

1. 서 론
1.1 연구배경
1.2 연구목적 및 범위
2. 이론적 고찰
2.1 BIM 자동화 및 의사결정 지원 연구 동향
2.2 LLM 적용수준의 유형 구분
3. 방법론
3.1 wise-BIM 아키텍처 설계
3.2 wise-BIM 아키텍처 작동방법
3.3 실험설계
4. 토의 및 시사점
4.1 실험결과의 분석
4.2 MVE 관찰 결과의 시사점
4.3 wise-BIM 런타임 구조
5. 결 론
1. 서 론
1.1 연구배경
BIM (Building Information Modeling, 혹은 건설정보모델)은 건설분야에서 디지털 전환(Digital Twin, DX)의 주재료이나(Adebiyi et al., 2024), 다학제적 협업과 복합적 규정으로 인해 모델링의 품질 편차와 재작업이 빈번하다. 특히 BIM을 활용한 규칙 기반의 자동화는 의사소통 조건에 대한 적응성 부족 등의 구조적 제약을 지닌다(Eastman et al., 2009).
최근 ChatGPT, Gemini 등 대규모 언어모델(Large Language Model, LLM)은 방대한 규칙과 패턴을 자연어 형식으로 내재화함으로써 전문 지식의 탐색, 분석, 적용에 소요되는 시간과 비용을 줄이는 데 기여하고 있다. LLM은 건설분야에서도 프로젝트의 목적과 목표에 맞추어 의사결정을 지원할 잠재력을 지니고 있다. 건설분야에서 IoT 센서, 레이저 스캐닝 등을 통해 획득한 데이터를 활용하여 규칙 기반의 자동화를 부분적으로 구현하고 있다. 그러나 이러한 방법만으로는 복잡한 설계의도와 현장변수에 즉각대응하는 것이 어려운 실정이다(Santiago & Cuperschmid, 2023). 따라서 LLM의 장점을 활용하기 위해서 건설분야의 요구와 맥락에 적합한 기술개발이 필요하다.
본 논문은 LLM을 활용하여 모델링 가이드라인, 중간 산출물의 수준 점검 등을 지원함으로써 BIM 모델링 개선방향의 효율성을 강화하고자 한다.
1.2 연구목적 및 범위
본 연구의 목적은 LLM 내재형 BIM 모델링 평가 및 피드백 프레임워크(이하 wise-BIM)를 제안하고 최소 실험가능 실험 수준에서 그 실효성을 실증하는 것이다. 이를 위해 (1) wise-BIM의 아키텍처를 설계하고 (2) 프레임워크 설계(framework design)와 실험적 검증(experimental validation)방법을 명확히하고 (3) 설계된 프레임워크를 적용할 대상자를 선정하여 실험을 수행한다.
wise-BIM은 개념적 아키텍처는 세가지 요소로 구성된다(Table 1).
Table 1.
Components of the wise-BIM framework
“(A) 의사결정 노드 구조화 → (B) 목적 활용 중점 정의 → (C) LLM 피드백 루프”의 3단계를 거쳐 동적 피드백을 제공한다. A단계에서는 모델링 단계별 의사결정 지점을 체계적으로 구조화하여 품질 편차를 최소화할 수 있는 기준점들을 정의한다. B단계에서는 모델링 목적, 활용 방안, 기술적 중점 사항을 규명함으로써 재작업 및 오류 발생 요인을 사전에 제거할 수 있는 생산성 핵심 지표를 설정한다. 마지막으로 C단계에서는 ChatGPT모델(4o, 4.5, o3, o4-mini)를 활용한 오류-조치-재검토의 반복 피드백 루프를 구현한다. C단계는 wise-BIM의 핵심으로, LLM 지원의 가능성, 한계 및 개선 효과를 실증적으로 평가하는 데 중점을 둔다.
Table 1은 wise-BIM의 세 노드에 투입되는 자원을 유형 수준으로 제시한다. A는 규정·지침, 요구·납품 요건의 체계, BEP 템플릿과 같이 목표·범위·성과물 결정을 지지하는 규범적 자원을, B는 프로젝트 맞춤 가이드, 오류–조치 리포지토리, LOD/OI, 우선순위 규칙 등 목적 파라미터를 정형화하는 자원을, C는 답변 패턴, 프롬프트–응답 로그, 근거 인용 템플릿 등 대화형 추론을 표준화하는 자원을 필요로 한다. 개별 문서와 템플릿의 명세·버전 정보는 실험설계에 적합하도록 Table 3에서 제시된다. Table 1은 프레임워크 차원의 변경 시에만 제한적으로 수정되고, Table 3은 프로젝트와 기관의 성향에 따라 수시 갱신된다고 볼 수 있다.
2. 이론적 고찰
2.1 BIM 자동화 및 의사결정 지원 연구 동향
BIM은 데이터기반의 의사결정을 가능하게 하는 핵심도구로 자리매김해 왔다. 초기 연구들은 주로 규칙기반(Rule-based) 스크립트를 활용하여 형상을 자동 생성하거나 품질 검증결과를 시각화하여 건설 프로젝트의 생산성을 향상시키는 데 초점을 맞추었다. 이후 건설분야는 BIM 데이터를 활용한 자동화 기술과 의사결정 지원체계 구축에 주목해 왔다.
