

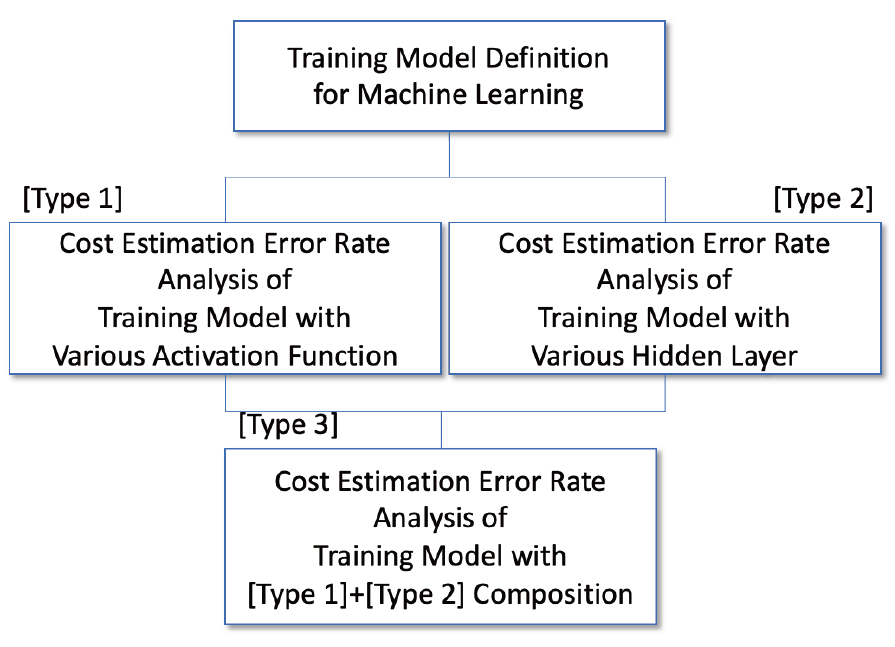
1. 서 론
1.1 연구의 배경 및 목적
1.2 연구의 범위 및 방법
2. 선행연구 및 사례
2.1 선행된 공사비 예측모델 구축사례
2.2 머신러닝 개요
3. 건축 공사비 예측모델의 분석
3.1 활성화함수(activation function)에 따른 예측성능
3.2 은닉층의 학습노드 구성에 따른 예측성능
3.3 활성화함수와 은닉층 노드의 조합에 의한 예측성능
4. 결 론
1. 서 론
1.1 연구의 배경 및 목적
최근 들어, 건축분야에서는 인공지능을 적용한 연구가 활발하게 진행되고 있다. 2017년 기준 국내·외 논문은 총 417편으로, 분야별로 구분하면 건축환경·설비분야, 건축구조분야, 건축재료 분야, 건축시공분야 순으로 머신러닝을 적용한 연구가 활발하게 진행되고 있다. 시공분야를 비롯한 건축구조, 재료 분야에서의 연구는 주로 2000년대 초중반에 집중적으로 연구가 이루어졌으나 그 이후에는 지속적으로 증가하지는 않았다(Kang et al, 2017). 현 시점에서는 건설프로젝트의 대형화에 따라 공사비예측의 중요성이 높아지고 있으며, 이를 머신러닝에 적용한 연구활동의 필요성이 증대되고 있다.
따라서 본 연구에서는 건축 기획·설계 단계에서 11가지 영향요인(제한된 정보)을 통해 공사비를 예측하는 인공지능 모델의 정확성을 높이는 것을 목적으로 하여, 정확성을 높이기 위하여 다양한 활성화함수와 학습노드의 진행을 적용해보고 오차율이 가장 낮은 모델을 선별한다.
1.2 연구의 범위 및 방법
본 연구는 “활성화함수와 학습노드 진행변화에 따른 건축공사비 예측성능 분석“을 위해 국내 일반건물 251개 사례를 이용하여 연구를 진행하였으며, 연구의 범위는 일반건물의 기획단계로 설정하였다. 연구의 구체적인 방법은 아래와 같다.
(1) 기존의 머신러닝을 이용한 공사비 예측모델기반으로 모델구성cell 중 활성화함수를 변경하여 결과값을 정리한다. 활성화함수는 sigmoid, swish, ELU, ReLU. LeakyReLU, tanh로 총 6가지의 경우이며, 이를 [Type 1]으로 정의한다. [Type 1]을 모델구성 cell에 대입하여 결과값을 도출해내고 이 중 오차율이 가장 적은 3가지의 활성화함수를 선정한다.
(2) 기존의 머신러닝을 이용한 공사비 예측모델 기반으로 모델구성 cell 중 node를 변경하여 결과값을 정리한다. hidden layer의 node를 변경하는 경우를 [Type 2]로 정의한다. {Type 2]는 [case 1]과 [case 2]로 나뉘는데, [case 1]은 node가 100으로 시작하는 경우로 7가지, [case 2]는 node가 200으로 시작하는 경우로 6가지로 구성하고, 이에 따른 결과값을 도출해내고, [case 1]과 [case 2]을 합친 모든 경우 중에서 오차율이 가장 적은 3가지의 node진행을 선정하였다. 여기서 [Type 2]의 활성화함수는 ReLU로 선정하여 대입한다.
