이나 수목과 같은 비지면 객체 점군을 추출한다.
이를 위해 CSF 알고리즘을 적용하였으며, 천의 해상도를 1.0으로, 강성을 3으로, 시뮬레이션 시간 간격을 0.65로, 지면 분류 임계값을 0.5로, 그리고 반복 횟수를 500으로 설정하였다. CSF를 통해 지면이 제거된 점군은 이후 단계의 입력으로 활용되며, 출력물은 세그먼트와 해상도 정보를 포함하는 형태로 생성된다.
Step 2는 클러스터링을 수행한다. 이를 위해, DBSCAN의 탐색 반경(eps)과 최소 포인트 수(min_points)를 각각 3.0과 10으로 지정한다.

파이프라인 실행 결과 51초만에 121개 세그먼트가 추출되었다. Figure 4에서 비지면 점군에서 추출된 건물 및 수목이 그룹핑된 것을 확인할 수 있다. 또한, 그룹화된 점군에서 바닥고(Bottom Height), 최상고(Top Height), 면적(Area)이 자동 추출되었다(Table 3).
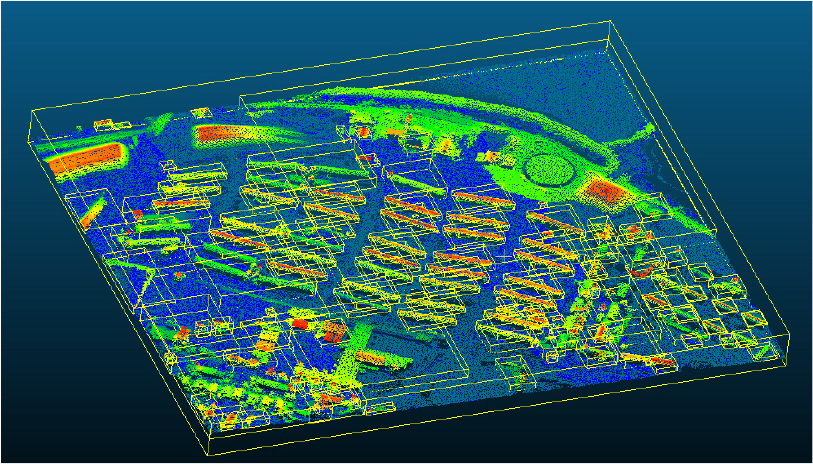
Table 3.
Clustering results in spreadsheet (Part of Sample A)
4.2.2 시나리오 B: 사진측량된 점군의 의미론적 세그먼테이션을 통한 건물 분할
시나리오 B는 도로, 지형, 수목, 건물이 복합적으로 스캔되었다(Figure 5). 포인트수는 6,023,205개, 크기는 199,991Kb이다. 건물에 수목이 겹쳐 있어 객체 분류에 난이도가 있으나, 사진측량 점군이라 색상 특징 등을 세그먼테이션에 활용할 수 있다.
정의된 파이프라인은 크게 지면제거 및 비지면 객체 추출, 의미론적 세그먼테이션, 클러스터링 및 필터링, 그리고 최종 3차원 모델 생성 단계로 구성된다. 지면제거와 클러스터링은 앞의 Step 1, 2를 그대로 재활용할 수 있다.

나머지 Step 3는 지면이 제거된 비지면 점군에 대해 의미론적 세그먼테이션을 수행하여 개별 객체들을 식별한다. 이 단계에서는 주로 .*non_ground.* 필터를 통해 CSF 단계에서 비지면으로 분류된 점군만을 입력으로 사용하며, 각 점의 3차원 좌표와 색상 정보(xyzrgb)를 활용한다. 세그먼테이션을 위해 SAM 딥러닝 모델을 사용하고, 이 과정은 스캔 데이터를 도시 세그먼테이션으로 변환하는 것을 목표로 한다. 이 단계를 통해 비지면 점군은 건물, 수목 등 다양한 객체 단위로 의미론적으로 분리되며, 세그먼트된 결과물을 식별하는 출력 태그가 부여된다.