Koo & Shin (2018)은 One-class SVM 기반 이상치탐지(novelty detection) 기법을 적용해 BIM 객체와 IFC 클래스 간 매핑 오류를 자동 식별할 수 있는 프레임워크를 제안하여 자동화 기반을 마련하였다.
Koo et al. (2017)은 머신러닝 기반 접근이 통계 기반 이상치 탐지보다 BIM-IFC 매핑에 더 효과적임을 실증함으로써 프로젝트 전반에 적용 가능한 유연한 검토체계를 제시하였다.
Kim et al. (2013)은 IFC 데이터에서 형상·속성·수량 정보를 자동 추출하고 이를 작업 단위, 소요시간, 순서 규칙 등과 연계하여 공정 일정을 자동 생성함으로써 수작업 일정계획의 한계를 극복하고 객관적·반복적인 의사결정 체계를 구현하였다.
이 연구들은 BIM 정보의 구조화·해석을 통해 작업 자동화와 설계 검토 지원의 범위를 확장한 것이다. 이는 본 연구가 지향하는 BIM 모델링 평가체계의 기술적 토대를 제공한다. 그러나 규칙기반 접근방법은 다음과 같은 구조적 한계를 지닌다.
규칙 유지·보수 부담 (문제점 ①)
설계 기준·발주 지침·조달 규정이 수시 개정됨에 따라 스크립트 규칙을 사람이 갱신해야 하므로 지속적인 비용과 시간이 소요
프로젝트별 문맥 적응성 결여(문제점 ②)
동일한 규칙도 발주처, 공종, 시공 방법에 따라 해석이 달라지나 정적 스크립트는 이러한 문맥적 차이를 반영하지 못함
다중 기준 의사결정 한계(문제점 ③)
생산성·비용·안전·환경 등 복합 기준을 동시에 고려해야 하나 통상적인 자동화 개선 연구는 단순 Pass/Fail 결과로 도출됨
설명 가능 피드백 부족(문제점 ④)
스크립트는 개발자가 규정한 규칙에 의해 오류원인을 탐색하므로 추가 질의에 대한 답변을 위한 추론으로 이어지기 어려움
기존 연구는 모델링 설계의 효율성 개선과 같은 프로세스 측면의 전략적 조치로 연결되기 어렵다. 본 연구는 이 한계를 대화형 LLM-RAG의 확장성을 통해 보완하고자 한다.
기존 규칙 기반 BIM 자동화는 설계 규정의 잦은 개정, 프로젝트별 맥락 적응성 부족, 복합 기준 의사결정 한계, 설명 가능한 피드백 결여 등 구조적 제약을 지닌다. 본 연구는 LLM-RAG가 이러한 제약을 완화할 수 있음을 실험적으로 검증한다. 특히, 모델 파일 학습 없이 텍스트 기반 자료만으로도 목표 정교화와 오류 규명이 가능함을 입증하였다는 점에서 기존 연구와 차별화된다. 이는 BIM 자동화 연구에서 동적·대화형 의사결정 지원을 실무 수준으로 구현한 최초의 시도로 학문적·산업적 독창성을 지닌다.
대화형 대규모 언어 모델(LLM)은 위 한계들을 완화할 수 있는 잠재력을 지닌다. 최신 기준과 지침을 자연어 형태로 입력받아 즉시 규칙으로 재구성(Fuchs et al. (2024), 문제점 ①의 해결연구 사례)한다. 또한 프로젝트별 요구사항을 대화형으로 해석해 검토 사항을 조정할 수 있다(Liu & Chen (2025), Hellin et al. (2025), 문제점 ②의 해결연구 사례). 이 외에도 비용, 품질, 안전 등의 복합기준을 통합평가하는 것이 가능(Madireddy et al. (2025), 문제점 ③의 해결연구 사례)함을 입증한 사례와 오류 원인을 탐지하고 보완의 우선순위를 설정하여 자연어로 상세히 전달하는 것이 가능함을 입증한 사례가 있다(Hellin et al. (2025), Fuchs et al. (2024) 문제점 ④의 보완).
그러나 기존 LLM 기반 연구는 여전히 성공률 검증체계와 토목분야 실시간 모델링 전략을 지원하는 기능에서 한계를 보인다. 이에 본 연구는 LLM을 내재화한 wise-BIM 프레임워크를 제안하고, 전문가 기반 실험을 통해 그 효과성을 검증하였다. wise-BIM은 모델러가 단계별 질의응답을 통해 오류와 반복 작업을 선제적으로 줄이는 동적맥락 지향형 의사결정 지원체계로서, 규칙 기반 자동화의 구조적 제약을 근본적으로 보완하는 새로운 접근을 제시한다.