(3) [Type 1]을 통해 도출된 오차율이 가장 적은 3가지의 활성화함수와 [Type2]에서 도출된 오차율이 가장 적은 3가지의 node진행을 결합하여 총 9가지의 경우를 모델구성 cell에 대입한다. 이러한 구성을 [Type 3]로 정의한다. [Type 3]에서 오차율이 가장 적은 조합을 선정하였다.
2. 선행연구 및 사례
2.1 선행된 공사비 예측모델 구축사례
머신러닝 및 딥러닝을 적용한 건축관련 연구가 활발하게 진행되고 있다.
국내에서 (Kim, 2020)는 머신러닝을 통한 도로공사 환경부하량과 공사비용 추정방법을 비교하였다. 연구에서는 다중회귀분석, 회귀트리, 사례기반추론, ANN, DNN 기법을 적용 후 기획단계와 설계단계에서 환경부하량과 공사비용 추정에 유리한 모델을 을 구축하였다.
(Chun et al, 2019)은 딥러닝 기술을 사용하여 주택가격을 예측하는 데에 우수한 모형을 판별하였다. 연구에서는 국내 전국 아파트의 실거래 가격지수를 종속변수로, CD금리, 가계대출금, 건축허가면적, 소비자물가지수를 독립변수로 선정하여 인공신경망 기술과 빅데이터를 접목한 딥러닝을 이용해 주택가격을 예측하였으며 시계열 예측에 적합한 딥러닝 알고리즘으로 평가받고있는 simple RNN, LSTM(Long Short Term Memory Network)과 GRUGated Recurrent Unit) 모형에 시계열 자료를 적용하여 각 모형들 간의 예측력을 비교 및 평가하고 예측력이 우수한 모형을 판별하였다.
(Son et al, 2006)은 인공신경망에 실적자료를 적용하여 교육시설 프로젝트의 개념단계에서 공사비 예측이 가능한 모델을 을 구축하였다.
(Pham et al, 2021)은 ML회귀 알고리즘 중 인공신경망(ANN), 그라데이션 부스팅 및 XGBoost을 통해 최적화된 공사비를 예측할 수 있는 모델을 구축하였는데, 건축비용과 자재비용을 추정할 수 있도록 13개의 ML 회귀 알고리즘 중 인공신경망(ANN), 그라데이션 부스팅 및 XGBoost 모델을 구축하였다.
(Muizz O et al, 2021)는 고층빌딩 프로젝트의 예비비용을 추정할 수 있는 모델을 구축하였다. 연구에서는 다중 선형 회귀 분석(MLRA), k-Nearest Nighbors(KNN), 인공 신경망(ANN), 지원 벡터 머신(SVM) 및 다중 분류기 시스템을 통해 표준성능지표를 사용하여 고층빌딩 프로젝트의 예비비용을 추정하는 12개의 모델을 구축하였다.
(Kaur et al, 2020)은 30년동안 머신러닝 기법을 통한 비용추정을 위해 수집된 데이터를 기반으로 건설공사의 직접원가와 간접원가에 따른 비용추계에 분석방법론을 적용하였다.기존 연구들은 공사비 예측성능을 향상시키기 위해 새로운 머신러닝 기법들을 적용하고자 하였다. 즉, 기법의 단위에서 공사비예측모델을 구성하였기 때문에 큰 단위로 연구하였다고 볼 수 있다. 이들 연구에서는 세부적인 학습모델의 구성에 따른 예측성능의 차이에 대한 분석은 다소 부족하였다.
본 연구에서는 최신의 딥러닝 학습모델을 기반으로, 학습모델을 구성하는 은닉층과 출력층의 구성에 따른 예측성능의 차이를 분석하고자 한다.
2.2 머신러닝 개요
2.2.1 머신러닝의 정의 및 특성
머신러닝(machine learning)이란, 일반적으로는 애플리케이션을 수정하지 않고도 데이터를 기반을 패턴을 학습하고 결과를 예측하는 알고리즘 기법을 통칭한다.(위키북스, 파이썬머신러닝완벽 가이드, 권철민 지음, p.1-2) 즉, 기계(컴퓨터 알고리즘)스스로 데이터를 학습하여 서로 다른 변수 간의 관계를 찾아 나가는 과정이라고 정의할 수 있다. 해결하려는 문제에 따라 예측(prediction), 분류(classification), 군집(clustering) 알고리즘 등으로 분류된다.
머신러닝은 크게 두 가지 유형으로 분류할 수 있다. 즉, 정답 데이터를 다른 데이터와 함께 컴퓨터 알고리즘에 입력하는 방식의 지도학습(supervised learning)과 정답 데이터 없이 컴퓨터 알고리즘 스스로 데이터로부터 숨은 패턴을 찾아내는 방식의 비지도학습(unsupervised learning)으로 분류할 수 있다.