Step 4는 색상 기반 객체 필터링 및 군집화를 수행한다. 의미론적 세그먼테이션 결과에 대해 추가적으로 색상 기반 필터링 및 군집화를 수행하여 특정 객체 유형을 선별하고 개별 객체를 명확히 구분한다. 먼저 색상 필터링 단계에서는 세그먼트된 객체 중 특정 색상 범위를 가지는 객체를 분류한다. 예를 들어, "house"는 RGB 값이 [100, 110, 120]에서 [160, 170, 170] 사이인 점군으로, "tree"는 [40, 50, 30]에서 [180, 180, 80] 사이인 점군으로 필터링된다. 이 외의 모든 점군은 "other"로 분류된다(Figure 6).
다만, 몇몇 부분은 의미론적 세그먼테이션이 실패하여 건물과 유사한 색상과 형태를 가지고 겹쳐진 수목들이 건물로 추출되는 문제도 확인할 수 있었다.

이어서 Step 5는 색상 필터링을 통해 건물(house)로 분류된 점군에 대해 개별 건물 객체 단위로 군집화를 수행한다. 이 단계에서는 DBSCAN 알고리즘이 활용된다. 이전 단계 출력에서 파일명이 “.*house.*”인 정규식 검색을 통해 건물로 출력된 점군 파일만을 군집화 입력으로 사용한다. DBSCAN의 반경(eps)은 3.0으로, 군집을 형성하기 위한 최소 점의 개수는 10으로, 제거할 노이즈 점의 최대 개수는 500으로 설정한다. 이를 통해, 개별 건물의 점군이 명확하게 분리되도록 한다.
Step 6은 세그먼트되고 분류된 점군으로부터 3차원 모델을 생성한다. 먼저 군집화된 각 객체(특히 건물)의 바닥면 폴리곤을 추출하는 단계에서는 Alpha Shape 알고리즘이 사용된다. Alpha Shape 계수는 0.2로 설정하여 객체 외곽선 추출의 상세도를 조절하며, 추출된 폴리곤의 정점 개수를 줄여 데이터 복잡도를 낮추기 위한 단순화 허용 오차는 0.1로 설정한다.
이 단계를 통해 각 객체의 2D 바닥면 폴리곤이 생성된다. 추출된 바닥면 폴리곤과 지형 분리 단계에서 분류된 지면 정보를 활용하여 3차원 LoD 모델을 생성한다. 특히 건물의 경우, 바닥면 폴리곤을 X-Y 평면에 투영하고 해당 점군의 최대 높이를 이용하여 LoD 1 수준 단순 3차원 건물 모델을 생성할 수 있다.
이 점군 처리 파이프라인의 수행 결과 4분 19초만에 37개 세그먼트가 추출되었다(Figure 7, Table 4).
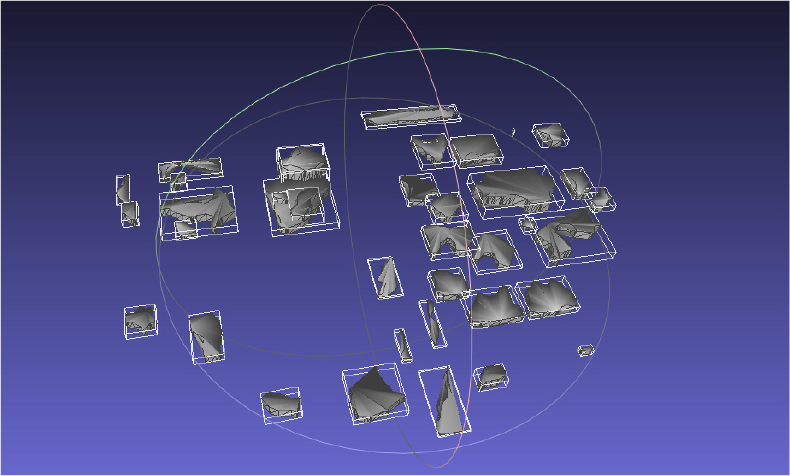
Table 4.