2.2 LLM 적용수준의 유형 구분
LLM 기반 BIM 응용사례는 Table 2와 같다.
① 단순 질의응답(Level 1)
② 문서 요약·생성(Level 2)
③ 규칙 기반 점검 보조(Level 3)
④ 창의적 정보생성·업무지원(Level 4)
Table 2.
Classification of LLM application levels and use cases
wise-BIM은 ③과 ④를 통합하여 “점검 결과를 즉시 전략으로 전환”하는 동적 맥락 지향형을 목표로 한다. 이러한 유형 구분에 따라 Table 2는 각 수준별 LLM 기술의 적용 예시와 사용 사례를 정리하였다.
Level 1(단순 질의응답)은 자연어 처리(NLP)와 분류 기반 알고리즘(SVM)을 BIM 소프트웨어(Navisworks)에 연계하여 BIM 속성 정보에 대한 사용자 응답하는 방식이다.
Level 2(문서 요약·생성)는 BIM 프로젝트의 다양한 문서, 리포트 기록 등을 요약하고 재구성하는 기술로 Oracle의 Construction Intelligence Cloud (CIC) Advisor 사례를 소개한다. Cloud 플랫폼에 들어있는 BIM 문서들을 검토하여 데이터를 시각화하고 위험 요소를 사용자에게 제공한다.
Level 3(규칙 기반 점검 보조)은 간섭에 대한 사진을 AI YOLO 알고리즘을 통해 검토 이후 간섭을 항목별로 분류하고 불필요한 간섭 내용을 제거함으로써 검토 효율을 높인다.
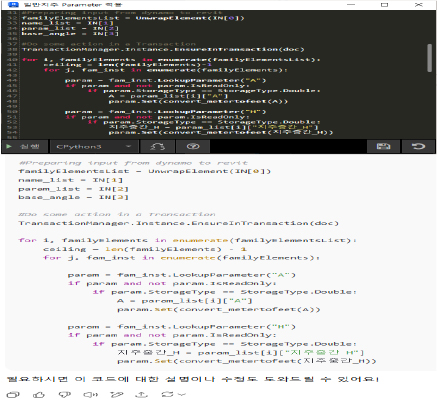
Level 4(창의적 정보생성·업무지원)는 사용자의 설계 의도를 해석하여 대안을 시각화하고, BIM 내 파라메트릭 모델 생성을 위한 코드를 자동으로 생성하는 방식이다. 이를 통해 설계 자동화와 다양한 대안 도출이 가능해진다.
3. 방법론
3.1 wise-BIM 아키텍처 설계
wise-BIM은 Layer–node–loop의 삼중 구조로 정의된다. 먼저 Layer는 시스템의 동작을 ‘자원(resource)–호출(invocation)–행위(action)’의 연쇄로 구분하는 상위 범주이며, 무엇을 참조하고(자원), 어떻게 불러와 맥락화하며(호출), 어떤 조치를 산출할 것인가(행위)를 명시한다. Node는 이러한 Layer 전반을 가로지르며 특정 목적을 수행하도록 묶은 기능 단위로, 본 연구의 연구목적 및 범위 부분에서 언급하였다.
wise-BIM은 A (decision-node structuring), B (purpose- driven element setting), C (RAG-prompt feedback loop)의 세 노드로 구성된다(Table 3). A는 전면설계 단계에서 필요한 규정·요구·BEP 계열 정보를 구조화해 의사결정 지점을 정렬하고, B는 범위–성과물–속성–우선순위를 파라미터로 정형화하며 오류–조치 패턴을 축적한다. C는 A·B에서 준비된 정적 자원을 RAG-prompt로 주입하여 대화형 추론을 수행하고, 설명가능한 응답을 통해 사용자의 재질문과 조치를 유도한다.
Table 3.
Evaluation of wise-BIM function
Table 3의 “참조 리소스” 열은 각 Node 기능을 구체적으로 뒷받침하는 자료군을 뜻한다. 예를 들어 Node A는 ‘규격·지침·표준’, ‘과업지시서’, ‘표준 BEP 템플릿’ 등의 정적 정보를 학습한다. Node B는 과업범위, 제출 성과물, 속성 사전, 오류 사례, 스크립트/노드 조작 패턴, 우선순위 규칙 등 목적 지향 리스트를 학습한다. Node C는 ‘FAQ+모범 답변’·‘프롬프트-응답 시나리오 로그’ 등 대화형 컨텍스트를 주요 리소스로 삼는다. C는 A, B자원으로 프롬프트(prompt)를 구성하고 프롬프트, LLM응답, 모델러실행, 피드백 성과평가 순으로 작동된다. 이와 같이 정보와 평가항목을 정하는 것은 각 Node의 정보 – 처리 방식 차별성을 명확히 하면서, 전체 시스템이 정적 지식과 동적 피드백을 병행활용할 수 있도록 하기 위함이다.