본 연구에서는, 공공건설공사의 설계정보와 공사내역서의 공사비 정보를 활용하여, 지도학습의 형태로 머신러닝기반의 공사비를 예측해보고자 한다.
본 연구에서는 머신러닝을 적용하여 ‘model 구성’ cell을 구성하고 있는 은닉층과 출력층의 활성화함수의 경우를 8가지, node진행의 경우를 총 13가지로 나누어 대입해보고 경우별로 loss값과 mae값을 정리한다. 최종적으로 loss값과 mae값을 통해 도출되는 오차율이 가장 적은 경우를 선별하는 것이 본 연구의 목적이다.
2.2.2 활성화함수
활성화함수는 입력값들의 수학적 선형 결합을 다양한 형태의 비선형(또는 선형) 결합으로 변환하는 역할을 하는 함수를 말한다. 인공신경망이 복잡한 문제를 잘 설명하는데 활성화함수를 이용한 비선형 변환이 상당히 중요한 역할을 한다고 볼 수 있다. 실제로 어떤 활성화함수를 적용하는지에 따라 딥러닝의 예측력에 상당한 차이가 발생한다(파이썬 딥러닝 머신러닝 입문, 정보문화사, 오승환). 본 논문에 비교분석하기 위해 적용할 활성화함수는 총 6가지로 sigmoid, swish, ELU, ReLU, LeakyReLU, tanh가 있다.
sigmoid함수는 [0, 1]의 범위를 가지는 단조롭고 감소하지 않는 비선형 함수이이며, swish함수는 큰 음수값이 입력되면 출력이 0이 되어 미분 값이 포화되지만, 작은 음수값이 입력되면 들어온 값을 어느 정도 보존한다(Kim et al, 2020). ELU함수는 입력값이 0보다 큰 경우 ReLU함수의 식과 같으며, 입력값이 0보자 작은 경우 α에 지수함수를 곱하여 활성화함수의 출력값을 정한다. ELU 함수는 입력값이 0보다 작은 경우 활성화함수값이 0이 아니라는 점에서 LeakyReLU 함수와 유사하지만 지수함수를 사용함으로써 활성화함수값이 비선형이라는 점에서 Leaky ReLU 함수와 차이가 있다(Shin et al, 2021).
ReLU함수는 입력값이 0보다 작으면 0의 값을, 입력값이 0보다 크면 입력값과 동일한 값을 출력하는 활성화함수이다. 입력값이 0보다 큰 경우 기울기가 1로 일정하다(Shin et al, 2021). LeakyReLU함수는 입력값이 0보다 큰 경우 ReLU 함수와 동일한 결과를 출력하며, 입력값이 0보다 작으면 기울기인 α에 입력값을 곱하여 활성화함수의 출력값을 결정한다(Shin et al, 2021). 그리고, tanh 함수는 [-1, 1]의 범위를 가지며 sigmoid 함수와 유사한 곡선의 형태를 나타낸다.
머신러닝의 학습에는 이들 활성화함수의 역할이 매우 큰 비중을 차지한다. 본 연구에서는 공사비 예측에 있어서 이들 활성화함수의 적용성을 분석하고자 한다.
3. 건축 공사비 예측모델의 분석
본 연구는 건축공사비 예측모델의 정확도를 높이기 위해서 첫째로 활성화함수를 변경하여 정확도를 비교하고, 둘째로 학습노드의 진행을 변경하여 정확도를 비교하고자 한다. 그리고, 첫 번째 과정과 두 번째 과정을 통해서 도출해낸 정확도 높은 경우를 종합하여 최종적으로 정확도가 가장 높은 모델을 도출해내고자 한다.
공사비 예측을 위한 머신러닝 학습모델을 개발하기 위하여 본 연구에서는 Visual Studio Code 개발환경에서 Keras 라이브러리를 사용하였다. 또한, 공사비 예측에 사용된 데이터는 2017년부터 2019년까지 공공건축분야에서 발주한 3년간의 데이터이며, 이들 중 공사비 학습에 필요한 충분한 데이터를 확보하고 있다고 판단되는 251개의 데이터를 선별하여 사용하였다. 공사비예측을 위해서는 공사비에 영향을 주는 영향요인들을 정의할 필요가 있는데, 본 연구에서는 건축물의 규모와 특성을 정의할 수 있는 11가지 영향요인을 결정하였다. 이들 영향요인은 건축설계도서에서 건축개요에 정의되어 있는 정보들을 주로 사용하였는데, 이들 영향요인을 나열해보면 공사유형, 연면적, 건축면적. 최고 높이, 최대 지상 층수, 최대 지하 층수, 대지면적, 조경면적, 기준층 층고, 주차대수, 공사연도 등 11가지이다.
본 연구에서는 공사비 예측을 위한 학습모델을 활성화 함수와 학습노드를 다양한 형태로 구성하여 정의하였다. 본 연구에서는 이들 학습모델 조합들에 대한 공사비 예측성능을 분석하여, 공사비 예측 성능이 가장 좋은 형태의 학습모델을 찾고자 한다.