Clustering results in spreadsheet (Part of Sample B)
4.2.3 시나리오 C: 딥러닝 모델 기반 점군의 의미론적 세그먼테이션을 통한 건물 분할
시나리오 C는 SMP에서 딥러닝 모델 기반 세그먼테이션 성능을 확인하기 위해, B의 데이터셋과 파이프라인 일부를 사용하는 대신 건물 필터링만 점군 학습된 모델을 통한 건물 분할 시나리오를 설계하였다.
이를 위해 해당 데이터셋을 수작업으로 건물과 다른 지형을 구분해 라벨링하고, 이를 학습 가능하게 설계한 점군 세그먼테이션 모델로 학습하였다.
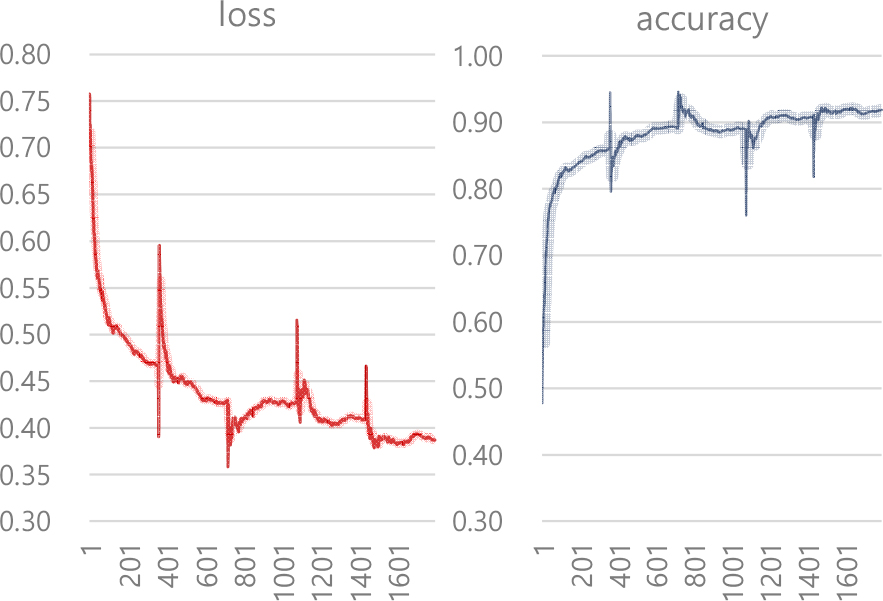
참고로, 기존 PointNet++, RandlaNet 학습 모델은 사용된 점군 특성이 다르므로, 그대로 사용할 수 없었고, PointNet 계열은 용량이 큰 점군의 경우에 직접 학습 처리가 어려웠다. 본 연구에서는 FPS (Farthest Point Sampling)(Qi et al., 2017b)와 정규화된 데이터 특징 학습 레이어를 U-Net으로 중첩해 점군 세그먼테이션 모델을 설계하였고, VRAM(8GB) 한계가 고려된 점군 세그먼테이션 경량 모델을 개발해 적용하였다. 점군은 블록(점군갯수=8196)으로 분할된 후 학습되었다 (배치크기=6). 학습과 검증 데이터셋은 8:2로 분할 된 후 1795단계로 훈련되었다. 학습 결과 모델의 검증 손실은 0.352, 정확도 0.936였다(Figure 8, 9). 이 시나리오에서는 CSF 알고리즘 대신 이 딥러닝 모델을 적용해 점군을 분류한 후 클러스터링한다.
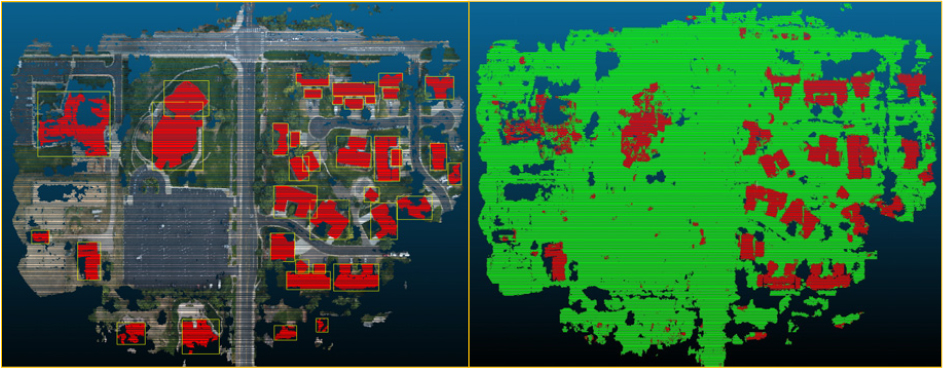
파이프라인 실행 결과 14분 45초만에 34개의 세그먼트가 추출되었다(Figure 10).