3.2 wise-BIM 아키텍처 작동방법
Table 3에 제시된 wise-BIM의 Node (A~C)의 작동방식은 다음과 같다(Figure 1). 디지털자원(resource)이 호출(invocation) 및 사용자 행위(action)의 다층 구조를 관통하며 상호 피드백 루프를 형성한다. Layer는 “어느 범주에서 동작하는가”(자원 → 호출 → 행위)를, Node는 “세부 기능 묶음”을 지칭한다. wise- BIM은 세 Node가 각 Layer를 관통하며 파이프라인을 형성한다. Figure 1은 이 세 Node가 A, B, C 순서대로 작동함을 보여준다. A와 B가 제공하는 자원이 C의 RAG-prompt loop로 유입되며, C에서 발생한 실시간 KPI가 다시 A·B의 규칙 파라미터를 업데이트하여 다음 주기 효율을 높인다.
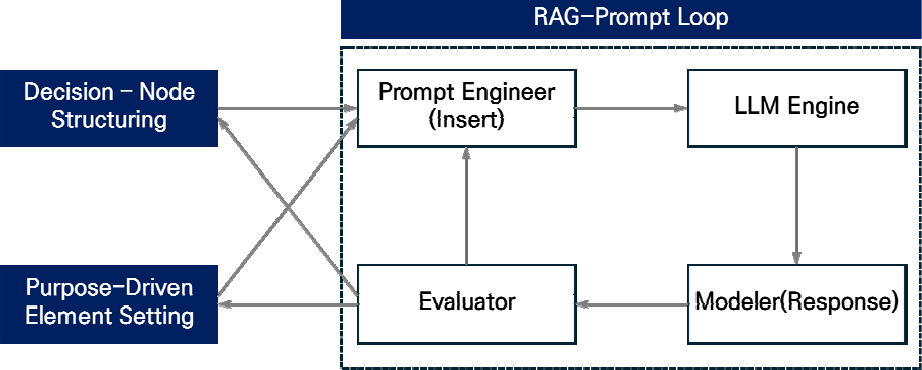
3.3 실험설계
본 연구의 핵심 가설은 “LLM 지원 대화형 피드백이 모델러의 목표 명확화, 오류 탐지의 속도 및 효율성 개선, 모델링 부담감 감소 및 만족도 향상에 도움이 된다는 것이다.
가설 1: LLM-RAG는 대조군 대비 Clarify count를 증가시킴
가설 2: LLM-RAG는 Error-hit Time을 단축하고 Rework cycles를 감소시킴
가설 3: LLM-RAG는 NASA-TLX를 감소시키고 SUS를 증가시킴
따라서 실험 과업은 모델 데이터를 직접 수정하는 행위보다 목표 정교화·오류 요인 규명·성과 검증에 필요한 의사소통 과정을 측정하도록 설계된다.
참여자 및 입력물
- 총 2가지 조건의 실험을 진행하여 성능을 비교한다. 한 가지는 Manual (LLM 지원없이 모델링 작업 진행, M이라 표기), 나머지 한가지는 LLM-RAG (ChatGPT-4o, 4.5, o3, o4-mini 활용)로 구분하여 측정함
- 시나리오: 2개의 시나리오(프로젝트 실행사례 참고) 상 목표, 오류에 대한 정답 Set 포함
- 순서 통제: 1인을 기준으로 통제군 → LLM-RAG수행방식으로 수행(가능 시 반대 순서 1세트 추가). 세션 간 30분 휴게시간 확보)
- 입력물: 과업 요약서 외 과업수행 시 필요문서(유사 프로젝트 사례), 모델 파일은 제공하지 않고 텍스트/표 시나리오만 제시함
지표 정의 및 산출방식
- Clarify count (개): 세션 중 모델러가 추가 설명이나 확인을 위해 LLM에 재질문한 횟수. 낮을수록 피드백이 명확하고 의사소통 효율이 높음을 의미함
- Error-hit Time (분): 세션 시작 후 첫 유효 오류원인 진술까지 경과시간
- Rework cycles (회): 오류-조치-재검토을 반복하는 횟수
- NASA-TLX (0–100): 인지적 부담도 측정
- SUS (0–100): 만족도 측정
분석 방법
- 표본이 작으므로 평균(M)만 제시하고, 대조군 대비 상대 변화율(%)로 개선폭을 해석함. 10% 이상이면 ‘뚜렷한 개선’, 5% 이상 10%이하이면 ‘완만한 개선’으로 기술함
로그 수집 및 데이터 품질 통제
- 프롬프트 및 응답 전문 수집
- 관찰자 메모
- 세션 간 로그 비공개, 시나리오 및 정답셋 고정, 누출 방지
4. 토의 및 시사점
4.1 실험결과의 분석
Table 4는 참가자가 특정 질문에 대해 해결책을 얻지 못했을 때, 문제를 어떻게 인식하고 극복했는지 사례를 정리한 것이다. 각 항목은 ‘질문-오류-피드백’ 구조로 구성되어 있어 부족했던 정보와 개선 방향을 구체적으로 보여준다. 질문의 명확성이 해결책 도출에 큰 영향을 미쳤다. 특히 o3 모델은 다른 모델보다 응답 분량이 길어, 질문이 다소 모호해도 유의미한 해결책을 제시할 수 있었다.