3.1 활성화함수(activation function)에 따른 예측성능
여기서는 공사비 예측 학습모델에서 활성화 함수에 따른 예측성능의 변화를 살펴보고자 한다. 학습노드는 [100→64→32→1]으로 구성하고, 반복 횟수(에포크:Epochs)는 1000으로 설정하여 1000번의 학습을 진행하였다.
우선, 머신러닝에 많이 활용되는 sigmoid함수를 활성화함수로 사용하였는데, sigmoid 함수는 주로 분류(classification)이나 인식(identification)용도로 사용되는 함수이다. 적용해본 결과, sigmoid함수의 경우 선형회귀 형태의 공사비 예측에는 적합하지 않은 것으로 판단된다. 학습결과, loss(손실값)는 146763928.00, mae(평균절대오차)는 7951.72으로 오차율은 96.73%로 크게 나타나는 것을 볼 수 있다. 다음으로, 선형회귀 형태의 머신러닝에 많이 활용되는 ReLU함수를 적용한 결과는 다음과 같다.
Table 1.
Result of ReLU activation function
| Case | Activation function | Results |
| 1-4 | ReLU |
- loss : 662734.0000 - mae : 483.2700 |
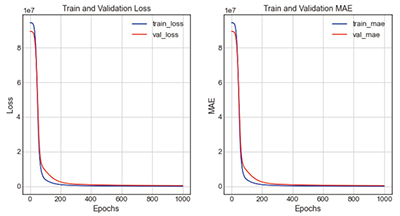 | ||
Table 1에서 보는 바와 같이, 선형회귀에 적합한 ReLU함수를 적용한 결과, 공사비 예측에 적합한 수준으로 학습되는 것을 알 수 있다. 학습결과, loss는 662734.00, mae는 483.27으로 오차율은 16.56%로 도출되었다.
ReLU함수의 음수영역을 보완한 LeakyReLU활성화 함수를 사용한 결과는 다음과 같다.
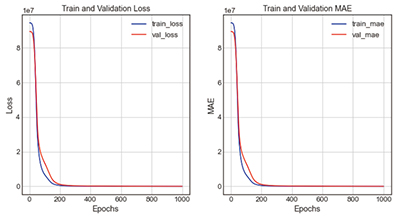
Table 2에서 보는 바와 같이, ReLU와 유사한 학습성능을 보이지만, ReLU에 비해 예측성능이 약간 향상된 것을 볼 수 있다. 학습 결과, loss는 137427.25, mae는 223.83으로 오차율은 8.79%로 도출되었다.
Table 2.
Result of LeakyReLU activation function
| Case | Activation function | Results |
| 1-5 | LeakyReLU |
- loss : 137427.2500 - mae : 223.8260 |
 | ||
다음으로, 최근들어 선형회귀 형태의 머신러닝에 많이 활용되는 swish함수를 적용한 결과는 다음과 같다.
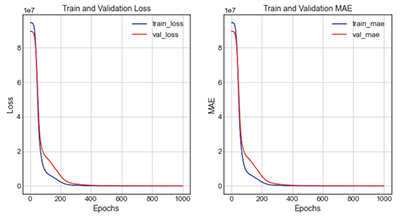
Table 3에서 보는 것처럼, swish함수는 ReLU보다는 예측성능이 다소 향상되는 것을 보이지만, 선형에 보다 가까운 LeackReLU보다는 예측성능이 낮게 나타나는 것을 볼 수 있다. 학습결과, loss는 449178.59, mae는 333.82로 오차율은 11.61%로 도출되었다.
Table 3.
Result of swish activation function
| Case | Activation function | Results |
| 1-2 | swish |
- loss : 449178.5938 - mae : 333.8196 |
 | ||
마지막으로, ReLU와 유사한 형태를 보이는 ELU함수를 활성화함수로 적용해보았다. 적용한 결과, 학습성능은 ReLU나 swish함수와 비슷한 결과를 보여주었다. ELU는 선형이 아니라 지수에 의한 곡선을 이용하는 것이 특징인데, 여기서는 swish함수를 적용한 경우 보다 향상된 학습성능을 보여주었다. 학습결과, loss는 40895.71, mae는 101.70으로 오차율은 3.12%로 도출되었다.
활성화함수에 대한 6가지 Case의 정확도 결과는 Table 4와 같다. 활성화함수로 ELU를 적용한 case 1-3이 오차율 3.12%로 정확도가 가장 높았고, 그 다음으로 오차율이 8.79%인 LeakyReLU, 오차율이 11.61%인 sigmoid 순으로 정확도가 높았다.
Table 4.
Error rates by activation function
| Case | Activation function | Error rate |
| 1-1 | sigmoid | 96.3% |
| 1-2 | swish | 11.61% |
| 1-3 | ELU | 3.12% |
| 1-4 | ReLU | 16.56% |
| 1-5 | LeakyReLU | 8.79% |
| 1-6 | tanh | 94.82% |
3.2 은닉층의 학습노드 구성에 따른 예측성능
다음으로, 학습노드에 따른 예측성능을 분석해보고자 하였다. 학습노드를 구성할 때, 모델의 모든 조건은 동일하게 하되, 학습노드의 구성만 변경하여 적용해보았다. 활성화함수는 ReLU로 하였으며, 훈련세트(에포크:Epochs)는 1000으로 설정하여 1000번의 학습과정을 거치도록 하였다.