다음은 앞서 설명한 시나리오의 파이프라인 설정파일 일부를 보여준다.
[
{
"name": "csf",
"config": {
"cloth_resolution": 1.0,
"rigidness": 3,
"time_step": 0.65,
},
},
{
"name": "segment",
"input_filter": ".*non_ground.*",
"input_feature": {
"point": "xyzrgb"
},
"config": {
"type": "SAM",
"model": "SAM.pth",
"view": "top“
},
},
{
"name": "cluster",
"input_filter": ".*house.*",
"config": {
"eps": 3.0,
"min_samples": 10,
"remove_samples": 500,
},
},
{
"name": "footprint",
"config": {
"alpha_shape_factor": 0.2,
"simplify_tolerance": 0.1
},
},
]
4.3 실험 결과
본 절에서는 제안하는 SMP 효율성 확인을 위해, 재사용성(Ruse), 자동화 성능과 더불어, 점군 데이터 계산 결과도 함께 검토하기 위해 점군 분할 품질도 고려한다. 자동화 효율성을 평가하기 위한 시간 단축률(T)은 수작업으로 소요된 시간(T1) 대비 자동화 파이프라인으로 단축된 시간(T2)의 비율로 계산한다. 단순 개수 비교 방식의 정확도 지표는 분할의 질을 정확히 반영하지 못하는 한계가 있어, 이를 객체 탐지 및 분할 평가의 표준 지표인 정밀도(Precision), 재현율(Recall), 그리고 F1- Score로 대체하여 분석한다. 이 지표는 수동 검증을 통해 분류된 정상 탐지(TP), 오탐지(FP), 미탐지(FN) 값을 기반으로 계산된다. 각 지표의 수식은 다음과 같다.
-재사용성(R) = Ruse / Rmax
Ruse: 사용된 파이프라인 단계수
Rmax: 파이프라인 최대 단계수
-시간 단축률(T) = 1 - (T2 / T1)
T1: 수작업 소요 시간(초)
T2: 파이프라인 자동 실행 시간(초)
-F1-Score = 2 x (P x R) / (P + R)
-정밀도(P. Precision) = TP / (TP + FP)
-재현율(R. Recall) = TP / (TP + FN)
성능 비교를 위한 수작업 시간은 오픈소스 포인트 클라우드 편집 소프트웨어인 CloudCompare를 사용하여 측정하였다. 수작업은 초급 엔지니어(경력 1년 이하)가 수행하였으며, 점군 정리, 세그먼테이션 등을 수행한 시간을 모두 측정하였다. 파이프라인 처리 및 수작업에 대한 객관성 확보를 위해 연결된 점군들은 하나의 객체라 가정한다. 예를 들어, 뭉쳐진 점군 외벽, 지붕 등 주요 구조물은 하나의 객체로 취급해 작업한다.
수작업 시간 T1은 원본 데이터를 불러온 시점부터 모든 객체 분할 및 저장을 완료하는 순간까지의 순수 작업 시간을 측정한다. F1-Score 계산은 자동 처리된 세그먼트를 중급 엔지니어(3년 이상 경력)가 각각 확인 및 분류한 것을 기준으로 한다. Table 5는 각 시나리오에 대한 최종 성능 평가 결과를 보여준다.
Table 5.