Table 4.
Cases of feedback
수작업(Manual) 방식과 비교하여 네 종류의 LLM-RAG 조건(GPT-4o, 4.5, o3, o4-mini)을 비교하였다(Table 5). LLM-RAG 기반 지원은 모든 오류 완전 탐지에 필요한 총 시간을 대폭 단축해 품질 보증 효율을 높일 수 있을 것으로 기대된다.
Table 5.
Results of test
실험 결과, 모든 LLM-RAG 조건에서 오류 탐지 속도와 인지부하가 크게 개선되었으나 모델별 차이가 관찰되었다. 특히 Clarify count는 세션 중 모델러가 추가 설명이나 확인을 요구한 횟수로 정의되며, 낮을수록 피드백의 명확성이 높아 의사소통 효율이 향상됨을 의미한다. 예를 들어, o3 모델은 응답이 간결하여 재작업 반복이 최소화되었고 Clarify count 역시 낮아 효율적이었다. 반대로 GPT-4o/4.5 모델은 재질문이 증가해 Clarify count가 상대적으로 높게 나타났는데, 이는 효율성 측면에서는 매뉴얼 방식보다 불리할 수 있으나, 다수의 질의를 통해 목표와 오류 요인을 더 세밀하게 규명하는 과정으로 이어졌다는 점에서 ‘목표 정교화’에는 기여했다고 볼 수 있다. 이는 과업의 성격에 따라 “명확성과 효율성” 또는 “목표 정교화” 중 어떤 지표를 우선시할지에 따라 적합한 모델 선택 전략이 달라져야 함을 시사한다.
참가자 인터뷰는 정량 지표를 뒷받침한다. 모델러 A는 “대화를 통해 목표를 한 문단으로 구체화하니 설계 방향을 바로 잡는 데 10분도 걸리지 않았다”고 설명했고, 모델러 B는 “오류 목록이 자동으로 정렬돼 우선순위를 잡기 쉬웠다”고 평가했다.
이러한 결과는 파일 수준의 모델 데이터 없이도 LLM 기반 상호작용만으로 모델링 목표와 오류 요인을 효과적으로 식별·조정할 수 있음을 시사한다(Figure 2).
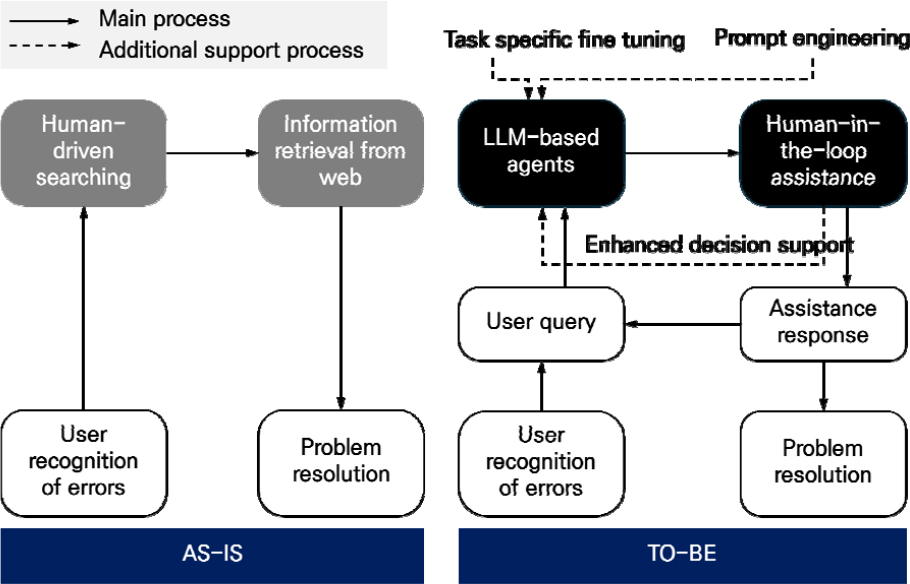
본 연구에서는 기존 AS-IS 프로세스가 사용자가 오류를 직접 인식하고 웹에서 정보를 탐색하여 문제를 해결하는 방식임을 보였다. 반면 TO-BE 프로세스에서는 LLM 기반 에이전트와 Human-in-the-loop 보조가 결합되어, 사용자의 질의에 대한 피드백과 의사결정 지원을 제공함으로써 오류 인식 및 해결 절차의 효율성을 높일 수 있음을 제시하였다. 실선은 주요 흐름을, 점선은 추가적인 지원 과정을 나타낸다. LLM-RAG 기반 지원은 모든 오류 완전 탐지에 필요한 총 시간을 대폭 단축해 품질 보증 효율을 높일 수 있을 것으로 기대된다.