학습모델의 은칙층은 4개의 레벨로 구성하고, 은닉층의 구성에 따라 100으로 시작하는 경우를 [Type 1]로 정의하고 200으로 시작하는 경우를 [Type 2]로 정의하였다. 그리고는, 그 하위 은닉층의 구성을 다양하게 구성하여 은닉층의 노드의 수에 따른 예측성능을 분석해보고자 하였다. 이렇게 구성된 13가지의 모델 구성은 Table 5과 같다.
Table 5.
Model configuration of cases
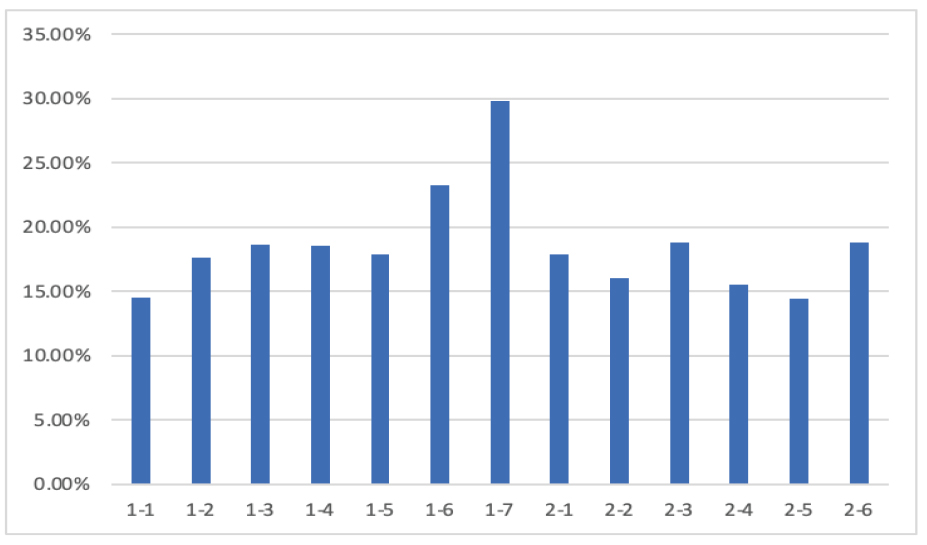
Figure 2는 은닉층의 구성에 따른 13가지 Case에 대한 학습성능 결과를 보여주고 있다. 가장 정확도가 높은 모델은 Case 2-5, 1-1, 2-4의 순서대로 정확도가 높은 것으로 나타나는 것을 볼 수 있는데, 기본적으로 Type 2의 경우가 Type 1보다 정확도가 높게 나타나는 것을 볼 수 있으며, 노드의 수가 일정하게 구성되는 것보다는 점차적으로 노드의 수를 줄여가면서 구성한 모델의 학습성능이 높게 나타나는 것을 볼 수 있다.
정확도가 높게 나타난 3가지 모델의 학습성능 결과는 Table 6과 같다.
Table 6.
3 case graphs with high accuracy
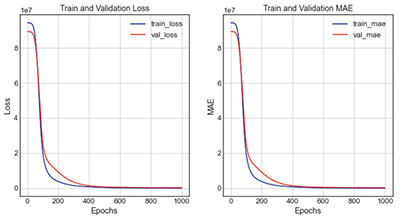
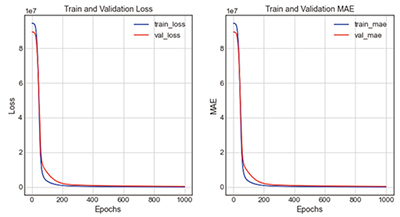
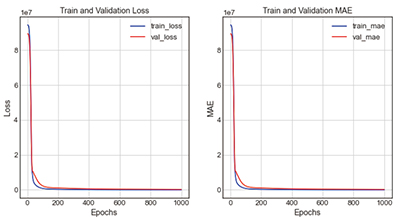
그래프의 전체적인 형태는 비슷하나, 오차율이 14.54%로 가장 정확도가 높은 case 2-5는 loss그래프와 mae그래프 모두 train과 validation이 Epoch 200회에서 300회 사이에 붙는 것을 볼 수 있으며, 이때가 가장 학습성능이 높은 시점으로 판단된다. 2개의 그래프가 근접하는 위치가 학습성능과 검증성능이 동일한 시점으로 가장 예측성능이 높은 것으로 볼 수 있기 때문이다. 그 외에 오차율이 17.59%로 정확도가 두 번째로 높은 case 1-1는 train과 validation이 Epoch 300회에서 400회 사이일 때 근접하는 것을 볼 수 있다.