Performance of scan to model pipeline
| Scenario | Ruse | Rmax | R | T1 | T2 | T | TP | FP | FN | P | R | F1 |
| A | 5 | 8 | 0.63 | 2,783 | 51 | 0.98 | 121 | 32 | 47 | 0.79 | 0.72 | 0.75 |
| B | 7 | 8 | 0.88 | 1,036 | 259 | 0.75 | 37 | 9 | 12 | 0.80 | 0.76 | 0.78 |
| C | 5 | 8 | 0.63 | 1,036 | 895 | 0.14 | 34 | 5 | 4 | 0.87 | 0.89 | 0.88 |
분석 결과, 제안하는 파이프라인은 시나리오 모두에서 재사용성(최소=0.63), 처리성능(최소=0.14), 세그먼테이션 품질(최소=0.79)에서 좋은 성능을 보였다. 시나리오 A는 수작업 대비 처리 시간을 98%까지 자동화한 효율성을 보여준다. 이는 자동화된 점군 처리 성능이므로 예상된 결과이다. 본 연구에서 예시 시나리오 처리를 위해 설계된 파이프라인 계산 결과를 품질 관점에서 검토해 보았다. 시나리오 A는 정밀도는 0.79을 기록했으나 재현율은 상대적으로 낮았다. 반면, 시나리오 B는 정밀도 0.80, 재현율 0.76로 개선되었으나 처리 시간은 75%로 다소 낮은 성능을 보인다. 시나리오 C의 경우 정밀도 0.87와 재현율 0.89로 가장 높은 가장 높은 F1-Score를 기록하였으나, 딥러닝 모델을 사용하는 등 알고리즘 계산 복잡도가 증가해 처리 시간은 0.14로 제일 낮았다.
결과를 보았을 때, 입력 점군의 특징 정보가 명확한 데이터셋과 이를 잘 인식할 수 있는 세그먼테이션 모델이 포함된 파이프라인이 오탐지와 미탐지를 효과적으로 제어할 수 있지만, 높은 모델 정확도 요구는 더 많은 점군 처리 시간이 필요하다는 것을 확인 할 수 있다. 이는 제안된 방법이 입력 데이터 특성, 처리 성능과 품질 간의 균형을 사용자 설정을 통해 처리 가능한 구조임을 보여준다.
5. 토 론
이 연구에서 제안한 파이프라인 구조는 다양한 유스케이스과 데이터 특성을 반영할 수 있도록 3차원 점군 처리에 대한 가변성을 지원한다. 이를 위해, 사용하기 편리한 JSON 구조로 파이프라인을 설계한다. 이는 다음과 같은 의미가 있다.
첫째, 알고리즘 추상화 및 사용자화 지원을 통한 접근성 향상 - 복잡한 점군 처리 알고리즘의 세부 구현을 알지 못하는 BIM 모델러나 현장 실무자도 JSON 설정 파일을 통해 사용자화 점군처리 파이프라인을 개발할 수 있다. 이는 프로세스 각 단계별 명확한 입출력 형식과 파라메터 정의를 통해 가능하다. 이를 통해, 알고리즘의 복잡성을 추상화할 수 있었다.
둘째, 작업 속도 및 효율성 개선 - 전통적인 방식에서는 데이터 특성이 바뀔 때마다 코드를 수정하고 디버깅하는 과정이 필요했다. 그러나 이 파이프라인은 이러한 과정을 설정값 변경으로 대체함으로써, 여러 데이터셋에 대한 연속적인 처리를 자동화하고 최적화에 소요되는 시간을 단축시킨다. 이는 특히 유사한 유형의 프로젝트를 반복적으로 수행해야 하는 실무 환경에서 강점으로 작용한다.
셋째, 확장성 및 유지보수성 개선 - 파이프라인이 모듈식 구조로 설계되었기 때문에, 향후 더 발전된 알고리즘이 개발되었을 때 이를 새로운 모듈로 추가하고 JSON 설정에 옵션을 더하는 방식으로 손쉽게 시스템을 확장할 수 있다. 각 모듈이 독립적으로 기능하므로 특정 부분의 버그 수정이나 성능 개선이 전체 시스템에 미치는 영향을 최소화할 수 있어 유지보수에도 유리하다.