단, 질의응답자 개인적 특성의 차이로 Clarify count와 Rework cycles에서 편차가 발생하므로, 업무 특성에 맞춰 목표 정교화 중시하는 경우에는 ChatGPT-4o/4.5, 재작업 최소화를 중요시하는 경우에 o3계열을 선택하는 전략이 필요하다. 표본 규모가 작기 때문에, 후속 연구에서 참여자특성 분석과 시나리오를 다양하게 확장함으로써 통계적 데이터의 활용가능성을 확보해야 한다.
4.2 MVE 관찰 결과의 시사점
본 연구는 두 명의 BIM 모델러를 대상으로 한 최소 실행 가능 실험(MVE) 을 통해 LLM-RAG 기반 피드백 체계가 다음과 같은 초기 신호를 제공함을 확인하였다.
오류 탐지와 수정 프로세스가 기존 수작업 대비 보다 직관적으로 이루어졌으며, 참여자 모두 “과업 의도 명확화(Clarify)”에 대한 질의내용이 자연스럽게 세분화되는 경향을 보였음을 보고하였다.
재작업 단계에서 동일 오류를 반복할 가능성이 감소하는 경향이 관찰되었고, 이는 LLM이 제시한 우선순위 기반 가이드를 즉시 반영했기 때문으로 해석된다.
두 참여자는 모두 인지적 피로도가 “크게 부담되지 않았다”는 정성 의견을 남겼지만, 구체적 계량 지표는 후속 대규모 연구가 필요하다.
규칙 기반 자동화 스크립트 유지 비용을 대화형 LLM으로 부분 대체할 수 있다는 개념적 가능성을 실험적으로 확인하였다. 텍스트-중심 레퍼런스 + 대화 인터페이스만으로도 BIM 품질관리 단계에서 의미 있는 선제적 오류 예방이 가능함을 시사한다. 토목 인프라 영역에서 LLM 적용 효과를 정성적으로 보고한 사례는 드물어, 본 연구는 선행 탐색 연구로서 가치가 있을 것으로 예상한다.
샘플 수(n = 2) 와 단일 과업 시나리오는 결과 해석 범위를 제한하며, 통계적 검정은 실시하지 않았다. 향후 연구에서는 다양한 프로젝트 유형·숙련도·조직 문화를 포함하여 30 명 이상 규모의 확장 실험이 요구된다. 멀티모달 LLM(텍스트 + 모델 파라미터) 적용 시, 형상·속성·시간 정보를 동시에 처리하는 통합 피드백 루프의 실효성을 검토할 필요가 있다.
4.3 wise-BIM 런타임 구조
Figure 3은 본 연구가 제안한 wise-BIM 프레임워크의 런타임 구조를 계층(layer)과 노드(node)의 이원적 관점으로 압축해 시각화한 것이다. 그림을 구성하는 세 계층(resource, invocation, action)은 데이터가 정적 지식 자원에서 동적 피드백으로 이행되는 추상화 단계를, 세 노드(Node A, B, C)는 해당 단계별로 기능을 집약해 제공하는 실행 단위를 각각 나타낸다. 이를 통해 지식 자원, 프롬프트, 실시간 상호작용이라는 서로 이질적인 요소들이 어떻게 하나의 파이프라인 내에서 연속적으로 연결되는지를 직관적으로 보여 준다.
가장 하위에 위치한 Resource layer는 발주처 가이드라인, ISO 19650-2, 표준 BEP 템플릿, 그리고 오류-조치 사례집과 같은 정적 지식 자원을 저장·관리하는 영역이다. 여기서는 문서 버전 관리와 접근 권한 설정이 핵심 활동으로, 프로젝트 착수 시점에 요구되는 범위·성과물·임계값 정보가 완결된 형태로 보존된다. 상위의 Invocation layer는 이 정적 자원을 실행 가능한 형태로 변환하는 중간 계층으로, 선택된 규정이나 체크리스트에 프로젝트-특화 파라미터(예: 공종, LOD, 공기)를 주입하고 이를 프롬프트 스키마로 직렬화한다. 마지막 Action layer는 모델러와 LLM이 실시간으로 상호작용하면서 오류를 탐지·해결하고, 그 결과를 다시 시스템에 환류하는 활동 지점이다. 이렇게 ‘자원 → 호출 → 행위’의 위계적 흐름을 명시함으로써, BIM 데이터를 둘러싼 추상화 수준의 간극을 해소하고 데이터 거버넌스의 책임 범위를 명료화할 수 있다(Figure 3).