앞의 분석결과를 통해 학습노드 진행에 따른 loss그래프와 mae그래프의 진행양상을 분석하자면, [Type 1]에서는 학습노드의 진행이 고르게 분포되어 점차적으로 좁아질 경우에 가장 오차율이 적었지만, [Type 2]의 경우에는 학습노드의 진행분포가 급격하게 좁았을 때 가장 오차율이 적었다. 특히, case 2-5의 경우는 loss그래프와 mae그래프의 train과 validation값이 Epoch 100회에서 300회 사이에서 급격하게 벌어졌지만, 400회 이후에 접하는 양상을 보여 가장 학습노드 진행을 바꾼 경우 중 가장 오차율이 적은 case라고 볼 수 있다.
3.3 활성화함수와 은닉층 노드의 조합에 의한 예측성능
앞에서는 활성화함수와 학습노드에 따른 예측성능을 개별적으로 분석해보았으며, 여기서는 활성화함수와 은닉층 노드의 구성을 조합하는 경우의 예측성능을 분석해보고자 한다. 즉, 모델의 모든 조건은 동일하게 하되, 활성화함수와 학습노드만을 다르게 모델을 구성하고자 한다. 활성화함수는 ELU, LeakyReLU, swish로 한정하였고, 은닉층의 구성은 가장 성능이 좋았던 case 2-5, case1-1, case2-4만을 대상으로 하였다. 훈련세트(에포크:Epochs)로 정의되는 총 에포크는 1000으로 설정하여 1000번의 학습과정을 거치도록 하였다.
이러한 구성을 [Type 3]로 정의하고, [Type 3]의 각 Case 구성은 Table 7과 같다.
Table 7.
Cases of activation function and hidden layer[Type 3]
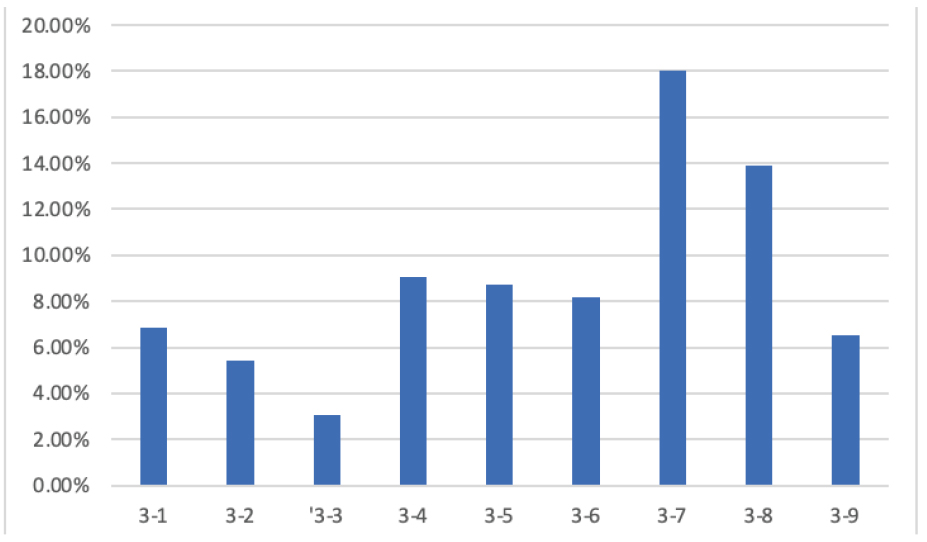
Table 8의 ELU + case2-5는 활성화함수를 ELU, 은닉층을 200 → 20 → 10 → 1로 구성하여 학습한 결과이다. 그 결과 loss는 237538.5, mae는 233.38, 오차율은 6.86%로 도출되었다. 그래프의 전체적인 형태를 보면, 활성화함수 ELU의 전체적인 흐름은 비슷하나 학습노드 진행 분포가 급격하게 좁아지는 양상에 따라 loss그래프와 mae그래프의 train과 validation값이 Epoch 100회에서 500회 사이에 급격하게 벌어졌다가 점차 좁혀지는 것을 볼 수 있다. 이는 활성화함수 ELU에 따른 진행특징과 학습노드 진행 200→20→10→1의 특징이 모두 반영된 결과라고 볼 수 있다.
Table 8.
Result of “ELU + case 2-5”
| Case | Activation function | Learning node progression | Results |
| 3-1 | ELU | 200 → 20 → 10 → 1 |
- loss : 237538.5000 - mae : 233.3777 |
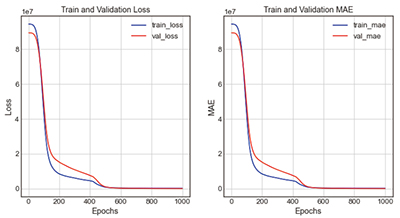 | |||
Table 9 ELU + case 2-1는 활성화함수를 ELU로, 학습노드 진행을 100 → 64 → 32 → 1로 적용한 것이다. 그 결과 loss는 237067.3281, mae는 205.9805으로 오차율은 5.4%로 도출되었다. 그래프의 전체적인 개형은 ELU 활성화함수를 적용했을 때와 동일하게 나타나고 있다.