분석된 파이프라인은 명확한 장점에도 불구하고 몇 가지 본질적인 한계를 가진다. 품질 수준에서 각 시나리오의 점군 세그먼테이션 정확도는 그리 높지 않다. 이 원인을 분석해 보면 다음과 같다.
첫째, 규칙 기반 분류 한계 - 건물과 수목을 분류하는 로직이 평면의 존재 여부, 군집의 크기 등 사전에 정의된 기하학적 규칙에 크게 의존한다. 이러한 접근 방식은 비정형적이거나 복잡한 형태의 현대 건축물, 예를 들어 곡면 외벽을 가진 건물이나 여러 동이 복잡하게 얽힌 구조물, 옥상 정원이 있는 건물 등을 정확히 분류하는 데 어려움을 겪을 수 있다. 또한, 거대한 수목이 건물 벽에 매우 가깝게 붙어 있는 경우, 이를 분리하지 못하고 하나의 객체로 오인할 가능성이 상존한다.
둘째, 최적 파라미터 도출 문제 - 파이프라인이 다양한 파라미터를 제공하는 것은 장점이지만, 역설적으로 사용자가 주어진 데이터에 가장 적합한 파라미터 조합을 찾는 것 자체가 또 다른 과제가 될 수 있다. 최적의 값을 찾기 위해서는 여전히 해당 알고리즘의 특성에 대한 어느 정도의 이해와 여러 번의 시행착오가 필요하다. 이는 향후 정답 데이터를 통한 파라메터 학습을 통해 해결할 수 있을 것이다.
셋째, 객체 다양성의 한계 - 현재 파이프라인은 지형, 건물, 수목이라는 세 가지 주요 객체에 초점을 맞추고 있다. 하지만 실제 현장에는 가로등, 벤치, 도로 표지판, 펜스 등 다양한 소규모 인공물이 존재한다. 현재의 분류 체계로는 이러한 객체들을 노이즈로 처리하거나 수목으로 오분류할 가능성이 높아, 완전한 수준의 Scan-to-BIM을 위해서는 딥러닝 모델 기반의 추가적인 객체 분류 기능의 확장이 필수적이다.
6. 결 론
본 연구는 가변성을 지원하는 설정 가능한 점군 처리 파이프라인을 제안하였다. 프로토타입을 개발하고 테스트한 결과는 다음과 같다.
첫째, 알고리즘 로직과 파라미터 설정을 분리하고, 이를 외부 설정 파일로 제어하는 방식은 파이프라인의 유연성과 재사용성을 극대화한다. 사용자는 소스 코드를 직접 수정하는 대신, 직관적인 JSON 파일의 파라미터를 조정하는 것만으로 다양한 스캔 환경과 객체 특성에 맞게 처리 로직을 신속하게 최적화할 수 있다.
둘째, 복셀 다운샘플링, CSF, DBSCAN, 딥러닝 모델과 같이 검증된 알고리즘들을 모듈화하여 순차적으로 적용하는 파이프라인 구조는 복잡한 점군 처리 문제를 고수준 추상화해 사용을 단순화하고 재현성을 높이는 효과적인 자동화 방식이다. 각 단계의 목적이 명확하여 결과 예측이 용이하고, 문제 발생 시 원인 파악이 수월하다.
셋째, 실험을 통해, 데이터 특성(경사가 있는 지형을 스캔한 라이다 점군 혹은 색상을 포함한 점군)에 차이가 있더라도 사용자의 파이프라인 단계 별 설정만을 통해 점군 계산의 성능제어가 가능함을 확인하였다.
다만, 규칙 기반 분류의 명확한 한계와 최적 파라미터 도출의 어려움은 여전히 해결해야 할 과제로 남아있다. 향후 연구에서는 딥러닝 모델 기반의 의미론적 분할과 AI에이전트 방식의 의사결정 기술을 활용하여 파라미터 자동 최적화 기능을 도입하고, 파이프라인을 더욱 지능화할 필요가 있다. 이를 통해, 분류 가능한 객체의 범위와 정확도를 개선할 계획이다. 본 연구 결과는 오픈소스로 공개되었으며, 앞서 논의된 부족한 부분을 피드백 받아 개선될 계획이다.