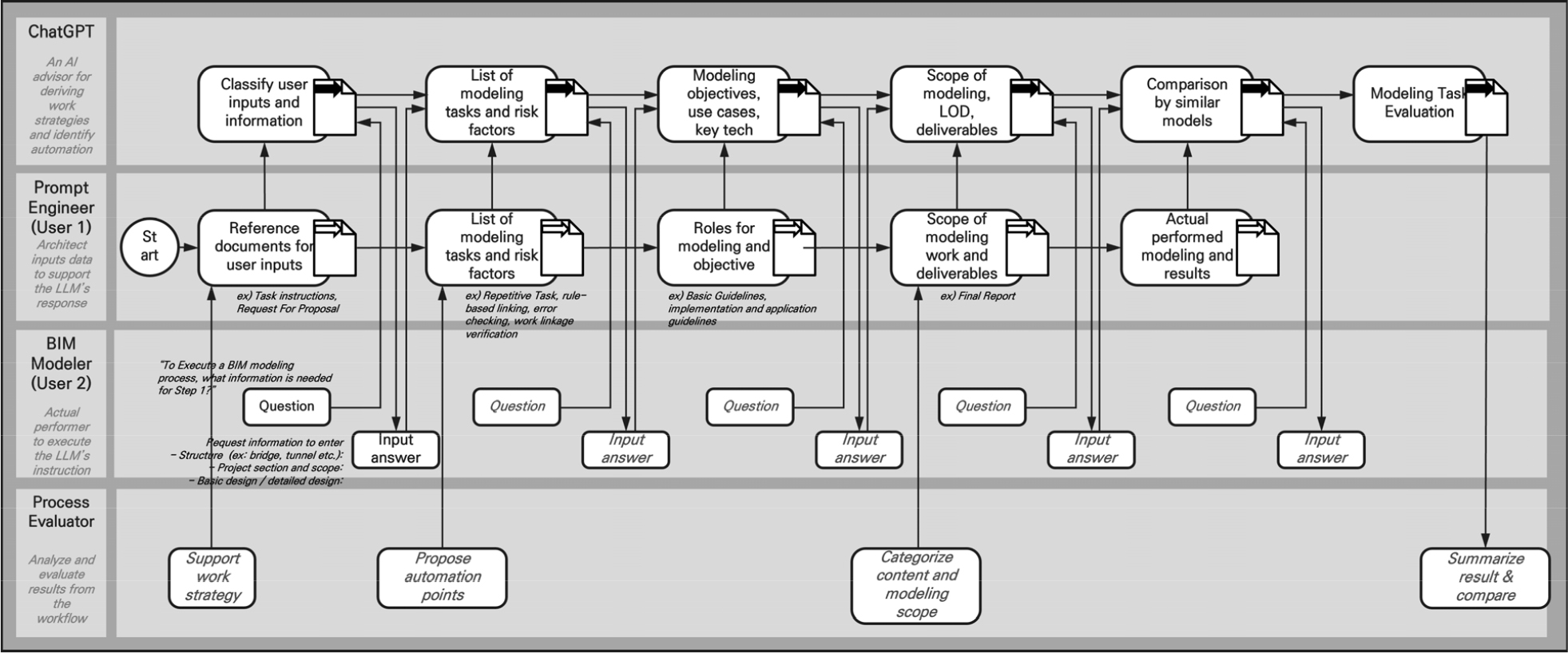
계층적 구조와 함께, 그림은 Node A, B, C라는 기능 단위를 추가로 배치해 프레임워크의 내·외부 인터페이스를 세분화한다. Node A는 발주처 요구사항과 제출물 기준을 수용·정제해 프로젝트 목표, 범위, 성과물 정의를 담당한다. Node B는 오류-조치 리포지토리와 우선순위 규칙을 통해 목표 달성에 필요한 목적 파라미터를 지속적으로 갱신하고, Node C는 프롬프트-응답 로그를 기반으로 LLM-RAG 피드백 루프를 실시간 운영한다. 특히 Node C에서 산출되는 KPI (clarify count, rework cycles, error-hit time 등)는 다시 Node B로 전달되어 규칙 가중치를 조정하고, 필요 시 Node A의 체크리스트 개정으로까지 이어진다. 이러한 하향식(top-down) 규정과 상향식(bottom-up) 학습이 맞물린 순환 구조는 wise-BIM이 단순 규칙 집합이 아닌 자기-강화형(autopoietic) 시스템임을 강조한다.
동작 단계별 과정을 살펴보면 다음과 같다. 프로젝트 착수 단계에서 모델러는 Node A를 통해 발주처 BEP와 설계 지침을 Resource layer에 적재한 뒤, Node B에서 공종(예: PSC 거더 교량)과 목표 LOD (300)를 입력해 우선순위 규칙을 초기화한다. 이때 선택된 문서와 파라미터는 Invocation layer에서 프롬프트 템플릿으로 변환되어 Node C로 전달된다. 이후 Action layer에서 모델러가 “지점부 거더-슬라브 간 간섭 위험이 있는가?”와 같이 질의하면, LLM은 Node A·B 자원을 근거로 즉시 응답을 생성한다. 응답에는 간섭 가능 구간, 근거 규정, 권장 조치가 포함되며, 모델러는 이를 반영해 모델을 수정한다. 세션 종료 시 기록된 KPI는 Node B 규칙 값과 Node A 체크리스트에 피드백되어, 동일 유형 오류의 반복 확률을 낮추는 방향으로 시스템이 자동 적응한다. 이처럼 Figure 3은 정적 규정 관리와 동적 피드백 학습이 단일 파이프라인에서 실시간으로 교차되는 절차를 단계별로 조망하게 해 준다.