Table 9.
Result of “ELU + case 1-1”
| Case | Activation function | Learning node progression | Results |
| 3-2 | ELU | 100 → 64 → 32 → 1 |
- loss : 237067.3281 - mae : 205.9805 |
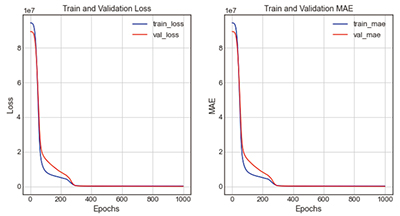 | |||
Table 10 ELU + case2-4은 활성화함수를 ELU, 은닉층을 200 → 180 → 160 → 1로 구성한 것이다. 그 결과 loss는 73595.69, mae는 127.32, 오차율은 3.07%로 도출되었다. 그래프의 전체적인 개형을 분석하면, loss그래프와 mae그래프의 train과 validation값이 Epoch 100회와 200회 사이에서 근접하는 것을 볼 수 있다.
Table 10.
Result of “ELU + case 2-4”
| Case | Activation function | Learning node progression | Results |
| 3-3 | ELU | 200 → 180 → 160 → 1 |
- loss : 73595.6875 - mae : 127.3226 |
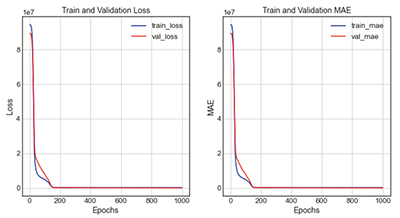 | |||
Table 11의 LeakyReLU + case2-5는 활성화함수를 LeakyReLU로, 은닉층을 200 → 20 → 10 → 1로 구성한 모델이다. 그 결과 loss는 87543.67, mae는 185.10, 오차율은 9.04%로 도출되었다. 그래프의 전체적이 개형은 loss그래프와 mae그래프의 train과 validation값이 Epoch 200회에서 400회 사이에 근접하는 것을 볼 수 있다.
Table 11.
Result of “LeakyReLU + case 2-5”
| Case | Activation function | Learning node progression | Results |
| 3-4 | LeakyReLU | 200 → 20 → 10 → 1 |
- loss : 87543.6719 - mae : 185.1029 |
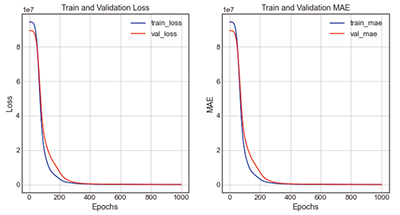 | |||
Table 12의 LeakyReLU + case1-1은 활성화함수를 LeakyReLU로, 은닉층을 100 → 64 → 32 → 1로 구성한 모델이다. 이 모델을 학습한 결과 loss는 181463.56, mae는 221.72, 오차율은 8.72%로 도출되었다. 그래프의 전체적인 개형은 loss그래프와 mae그래프의 train과 validation값이 0회에서 200회 사이에 급격하게 감소하여 Epoch 200회에서 300회 사이에 근접하는 것을 볼 수 있다.
Table 12.
Result of “LeakyReLU + case 1-1”
| Case | Activation function | Learning node progression | Results |
| 3-5 | LeakyReLU | 100 → 64 → 32 → 1 |
- loss : 181463.5625 - mae : 221.7239 |
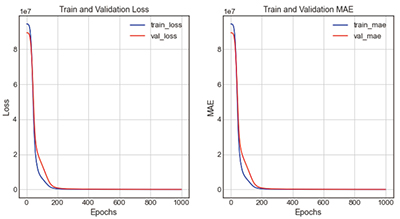 | |||
Table 13의 LeakyReLU + case2-4는 활성화함수를 LeakyReLU, 은닉층을 200 → 180 → 160 → 1로 구성한 모델이다. 모델의 학습 결과 loss는 227011.80, mae는 231.62, 오차율은 8.18%로 도출되었다. 그래프의 전체적인 형태는 loss그래프와 mae그래프의 train과 validation값이 0회에서 100회 사이에 급격하게 감소하여 Epoch 100회에서 200회 사이에 근접하는 것을 볼 수 있다.
Table 13.
Result of “LeakyReLU + case 2-4”
| Case | Activation function | Learning node progression | Results |
| 3-6 | LeakyReLU | 200 → 180 → 160 → 1 |
- loss : 227011.7969 - mae : 231.6230 |
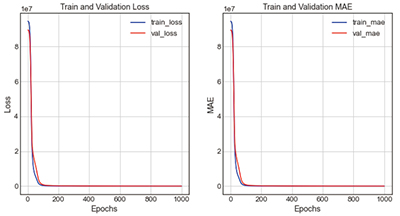 | |||
Table 14의 swish + case2-5는 활성화함수로 swish, 은닉층을 200 → 20 → 10 → 1로 구성한 모델이다. 모델의 학습결과 loss는 8783425.00, mae는 837.21, 오차율은 18.01%로 도출되었다. 그래프의 전체적인 형태는 loss그래프와 mae그래프의 train과 validation값이 Epoch 0회에서 400회 사이에 차이를 보이다가 400회 이후에 점차 근접하는 양상을 보인다.