Figure 3이 제공하는 학술적 가치는 세 가지로 요약된다. 첫째, 문서·규정·행위가 서로 다른 추상화 레벨에 위치한다는 사실을 계층 구조로 명시함으로써, 기존 연구에서 흔히 간과되던 추상화 격차(abstraction gap) 문제를 해결한다. 둘째, 노드 간 파라미터 흐름과 KPI 환류 메커니즘을 구체적으로 제시해, LLM 기반 BIM 품질관리 프로세스를 재현 가능하고 확장 가능한 형식(extendable formalism)으로 정립한다. 셋째, 로그·KPI·버전 제어 정보를 거버넌스 객체로 정의해 ISO/IEC 42001, EU AI Act 등 AI 책임성 프레임워크와의 정합성을 확보했다는 점에서 산업계 적용 가능성을 높인다. 실무적으로는 BEP 부속서에 Figure 3의 계층·노드 정의를 템플릿 형태로 포함시킴으로써, 프로젝트마다 반복되는 규정 해석·파라미터 매핑·오류 조치 과정을 표준화하고 조직 차원의 지식 내재화를 가속할 수 있다.
결국 Figure 3은 wise-BIM이 단순히 LLM-RAG 기술을 접목한 도구를 넘어, 정책·규정·업무행위 세 축을 통합 관리하는 데이터-거버넌스 프레임워크임을 시각적으로 증명한다. 이와 같은 본 연구의 특징은 소규모 MVE에서 확인된 초기 성과를 대규모 현장으로 이전(lossless transfer)하고, 장기적으로는 멀티모달 LLM 및 온-프레미스(on-premise) RAG 아키텍처를 수용할 확장성을 뒷받침한다는 점에서 의의가 있다.
5. 결 론
본 연구는 대규모 언어모델(LLM)을 내재화한 BIM 모델링 평가·피드백 프레임워크 wise-BIM을 제안하고, 최소 실행 가능 실험(MVE) 형태의 실제 모델링 시나리오에서 그 효과를 검증하였다. 이는 규칙 기반 자동화가 지닌 적응성과 설명력의 한계를 LLM 기반 대화형 피드백이 보완할 수 있음을 보여준다. 다만, 모델별 성능 차이에 따른 적용 전략이 필요하며, 표본 규모 확장을 통한 추후 연구가 요구된다. 본 연구는 BIM 모델링의 품질 관리 및 디지털 전환 전략 수립에 기여할 수 있는 새로운 접근법을 제시하였다.
정적 규정·지식 자원을 RAG 기반 대화형 인터페이스와 결합함으로써, 모델러는 수작업 대비 오류 탐지-조치 소요 시간을 최대 87.5 %까지 단축하고, 주관적 인지 부하를 유의미하게 경감하며, 시스템 사용성에 대한 긍정적 경험을 보고하였다. 이러한 결과는 BIM 품질관리 단계에서 텍스트 중심 LLM 보조 도구만으로도 고질적 오류를 선제 제거할 수 있음을 시사하며, 규칙 기반 자동화 스크립트를 유지·보수하는 기존 접근법의 한계를 보완할 수 있는 새로운 패러다임을 제시하였다.
한편, 실험 과정에서 모델별 특성 차이가 ‘목표 정교화(clarification)’와 ‘재작업 최소화(rework reduction)’ 효과 사이에 트레이드오프를 야기한다는 점이 관찰되었다. 이는 과업의 복잡성, 프로젝트 단계, 모델러의 숙련도 등에 따라 맞춤형 모델 선택 및 하이브리드 운용 전략이 필요함을 의미한다. 또한, 본 연구는 두 명의 모델러와 단일 프로젝트 컨텍스트를 대상으로 한 소규모 탐색 연구이므로, 결과의 일반화에는 신중한 해석이 요구된다. 향후에는 1) 다양한 인프라·건축 유형을 포괄하는 30명 이상 규모의 종단 실험, 2) 3D 형상·속성 정보를 동시에 처리하는 멀티모달 LLM 내재화, 3) 온-프레미스 RAG 아키텍처를 통한 보안·규제 친화적 배포 방안 등을 추가로 검토할 필요가 있다.
실무적으로 wise-BIM은 발주처 BEP, ISO 19650-2, 조직 내부 오류–조치 리포지토리를 단일 파이프라인으로 통합하고, KPI (clarify count, rework cycles 등)를 자동 환류함으로써 데이터 거버넌스·투명성·재현성을 동시에 확보할 수 있다. 특히 Node 기반 구조는 새로운 규정이나 기술적 요구가 발생하더라도 모듈 단위 확장을 가능하게 하므로, 디지털 전환(DX)을 추진 중인 공공·민간 기관에서 신속한 기술 내재화와 장기적 운영 지속성을 뒷받침한다. 나아가 본 연구가 제시한 계층·노드·피드백 모델은 LLM 도입을 고려하는 타 분야(예: 설비, 플랜트, 스마트시티)에도 참고 가능한 범용 프레임워크로 활용될 수 있을 것이다.