Table 14.
Result of “swish + case 2-5”
| Case | Activation function | Learning node progression | Results |
| 3-7 | swish | 200 → 20 → 10 → 1 |
- loss : 8783425.0000 - mae : 837.2119 |
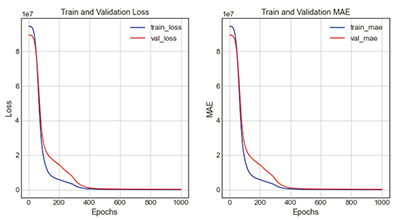 | |||
Table 15의. swish + case2-1은 활성화함수로 swish, 은닉층을 100 → 64 → 32 → 1로 구성한 모델이다. 모델의 학습 결과, loss는 1525847.63, mae는 500.19로 오차율은 13.9%로 도출되었다. 그래프의 전체적인 개형은 loss그래프와 mae그래프의 train과 validation값이 Epoch 0회에서 300회 사이에 차이를 보이다가 300회 이후에 점차 근접하는 양상을 보인다.
Table 15.
Result of “swish + case 1-1”
| Case | Activation function | Learning node progression | Results |
| 3-8 | swish | 100 → 64 → 32 → 1 |
- loss : 1525847.6250 - mae : 500.1869 |
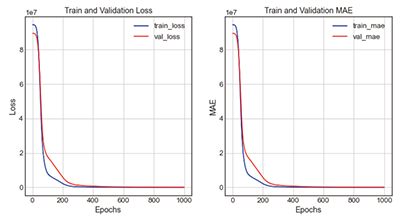 | |||
Table 16의 swish + case2-11은 활성화함수로 swish, 은닉층을 200 → 180 → 160 → 1로 구성한 모델이다. 모델의 학습 결과 loss는 641718.63 mae는 285.81로 오차율은 6.5%로 도출되었다. 그래프의 전체적인 형태는 loss그래프와 mae그래프의 train과 validation값이 Epoch 0회에서 100회 후반 사이에서 차이를 보이다가 200회 이후에 근접하는 양상을 보인다.
Table 16.
Result of “swish + case 2-4”
| Case | Activation function | Learning node progression | Results |
| 3-9 | swish | 200 → 180 → 160 → 1 |
- loss : 641718.6250 - mae : 285.8078 |
 | |||
이들 9가지 Case의 학습결과 오차율은 Figure 3과 같다.
4. 결 론
본 연구는 머신러닝을 이용하여 공사비를 예측하는 모델을 분석하고, 모델구성 cell에서 활성화함수와 학습모델을 구성하는 은닉층을 다양한 조합으로 분류, 적용하여 활성화함수와 학습모델에 따른 예측 성능을 분석하고자 하였다. 활성화함수의 경우 sigmoid, swish, ELU, ReLU, LeakyReLU, tanh를 적용해보았고, 학습노드 진행의 경우 100~, 200~으로 나누어 총 13가지 경우를 적용해보았다. 이를 통해 가장 오차율이 적은 모델은 활성화함수를 ELU로, 은닉층의 구성은 200 → 180 → 160 → 1를 적용한 모델이었다.
본 연구를 통해 도출된 결과는 다음과 같다.
첫째, 활성화함수는 학습모델의 예측성능을 좌우할 수 있는 매우 중요한 요소이다. 공사비 예측과 같은 선형 예측의 경우, 활성화 함수의 종류가 많지 않은 것으로 보인다. 데이터의 종류와 적용 대상에 따라 활성화함수는 예측성능에 영향을 줄 수 있는 것으로 판단된다. 하지만, 활성화함수에 따른 예측성능의 차이도 나타나기는 하겠지만, 머신러닝의 경우에는 학습데이터의 수가 예측성능에 가장 중요한 요소라고 할 수 있다.
둘째, 학습모델을 구성하는 은닉층의 구성에 따라 학습성능과 예측성능에 영향을 줄 수 있는 것으로 보인다. 하지만, 은닉층의 구성은 매우 다양한 조합의 가능성이 있어, 어떤 조합이 공사비 예측에 가장 적합한 것인지에 대한 정답을 제시하는 데에는 한계가 있다. 다만, 은닉층을 구성하는 노드의 수를 늘리는 경우, 적은 횟수(Epoch)만으로도 최적의 결과를 도출하는 것을 볼 수 있다.
공사비 예측의 경우, 공사비 데이터의 확보가 가장 중요한 요소이다. 하지만, 공사비 데이터의 경우, 데이터를확보하는 데 어려움이 있을 뿐만 아니라, 1년에 수집할 수 있는 데이터의 수도 제한적이어서, 적은 학습데이터만으로 최적의 예측성능을 도출할 수 있는 학습모델의 구성이 필요할 것으로 판단된다.
